AI đang ngày càng trở nên quan trọng đối với nhiều lĩnh vực kinh doanh, từ dịch vụ khách hàng cho đến công nghệ tự động hóa. Tuy nhiên, triển khai AI trong các ứng dụng thực tế lại không hề đơn giản. Các vấn đề về hiệu năng, tính tương thích giữa các framework khác nhau hoặc độ trễ trong việc ra quyết định có thể giết chết một dự án AI trước khi nó ra đời.
Để giải quyết những thách thức này, NVIDIA đã cho ra mắt nền tảng Suy luận AI toàn diện bao gồm một loạt sản phẩm và dịch vụ để hỗ trợ các công ty xây dựng các ứng dụng AI tiên tiến, từ các mô hình DNN đến những người trợ giúp ảo dựa trên LLM.
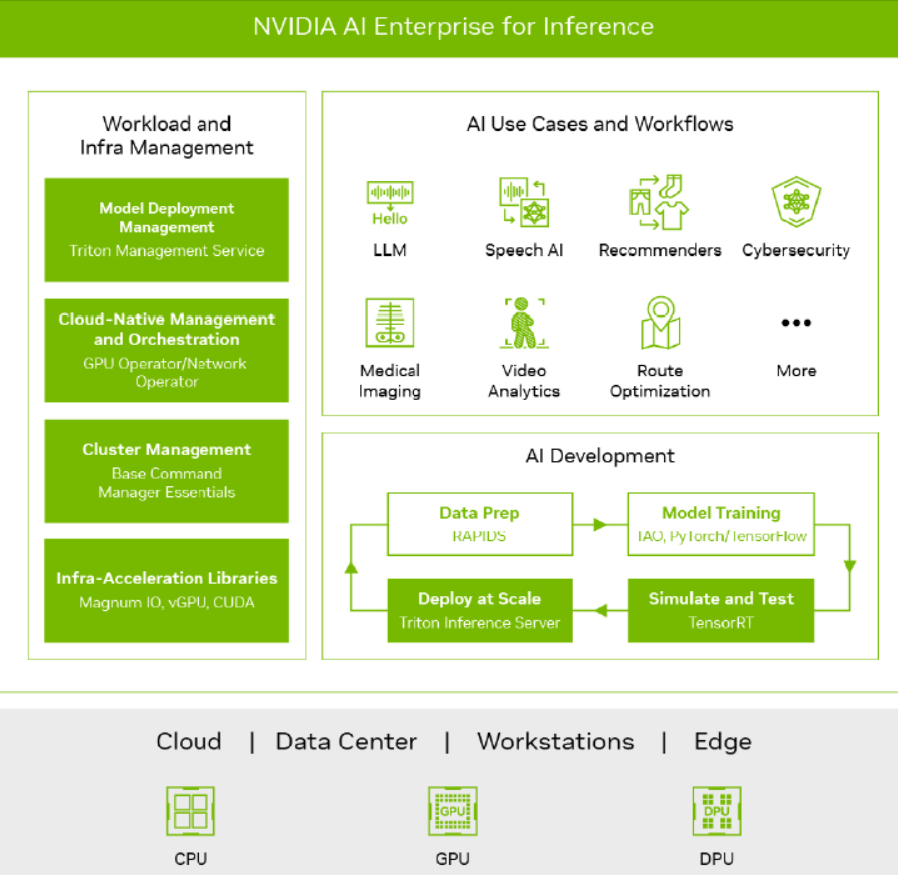
Nền tảng này bao gồm giải pháp TensorRT, một SDK dành riêng cho tối ưu hóa hiệu năng học sâu suy luận. TensorRT tích hợp sẵn thuật toán nén lượng tử INT8 và FP16 giúp các ứng dụng AI chạy nhanh hơn, đồng thời cung cấp các tính năng như hợp nhất tensor, tối ưu hóa kernel và hơn thế nữa. Nó hoạt động trên nền CUDA để sử dụng hiệu quả sức mạnh song song của GPU, với hỗ trợ tích hợp cho các framework phổ biến như PyTorch và TensorFlow.


Cụ thể, giải pháp TensorRT của NVIDIA cung cấp các công cụ để tối ưu hoá các mô hình deep learning cả về hiệu năng lẫn tài nguyên, trong khi TensorRT-LLM mở rộng công nghệ này cho cả các mô hình ngôn ngữ lớn đang nổi lên như DALL-E hay GPT-3.
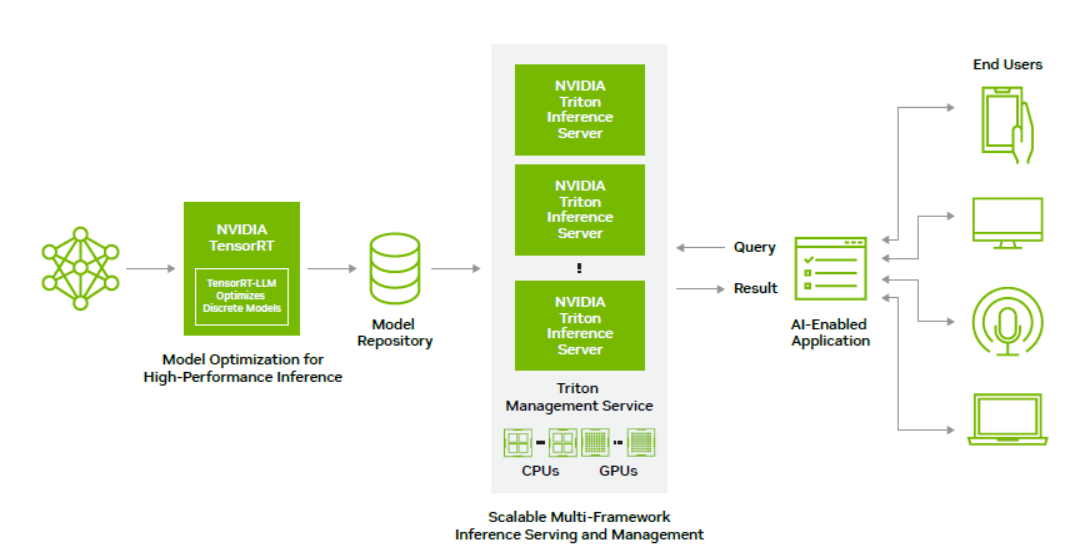
Trình máy chủ suy luận Triton Inference Server giúp khắc phục một trong các khó khăn lớn nhất khi triển khai AI vào sản xuất đó là tính không tương thích giữa các framework lập trình.
Triton server có khả năng phục vụ các mô hình AI từ TensorFlow, PyTorch hay các framework khác mà không cần quan tâm framework nào được sử dụng để huấn luyện chúng – tất cả đều được chạy nhanh chóng với hiệu năng cao nhờ được tối ưu hoá bằng công nghệ của TensorRT.
Bên cạnh đó là thư viện mã nguồn mở TensorRT-LLM, được thiết kế đặc biệt để tăng tốc và tối ưu hóa các mô hình ngôn ngữ lớn như BERT, GPT-3 hay DALL-E trên GPU NVIDIA. Nó cho phép lập trình viên định nghĩa, tối ưu hóa và triển khai các LLM nhanh chóng mà không cần có kiến thức chuyên sâu về C++ hay CUDA.

Trái tim của nền tảng là Triton Inference Server, phần mềm mã nguồn mở dùng để phục vụ suy luận AI. Triton giúp triển khai và thực thi các mô hình từ mọi framework trên bất kỳ cơ sở hạ tầng CPU hoặc GPU nào. Nó đảm bảo hiệu năng và hiệu quả cao thông qua xử lý theo batch, đa luồng và khả năng mở rộng sang nhiều GPU, nhiều node. Mọi thứ từ video streaming, gợi ý sản phẩm cho đến xử lý ngôn ngữ tự nhiên đều có thể được gia tốc đáng kể nhờ Triton.
Cuối cùng, các sản phẩm phần cứng GPU và hệ thống như A100, H100, DGX hay DGX SuperPOD cung cấp nền tảng vật lý hoàn hảo để phát huy sức mạnh tối đa của nền tảng suy luận AI này. Chúng được thiết kế chuyên biệt cho các tải công việc AI, hỗ trợ mở rộng dễ dàng lên hàng trăm GPU cho các hệ thống AI khổng lồ.
Mong rằng với những thông tin này, bài viết đã cung cấp cho bạn một cái nhìn đầy đủ và chi tiết hơn về nền tảng suy luận AI của NVIDIA.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent