
Deep Learning là một lĩnh vực có các yêu cầu xử lý đặc biệt và việc lựa chọn GPU của bạn sẽ quyết định rất lớn đến quá trình triển khai. Vậy những yếu tố nào là quan trọng khi bạn quyết định mua GPU mới cho mục đích Deep Learning? RAM, GPU, Core, Tensor Core? Lựa chọn như thế nào để hiệu quả nhất về chi phí đầu tư? Bài này sẽ đi sâu vào những câu hỏi và sẽ cho bạn lời khuyên giúp bạn đưa ra lựa chọn phù hợp.
Việc có trong tay GPU chạy nhanh là một yếu tố rất quan trọng khi bắt đầu dự án Deep Learning vì điều này cho phép đạt được kết quả nhanh chóng theo kinh nghiệm thực tế, đó là chìa khóa để xây dựng chuyên môn mà bạn sẽ có thể áp dụng Deep Learning vào các vấn đề mới. Thiếu thiết bị có sức mạnh phù hợp, bạn sẽ mất quá nhiều thời gian để học hỏi từ những sai lầm của người khác và có thể nản lòng khi tiếp tục triển khai dự án Deep Learning. Với GPU, tôi đã học được cách áp dụng Deep Learning vào một loạt các cuộc thi Kaggle và tôi đã giành được vị trí thứ hai trong Partly Sunny với cuộc thi Chance of Hashtags Kaggle bằng cách sử dụng phương pháp Deep Learning, trong đó có một nhiệm vụ xếp hạng việc dự báo thời tiết. Trong cuộc thi, tôi đã sử dụng một deep neural network (DNN) hai lớp có quy mô lớn với các đơn vị tuyến tính được điều chỉnh để chuẩn hóa và DNN này chỉ vừa đủ trong bộ nhớ GPU 6GB của tôi. Các GPU GTX Titan hỗ trợ tôi trong cuộc thi là yếu tố chính giúp tôi đạt vị trí thứ 2 trong cuộc thi.
Tổng quan
Bài này được cấu trúc theo cách sau. Đầu tiên tôi bàn về việc có nhiều GPU sẽ hữu ích như thế nào, sau đó tôi sẽ thảo luận về tất cả các tùy chọn phần cứng có liên quan như GPU NVIDIA và AMD, Intel Xeon Phi, Google TPU và phần cứng cho startup mới. Sau đó, tôi thảo luận về thông số kỹ thuật GPU là chỉ số tốt cho hiệu suất của Deep Learning. Phần chính thảo luận về phân tích hiệu suất và hiệu quả chi phí. Tôi kết luận với các gợi ý GPU vừa tổng quan, vừa cụ thể hơn.

Nhiều GPU làm cho việc training của tôi nhanh hơn?
Khi bắt đầu sử dụng nhiều GPU, tôi rất hào hứng với việc thiết lập xử lý song song để cải thiện hiệu năng thời gian chạy cho cuộc thi Kaggle. Tuy nhiên, tôi thấy rằng rất khó để đạt được tốc độ mong muốn chỉ đơn giản bằng cách sử dụng nhiều GPU. Tò mò về vấn đề này, tôi bắt đầu thực hiện nghiên cứu vấn đề xử lý song song trong học Deep Learning. Tôi đã phân tích việc xử lý song song trong các kiến trúc Deep Learning, phát triển kỹ thuật lượng tử hóa 8 bit để tăng tốc độ trong các cụm GPU từ 23x lên 50x cho hệ thống 96 GPU và công bố nghiên cứu của tôi tại ICLR 2016.
Điểm quan trọng được nhận ra là các network thuộc kiểu “convolution” và “recurrent” lại khá dễ để song song hóa, đặc biệt nếu bạn chỉ sử dụng một máy tính hoặc 4 GPU. Tuy nhiên, các network được kết nối toàn phần, bao gồm cả các transformer, thì không đơn giản để song song và cần các thuật toán chuyên dụng để thực hiện tốt.

Các thư viện hiện đại như TensorFlow và PyTorch rất phù hợp để kết nối song song các mạng lặp và tích chập, và để tích chập, bạn có thể mong đợi tốc độ tăng lên khoảng 1,9x / 2,8x / 3,5x cho 2/3/4 GPU. Đối với các mạng lặp lại, độ dài chuỗi là tham số quan trọng nhất và đối với các sự cố NLP phổ biến, người ta có thể mong đợi các tốc độ tăng tốc tương tự hoặc kém hơn một chút so với các mạng chập. Các mạng kết nối đầy đủ, bao gồm cả máy biến áp, tuy nhiên, thường có hiệu suất kém đối với dữ liệu song song và các thuật toán tiên tiến hơn là cần thiết để tăng tốc các phần này của mạng. Nếu bạn chạy biến áp trên nhiều GPU, bạn nên thử chạy nó trên 1 GPU và xem nó có nhanh hơn hay không.
Sử dụng nhiều GPU mà không cần xử lý song song
Một lợi thế khác của việc sử dụng nhiều GPU, ngay cả khi bạn không song song hóa các thuật toán, là bạn có thể chạy nhiều thuật toán hoặc thử nghiệm riêng biệt trên mỗi GPU. Tìm kiếm hyperparameter một cách hiệu quả là cách vận dụng phổ biến nhất của thiết lập nhiều GPU. Bạn không tăng tốc, nhưng bạn có được thông tin nhanh hơn về hiệu suất của các thiết lập hyperparameter khác nhau hoặc kiến trúc mạng khác nhau. Điều này cũng rất hữu ích cho những người mới, vì bạn có thể nhanh chóng hiểu biết và trải nghiệm về cách bạn có thể training một kiến trúc Deep Learning không quen thuộc.
Sử dụng nhiều GPU theo cách này thường hữu ích hơn so với việc chạy một mạng trên nhiều GPU thông qua song song dữ liệu. Bạn nên ghi nhớ điều này khi bạn mua nhiều GPU: Chất lượng để có sự song song tốt hơn như số lượng làn PCIe không quan trọng khi bạn mua nhiều GPU.
Ngoài ra, lưu ý rằng một GPU duy nhất phải đủ cho hầu hết mọi tác vụ. Do đó, phạm vi trải nghiệm mà bạn có thể có với 1 GPU sẽ không khác so với khi bạn có 4 GPU. Sự khác biệt duy nhất là bạn có thể chạy nhiều thử nghiệm hơn trong một thời gian nhất định với nhiều GPU.
Tùy chọn của bạn: NVIDIA vs AMD vs Intel vs Google vs Amazon vs Microsoft vs Fancy Startup
NVIDIA: Người dẫn đầu
Các thư viện tiêu chuẩn của NVIDIA giúp dễ dàng thiết lập các thư viện Deep Learning đầu tiên trong CUDA, trong khi không có thư viện tiêu chuẩn mạnh như vậy cho OpenCL của AMD. Lợi thế ban đầu này kết hợp với sự hỗ trợ cộng đồng mạnh mẽ từ NVIDIA đã tăng quy mô của cộng đồng CUDA một cách nhanh chóng. Điều này có nghĩa là nếu bạn sử dụng GPU NVIDIA, bạn sẽ dễ dàng tìm thấy sự hỗ trợ nếu có sự cố xảy ra, bạn sẽ tìm thấy sự hỗ trợ và lời khuyên nếu bạn tự lập trình CUDA và bạn sẽ thấy rằng hầu hết các thư viện Deep Learning đều có hỗ trợ tốt nhất cho GPU NVIDIA. Trong những tháng cuối, NVIDIA vẫn rót thêm nhiều tài nguyên vào phần mềm . Ví dụ: thư viện Apexcung cấp hỗ trợ để ổn định độ dốc 16 bit trong PyTorch và cũng bao gồm các trình tối ưu hóa nhanh được hợp nhất như FuseAdam. Nhìn chung, phần mềm là một điểm rất mạnh đối với GPU NVIDIA.
Mặt khác, NVIDIA hiện có chính sách rằng việc sử dụng CUDA trong các trung tâm dữ liệu chỉ được phép cho GPU Tesla chứ không phải thẻ GTX hoặc RTX. Không rõ ý nghĩa của các trung tâm dữ liệu của Cameron là gì nhưng điều này có nghĩa là các tổ chức và trường đại học thường bị buộc phải mua GPU Tesla đắt tiền và không hiệu quả do lo ngại các vấn đề pháp lý. Tuy nhiên, thẻ Tesla không có lợi thế thực sự so với thẻ GTX và RTX và có giá cao gấp 10 lần.
NVIDIA chỉ có thể làm điều này mà không gặp bất kỳ trở ngại lớn nào cho thấy sức mạnh của sự độc quyền của họ – họ có thể làm theo ý mình và chúng tôi phải chấp nhận các điều khoản. Nếu bạn chọn những lợi thế lớn mà GPU NVIDIA có được về mặt cộng đồng và hỗ trợ, bạn cũng sẽ cần phải chấp nhận rằng bạn có thể được đẩy xung quanh theo ý muốn.
AMD: Hỗ trợ mạnh mẽ nhưng thiếu
HIP thông qua ROCm hợp nhất GPU NVIDIA và AMD theo ngôn ngữ lập trình chung được biên dịch thành ngôn ngữ GPU tương ứng trước khi được biên dịch thành lắp ráp GPU. Nếu chúng ta có tất cả mã GPU của mình trong HIP thì đây sẽ là một cột mốc quan trọng, nhưng điều này khá khó khăn vì rất khó để chuyển các cơ sở mã TensorFlow và PyTorch. TensorFlow và PyTorch có một số hỗ trợ cho GPU AMD và tất cả các mạng chính có thể chạy trên GPU AMD, nhưng nếu bạn muốn phát triển mạng mới, một số chi tiết có thể bị thiếu khiến bạn không thể thực hiện những gì bạn cần. Cộng đồng ROCm cũng không quá lớn và do đó không đơn giản để khắc phục sự cố nhanh chóng. AMD đầu tư rất ít vào phần mềm Deep Learning của họ và vì thế người ta không thể ngờ rằng khoảng cách phần mềm giữa NVIDIA và AMD sẽ đóng lại.
Hiện tại, hiệu suất của GPU AMD vẫn ổn. Hiện tại chúng có khả năng tính toán 16 bit, đây là một cột mốc quan trọng, tuy nhiên, các GPU của Tensor của NVIDIA cung cấp hiệu năng tính toán vượt trội hơn nhiều cho các máy biến áp và mạng chập (mặc dù không nhiều cho các mạng lặp lại cấp độ từ).
Nhìn chung, tôi nghĩ rằng tôi vẫn không thể đưa ra một khuyến nghị rõ ràng về GPU AMD cho người dùng thông thường chỉ muốn GPU của họ hoạt động trơn tru. Người dùng có nhiều kinh nghiệm hơn sẽ có ít vấn đề hơn và bằng cách hỗ trợ GPU AMD và nhà phát triển ROCm / HIP, họ góp phần vào cuộc chiến chống lại vị thế độc quyền của NVIDIA vì điều này sẽ giúp ích rất nhiều cho mọi người về lâu dài. Nếu bạn là nhà phát triển GPU và muốn đóng góp quan trọng cho điện toán GPU, thì GPU AMD có thể là cách tốt nhất để tạo ra tác động tốt trong dài hạn. Đối với những người khác, GPU NVIDIA có thể là lựa chọn an toàn hơn.
Intel: Sẽ phải cố gắng nhiều
Trải nghiệm cá nhân của tôi với Intel Xeon Phi (dòng chip này đã ngưng phát triển từ năm 2020 và được thay thế bằng Intel Gaudi) là rất đáng thất vọng và tôi không thấy họ là đối thủ thực sự của NVIDIA hay AMD và do đó tôi sẽ nói ngắn gọn: Nếu bạn quyết định đi với Xeon Phi, hãy lưu ý rằng bạn có thể gặp phải người nghèo hỗ trợ, các vấn đề điện toán làm cho các phần mã chậm hơn CPU, khó khăn trong việc viết mã được tối ưu hóa, không hỗ trợ đầy đủ các tính năng của C ++ 11, không hỗ trợ một số mẫu thiết kế GPU quan trọng, khả năng tương thích kém với các thư viện khác dựa trên các thói quen BLAS (NumPy và SciPy) và có lẽ nhiều nỗi thất vọng khác mà tôi không gặp phải.
Ngoài Xeon Phi, tôi thực sự mong đợi bộ xử lý mạng thần kinh Intel Nervana (NNP) vì thông số kỹ thuật của nó cực kỳ mạnh mẽ trong tay một nhà phát triển GPU và nó sẽ cho phép các thuật toán mới có thể xác định lại cách sử dụng mạng thần kinh, nhưng nó đã bị trì hoãn vô tận và có tin đồn rằng một phần lớn của sự phát triển đã nhảy thuyền. NNP được lên kế hoạch cho quý 3 năm 2019. Nếu bạn muốn chờ đợi lâu như vậy, hãy nhớ rằng một phần cứng tốt không phải là tất cả những gì chúng ta có thể thấy từ Xeon Phi của AMD và Intel. Nó có thể là vào năm 2020 hoặc 2021 cho đến khi NNP cạnh tranh với GPU hoặc TPU.
Google: Xử lý theo yêu cầu mạnh mẽ, giá rẻ
Google TPU đã phát triển thành một sản phẩm dựa trên đám mây rất trưởng thành, tiết kiệm chi phí. Cách dễ nhất để hiểu ý nghĩa của TPU là xem nó như nhiều GPU chuyên dụng được đóng gói cùng nhau chỉ có một mục đích: Thực hiện phép nhân ma trận nhanh. Nếu chúng ta xem xét các phép đo hiệu suất của V100 hỗ trợ core-core so với TPUv2, chúng ta thấy rằng cả hai hệ thống có hiệu suất gần như giống nhau cho ResNet50 [mất nguồn, không phải trên Wayback Machine]. Tuy nhiên, Google TPU tiết kiệm chi phí hơn. Vì TPU có cơ sở hạ tầng song song tinh vi, TPU sẽ có lợi ích tốc độ lớn hơn GPU nếu bạn sử dụng nhiều hơn 1 đám mây TPU (tương đương với 4 GPU).
Mặc dù vẫn còn thử nghiệm, PyTorch hiện cũng hỗ trợ TPU sẽ giúp củng cố cộng đồng và hệ sinh thái TPU.
TPU vẫn có một số vấn đề ở đây và ở đó, ví dụ, một báo cáo từ tháng 2 năm 2018 nói rằng TPUv2 không hội tụ khi sử dụng LSTM. Tôi không thể tìm thấy nguồn nếu sự cố đã được khắc phục.
Mặt khác, có một câu chuyện thành công lớn cho việc training các máy biến áp lớn trên TPU. Các mô hình dịch thuật GPT-2, BERT và máy có thể được training rất hiệu quả trên TPU. Theo ước tính của tôi từ bài đăng trên blog TPU và GPU của tôi, TPU nhanh hơn khoảng 56% so với GPU và nhờ giá thấp hơn so với GPU đám mây, chúng là một lựa chọn tuyệt vời cho các dự án biến áp lớn.
Tuy nhiên, một vấn đề với việc training các mô hình lớn trên TPU có thể là chi phí tích lũy. TPU có hiệu suất cao được sử dụng tốt nhất trong giai đoạn training. Trong giai đoạn tạo mẫu và suy luận, bạn nên dựa vào các tùy chọn không phải đám mây để giảm chi phí. Do đó, training về TPU, nhưng tạo mẫu và suy luận về GPU cá nhân của bạn là lựa chọn tốt nhất.
Để kết luận, hiện tại, TPU dường như được sử dụng tốt nhất để training mạng tích chập hoặc máy biến áp lớn và nên được bổ sung bằng các tài nguyên tính toán khác thay vì tài nguyên Deep Learning chính.
Amazon AWS và Microsoft Azure: Đáng tin cậy nhưng đắt tiền
Các phiên bản GPU từ Amazon AWS và Microsoft Azure rất hấp dẫn bởi vì người ta có thể dễ dàng tăng quy mô và thu nhỏ dựa trên nhu cầu. Điều này rất hữu ích cho thời hạn giấy hoặc cho các dự án một lần lớn hơn. Tuy nhiên, tương tự như TPU, chi phí thô tăng lên nhanh chóng. Hiện tại, các phiên bản đám mây GPU quá đắt để sử dụng riêng rẽ và tôi khuyên bạn nên có một số GPU giá rẻ chuyên dụng để tạo mẫu trước khi bắt đầu các công việc training cuối cùng trong đám mây.
Startup ưa thích: Khái niệm phần cứng mang tính cách mạng không có phần mềm
Có một loạt các công ty khởi nghiệp nhằm tạo ra thế hệ phần cứng Deep Learning tiếp theo. Các công ty này thường có một thiết kế lý thuyết tuyệt vời, sau đó được Google / Intel hoặc những người khác mua để có được tài trợ mà họ cần để tạo ra một thiết kế đầy đủ và sản xuất chip. Đối với thế hệ chip tiếp theo (3nm), chi phí cho việc này là khoảng 1 tỷ USD trước khi một con chip có thể được sản xuất. Khi giai đoạn này được hoàn thành (chưa có công ty nào quản lý để thực hiện việc này), vấn đề chính là phần mềm. Không có công ty nào quản lý để sản xuất phần mềm sẽ hoạt động trong kho học tập sâu hiện tại. Một bộ phần mềm đầy đủ cần được phát triển để cạnh tranh, điều này rõ ràng từ ví dụ AMD vs NVIDIA: AMD có phần cứng tuyệt vời nhưng chỉ có 90% phần mềm – điều này không đủ để cạnh tranh với NVIDIA.
Hiện tại, không có công ty nào ở gần hoàn thành cả hai bước phần cứng và phần mềm. Intel NNP có thể là gần nhất, nhưng từ tất cả những thứ này không thể mong đợi một sản phẩm cạnh tranh trước năm 2020 hoặc 2021. Vì vậy, hiện tại chúng ta sẽ cần phải gắn bó với GPU và TPU.
Do đó, phần cứng mới lạ mắt từ khởi động yêu thích của bạn có thể được bỏ qua một cách an toàn cho đến bây giờ.
Điều gì làm cho một GPU nhanh hơn một GPU khác?
Câu hỏi đầu tiên của bạn có thể là tính năng quan trọng nhất cho hiệu năng GPU nhanh để Deep Learning: Đó có phải là core CUDA không? Tốc độ đồng hồ? Dung lượng RAM?
Năm 2019, việc lựa chọn GPU trở nên khó hiểu hơn bao giờ hết: điện toán 16 bit, core căng, GPU 16 bit không có core kéo, nhiều thế hệ GPU vẫn còn khả thi (Turn, Volta, Maxwell). Nhưng vẫn có một số chỉ số hiệu suất đáng tin cậy mà mọi người có thể sử dụng như một quy tắc. Dưới đây là một số hướng dẫn ưu tiên cho các kiến trúc Deep Learning khác nhau:
Mạng kết hợp và máy biến áp: core kéo> FLOPs> Băng thông bộ nhớ> Khả năng 16 bit
Mạng tái phát: Băng thông bộ nhớ> Khả năng 16 bit> core kéo> FLOP
Điều này có nội dung như sau: Nếu tôi muốn sử dụng, ví dụ, mạng chập, trước tiên tôi nên ưu tiên GPU có core căng, sau đó là số FLOP cao, sau đó là băng thông bộ nhớ cao và sau đó là GPU có khả năng 16 bit . Trong khi ưu tiên, điều quan trọng là chọn một GPU có đủ bộ nhớ GPU để chạy các mô hình mà người ta quan tâm.
Tại sao cần những sự ưu tiên này?
Một điều giúp tăng cường sự hiểu biết của bạn để đưa ra lựa chọn sáng suốt là tìm hiểu một chút về phần nào của phần cứng giúp GPU nhanh cho hai hoạt động căng thẳng quan trọng nhất: Nhân ma trận và tích chập.
Một cách đơn giản và hiệu quả để suy nghĩ về phép nhân ma trận A * B = C là giới hạn băng thông bộ nhớ: Sao chép bộ nhớ của A, B cho đến khi chip tốn kém hơn so với việc tính toán A * B. Điều này có nghĩa là băng thông bộ nhớ là tính năng quan trọng nhất của GPU nếu bạn muốn sử dụng các LSTM và các mạng lặp lại khác thực hiện nhiều phép nhân ma trận nhỏ. Phép nhân ma trận càng nhỏ, băng thông bộ nhớ càng quan trọng.
Ngược lại, tích chập bị ràng buộc bởi tốc độ tính toán. Do đó, TFLOP trên GPU là chỉ số tốt nhất cho hiệu suất của ResNets và các kiến trúc tích chập khác. core kéo có thể tăng FLOP đáng kể.
Phép nhân ma trận lớn như được sử dụng trong các máy biến áp nằm giữa tích chập và phép nhân ma trận nhỏ của RNN. Phép nhân ma trận lớn được hưởng lợi rất nhiều từ bộ lưu trữ 16 bit, core kéo và FLOP nhưng chúng vẫn cần băng thông bộ nhớ cao.
Lưu ý rằng để sử dụng các lợi ích của core kéo, bạn nên sử dụng dữ liệu và trọng lượng 16 bit – tránh sử dụng 32 bit với thẻ RTX! Nếu bạn gặp phải vấn đề với training 16 bit khi sử dụng PyTorch, thì bạn nên sử dụng tỷ lệ mất động như được cung cấp bởi thư viện Apex . Nếu bạn sử dụng TensorFlow, bạn có thể tự thực hiện chia tỷ lệ tổn thất: (1) nhân số lỗ của bạn với một số lớn, (2) tính toán độ dốc, (3) chia cho số lớn, (4) cập nhật trọng số của bạn. Thông thường, training 16 bit sẽ tốt, nhưng nếu bạn gặp khó khăn trong việc sao chép kết quả với tỷ lệ mất 16 bit thường sẽ giải quyết được vấn đề.
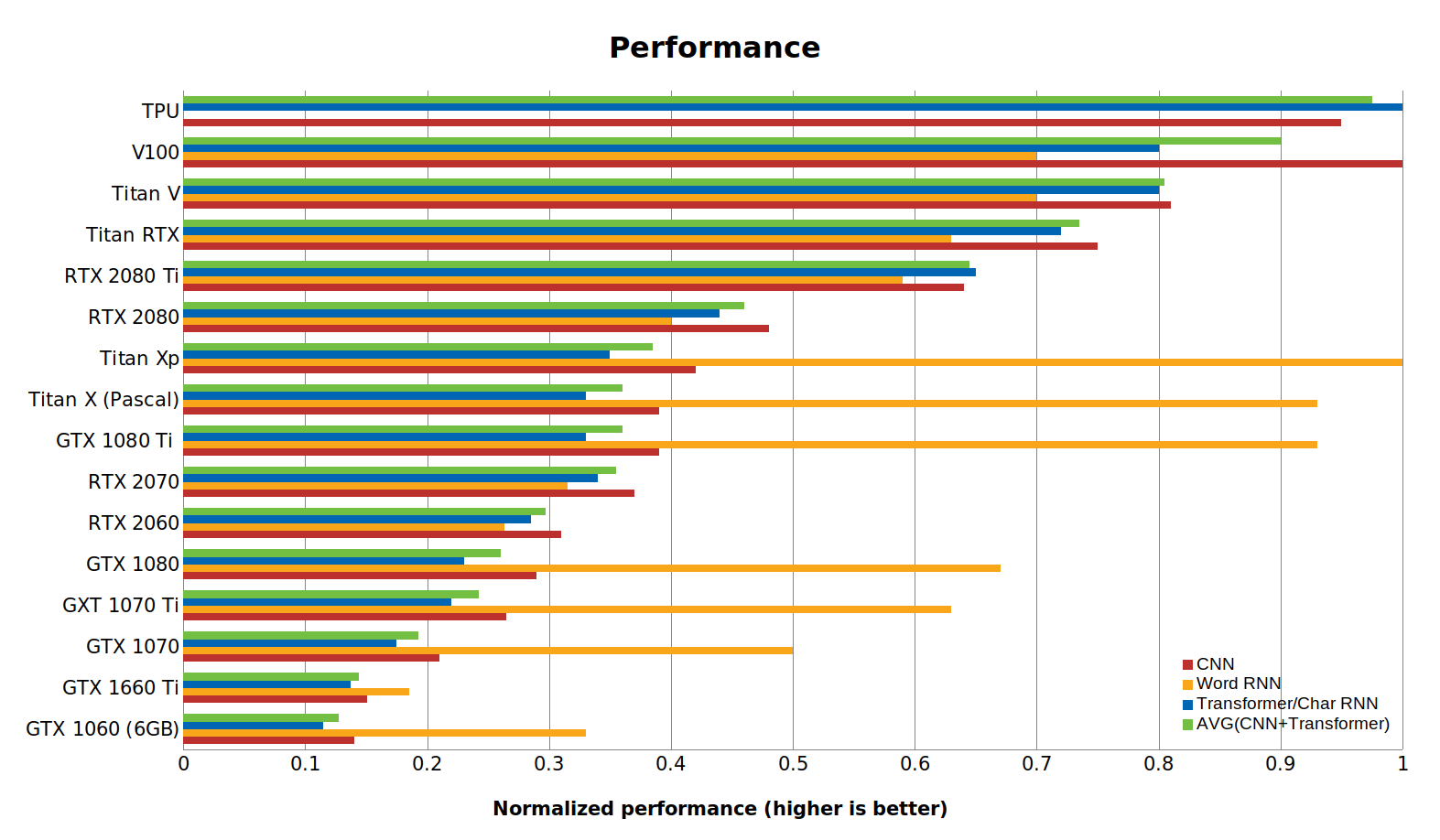
Phân tích hiệu quả chi phí
Hiệu quả chi phí của GPU có lẽ là tiêu chí quan trọng nhất để chọn GPU. Phân tích hiệu suất cho cập nhật bài đăng trên blog này được thực hiện như sau:
(1) Đối với máy biến áp, tôi đã điểm chuẩn Transformer-XL và BERT.
(2) Đối với RNN từ và char tôi đã điểm chuẩn các mô hình biLSTM hiện đại.
(3) Việc đo điểm chuẩn trong (1) và (2) đã được thực hiện cho Titan Xp, Titan RTX và RTX 2080 Ti. Đối với các thẻ khác, tôi chia tỷ lệ chênh lệch hiệu suất một cách tuyến tính.
(4) Tôi đã sử dụng điểm chuẩn hiện có cho CNN: ( 1 , 2 , 3 , 4 , 5 , 6 , 7 ).
(5) Tôi đã sử dụng chi phí trung bình của Amazon và eBay làm chi phí tham chiếu cho GPU.
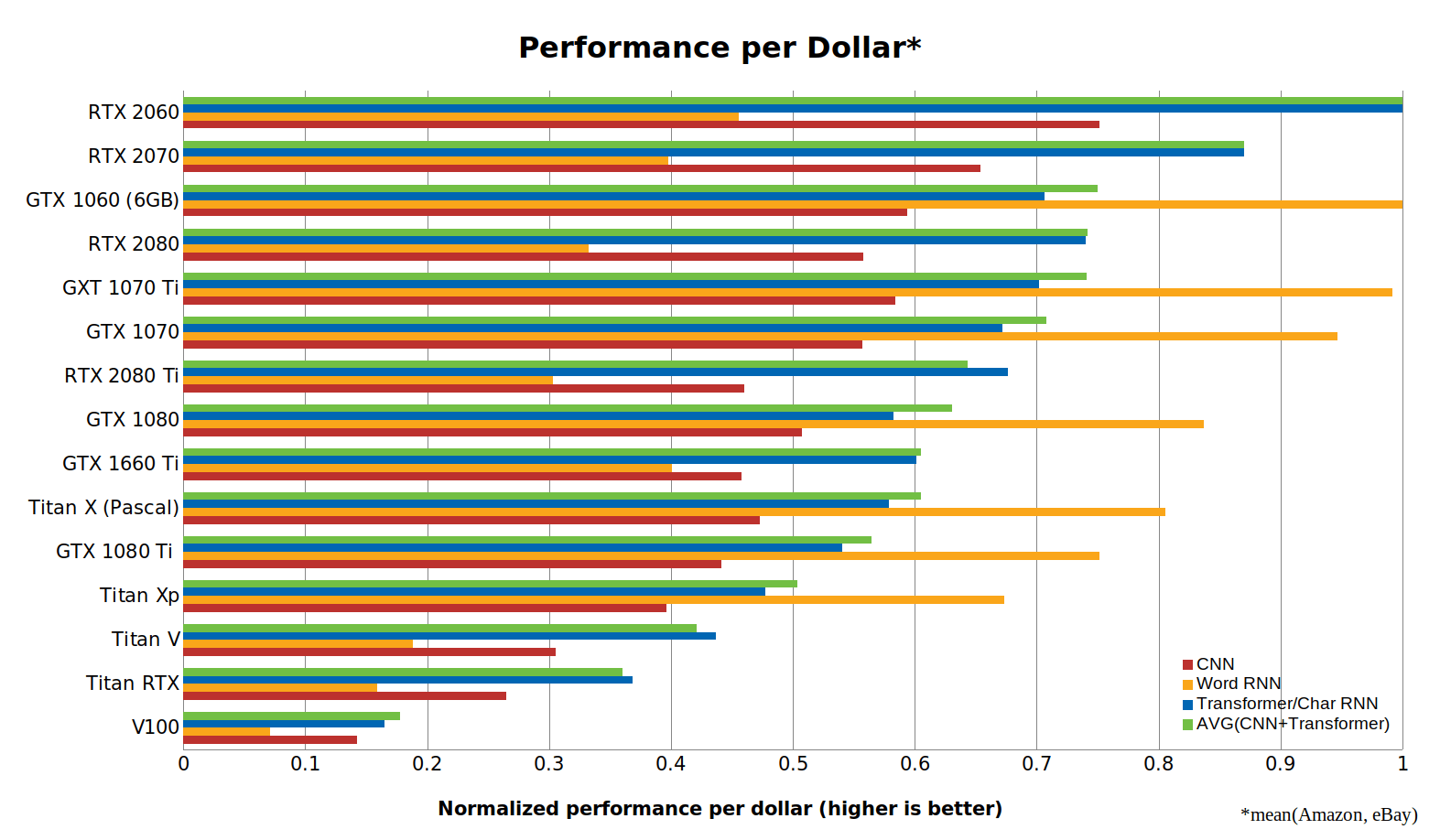
Từ dữ liệu này, chúng ta thấy rằng RTX 2060 tiết kiệm chi phí hơn RTX 2070, RTX 2080 hoặc RTX 2080 Ti. Tại sao cái này rất? Khả năng thực hiện tính toán 16 bit với Tensor Cores có giá trị hơn nhiều so với việc chỉ có một con tàu lớn hơn với nhiều core Tensor Cores. Với RTX 2060, bạn có được những tính năng này với giá thấp nhất.
Tuy nhiên, phân tích này có những thành kiến nhất định cần được tính đến:
(1) Phân tích này thiên vị mạnh mẽ ủng hộ các thẻ nhỏ hơn. GPU nhỏ hơn, tiết kiệm chi phí có thể không có đủ bộ nhớ để chạy các mô hình mà bạn quan tâm!
(2) Giá quá cao thẻ GTX 10xx: Hiện tại, thẻ GTX 10XX dường như được định giá quá cao do các game thủ không thích thẻ RTX.
(3) Xu hướng GPU đơn: Một máy tính có 4 thẻ không hiệu quả về chi phí (4x RTX 2080 Ti) tiết kiệm chi phí hơn nhiều so với 2 máy tính có thẻ chi phí / hiệu quả nhất (8x RTX 2060).
Cảnh báo: Sự cố nhiệt trên RTX đa GPU
Có vấn đề với RTX 2080 Ti và các GPU RTX khác với quạt kép tiêu chuẩn nếu bạn sử dụng nhiều GPU chạy cạnh nhau. Điều này đặc biệt như vậy đối với nhiều RTX 2080 Ti trong một máy tính nhưng nhiều RTX 2080 và RTX 2070 cũng có thể bị ảnh hưởng. Quạt trên một số thẻ RTX là một thiết kế mới được NVIDIA phát triển để cải thiện trải nghiệm cho các game thủ chạy một GPU (im lặng, nhiệt thấp hơn cho một GPU). Tuy nhiên, thiết kế rất tệ nếu bạn sử dụng nhiều GPU có thiết kế quạt kép mở này. Nếu bạn muốn sử dụng nhiều thẻ RTX chạy cạnh nhau (trực tiếp trong khe PCIe tiếp theo) thì bạn nên lấy phiên bản có thiết kế quạt đơn kiểu quạt gió kiểu Drake. Điều này đặc biệt đúng với thẻ RTX 2080 Ti. ASUS và PNY hiện có các mẫu RTX 2080 Ti trên thị trường với quạt kiểu quạt gió.
Kích thước bộ nhớ cần thiết và training 16 bit
Bộ nhớ trên GPU có thể rất quan trọng đối với một số ứng dụng như thị giác máy tính, dịch máy và một số ứng dụng NLP khác và bạn có thể nghĩ rằng RTX 2070 tiết kiệm chi phí, nhưng bộ nhớ của nó quá nhỏ với 8 GB. Tuy nhiên, lưu ý rằng thông qua training 16 bit, bạn hầu như có bộ nhớ 16 GB và mọi mô hình tiêu chuẩn sẽ dễ dàng phù hợp với RTX 2070 của bạn nếu bạn sử dụng 16 bit. Điều tương tự cũng đúng với RTX 2080 và RTX 2080 Ti. Tuy nhiên, xin lưu ý rằng trong hầu hết các khung phần mềm, bạn sẽ không tự động tiết kiệm một nửa bộ nhớ bằng cách sử dụng 16 bit vì một số khung lưu trữ trọng lượng trong 32 bit để thực hiện cập nhật độ dốc chính xác hơn, v.v. Một nguyên tắc nhỏ là giả sử thêm 50% bộ nhớ với tính toán 16 bit. Vì vậy, bộ nhớ 8GB 16 bit có kích thước tương đương với bộ nhớ 12 GB 12 bit.
Khuyến nghị chung về GPU
Hiện tại, khuyến nghị chính của tôi là lấy GPU RTX 2070 và sử dụng training 16 bit. Tôi sẽ không bao giờ khuyên bạn nên mua XP Titan, Titan V, bất kỳ thẻ Quadro hoặc bất kỳ GPU Phiên bản sáng lập nào. Tuy nhiên, có một số GPU cụ thể cũng có vị trí của chúng:
(1) Để có thêm bộ nhớ, tôi muốn giới thiệu RTX 2080 Ti. Nếu bạn thực sự cần nhiều bộ nhớ bổ sung, RTX Titan là lựa chọn tốt nhất – nhưng hãy chắc chắn rằng bạn thực sự cần bộ nhớ đó!
(2) Để có hiệu suất cao hơn, tôi muốn giới thiệu RTX 2080 Ti.
(3) Nếu bạn thiếu tiền, tôi sẽ giới thiệu bất kỳ thẻ GTX 10XX giá rẻ nào từ eBay (tùy thuộc vào dung lượng bộ nhớ bạn cần) hoặc RTX 2060. Nếu quá đắt, hãy xem Colab .
(4) Nếu bạn chỉ muốn bắt đầu với việc tìm hiểu sâu thì GTX 1060 (6GB) là một lựa chọn tuyệt vời.
(5) Nếu bạn đã có GTX 1070 trở lên: Đợi nó ra. Một bản nâng cấp không đáng giá trừ khi bạn làm việc với các máy biến áp lớn.
(6) Bạn muốn học nhanh cách Deep Learning: Nhiều GTX 1060 (6GB).
Deep Learning trong đám mây
Cả hai phiên bản GPU trên AWS / Azure và TPU trong Google Cloud đều là các tùy chọn khả thi để Deep Learning. Mặc dù TPU rẻ hơn một chút nhưng nó lại thiếu tính linh hoạt và linh hoạt của GPU đám mây. TPU có thể là vũ khí được lựa chọn để training mô hình nhận dạng đối tượng hoặc máy biến áp. Đối với các GPU đám mây tải công việc khác là đặt cược an toàn hơn – điều tốt về các trường hợp đám mây là bạn có thể chuyển đổi giữa GPU và TPU bất cứ lúc nào hoặc thậm chí sử dụng cả hai cùng một lúc.
Tuy nhiên, hãy chú ý đến chi phí cơ hội ở đây: Nếu bạn học các kỹ năng để có một luồng công việc trôi chảy với AWS / Azure, bạn đã mất thời gian có thể làm việc trên GPU cá nhân và bạn cũng sẽ không có được các kỹ năng để sử dụng TPU. Nếu bạn sử dụng GPU cá nhân, bạn sẽ không có kỹ năng mở rộng thành nhiều GPU / TPU hơn thông qua đám mây. Nếu bạn sử dụng TPU, bạn có thể bị kẹt với TensorFlow trong một thời gian nếu bạn muốn các tính năng đầy đủ và sẽ không đơn giản để chuyển cơ sở mã của bạn sang PyTorch. Học một luồng công việc GPU / TPU trên đám mây trơn tru là một chi phí cơ hội đắt đỏ và bạn nên cân nhắc chi phí này nếu bạn lựa chọn cho TPU, GPU đám mây hoặc GPU cá nhân.
Một câu hỏi khác cũng là về khi nào nên sử dụng dịch vụ đám mây. Nếu bạn cố gắng Deep Learning hoặc bạn cần tạo nguyên mẫu thì GPU cá nhân có thể là lựa chọn tốt nhất vì các trường hợp đám mây có thể tốn kém. Tuy nhiên, một khi bạn đã tìm thấy một cấu hình mạng sâu tốt và bạn chỉ muốn training một mô hình bằng cách sử dụng song song dữ liệu thì sử dụng các trường hợp đám mây là một cách tiếp cận chắc chắn. Điều này có nghĩa là một GPU nhỏ sẽ đủ để tạo mẫu và người ta có thể dựa vào sức mạnh của điện toán đám mây để mở rộng quy mô cho các thử nghiệm lớn hơn.
Nếu bạn thiếu tiền, các trường hợp điện toán đám mây cũng có thể là một giải pháp tốt: Nguyên mẫu trên CPU và sau đó tung ra các phiên bản GPU / TPU để chạy nhanh. Đây không phải là luồng công việc tốt nhất vì việc tạo mẫu trên CPU có thể là một nỗi đau lớn, nhưng nó có thể là một sự thay thế hiệu quả về chi phí.
Phần kết luận
Với thông tin trong bài đăng trên blog này, bạn sẽ có thể suy luận GPU nào phù hợp với mình. Nói chung, tôi thấy ba chiến lược chính (1) gắn với GPU GTX 1070 hoặc tốt hơn của bạn, (2) mua GPU RTX, (3) sử dụng một số loại GPU để tạo mẫu và sau đó huấn luyện mô hình của bạn trên GPU TPU hoặc GPU đám mây.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent