
Tính toán song song: Tại sao GPU được sử dụng trong Deep Learning
Các tải xử lý deep learning và AI như xây dựng, đào tạo và suy luận đều yêu cầu một lượng lớn tài nguyên máy tính. Phần lớn chúng là các hệ thống được thực thi song song vì mạng nơ-ron học sâu bản chất là một bài toán song song, một thuật ngữ thực tế dùng để mô tả các tác vụ tính toán được chia thành các phép tính phụ nhỏ hơn và được thực hiện cùng một lúc.
GPU hoặc Bộ xử lý đồ họa cung cấp khả năng song song tuyệt vời trong tải xử lý và chỉ trong vòng một thập kỷ qua chúng mới được quan tâm và hướng đến ngành AI và Deep Learning. Nếu không có sự kết hợp của GPU, việc đào tạo, xây dựng và triển khai các mô hình deep learning có thể kéo dài hàng ngày, hàng tuần, thậm chí hàng tháng… GPU giúp bạn cần ít thời gian hơn để phát triển đầy đủ AI.

NVIDIA CUDA là gì?
NVIDIA CUDA là nền tảng API cho phép tính toán song song với phần cứng GPU, giúp các developer xây dựng phần mềm với khả năng tăng tốc tác vụ dễ dàng hơn bằng cách cho phép phân bổ tải xử lý trên các GPU liên kết song song.
Sử dụngNVIDIA CUDA Toolkit, bạn có thể tăng tốc các ứng dụng C hoặc C++ bằng cách cập nhật các phần mã có cường độ tính toán cao để chạy trên GPU. Gọi các hàm từ thư viện drop-in hoặc phát triển các ứng dụng tùy biến bằng các ngôn ngữ bao gồm C, C++, Fortran, Python và MATLAB.
Các công ty trên khắp thế giới hiện đã khai thác hiệu quả CUDA Toolkit cho mục đích của họ. Trong đó, các công ty dược phẩm sử dụng CUDA để khám phá các phương pháp điều trị mới, các công ty ô tô đã sử dụng CUDA để tăng cường và huấn luyện các phương tiện tự lái, còn các cửa hàng bán lẻ sử dụng CUDA để phân tích hoạt động mua hàng của khách hàng nhằm phát triển hệ thống tư vấn mạnh mẽ và chính xác.
Các GPU tốt nhất cho tải xử lý deep learning và AI bao gồm:
- GPU trung tâm dữ liệu NVIDIA (DGX, H100, A100, A40, A10, v.v.)
- NVIDIA Professional RTX (A6000, A5500, A5000, v.v.)
- GPU GeForce RTX 20-Series, 30-Series hoặc 40-Series. (2080 Ti, 3090 Ti, 4090, v.v.)
CUDA Toolkit là tài nguyên miễn phí dành cho một hoặc nhiều GPU hỗ trợ CUDA. Ứng dụng của nó trải dài từ các nhà phát triển độc lập và nhà khoa học dữ liệu cho đến các tập đoàn doanh nghiệp có hạ tầng AI và deep learning lớn.

Các SDK phổ biến với CUDA
Nhiều framework dựa vào CUDA để hỗ trợ GPU như TensorFlow, PyTorch, Keras, MXNet và Caffe2 thông qua cuDNN (Mạng thần kinh sâu CUDA). Việc đào tạo một mô hình AI yêu cầu sử dụng mạng lưới thần kinh và cuDNN hỗ trợ việc sử dụng các công cụ phức tạp cần thiết cho việc học sâu này.
Bên cạnh cuDNN, CUDA còn bao gồm các công cụ như TensorRT, DeepStream SDK, NCCL, v.v. Dưới đây là tóm tắt ngắn gọn về những gì mỗi công cụ cung cấp:
- Deep Learning Primitives [ cuDNN ]: các khối xây dựng hiệu suất cao cho các ứng dụng mạng thần kinh sâu bao gồm tích chập, hàm kích hoạt và tensor transformer
- Suy luận học sâu [ TensorRT ]: runtime suy luận học sâu hiệu suất cao để triển khai cấp độ sản xuất
- Học sâu cho phân tích video [ DeepStream SDK ]: API C++ cấp cao và runtime để transcode và suy luận học sâu, được tăng tốc bằng GPU
- Truyền thông đa GPU [ NCCL ]: các quy trình trao đổi đa điểm, chẳng hạn như all-gather, reduce và broadcast giúp tăng tốc quá trình đào tạo học sâu đa GPU trên tối đa tám GPU
Ngoài các ứng dụng và SDK cấp cao nhất này, CUDA Toolkit còn bao gồm nhiều thư viện và thành phần khác nhau để gỡ lỗi, tối ưu hóa, lập tài liệu, runtime, xử lý tín hiệu, v.v.
Lập trình CUDA
Như đã đề cập trước đó, CUDA cung cấp khả năng hỗ trợ tăng tốc cho cả C, C++, Fortran, Python và MATLAB. Nhưng để đơn giản, chúng ta sẽ tập trung vào C/C++. Để dễ dàng áp dụng, CUDA cung cấp giao diện đơn giản tương tự như C/C++. Lợi ích của CUDA là khả năng viết chương trình vô hướng. Trình biên dịch của nó sử dụng tính trừu tượng hóa lập trình để tận dụng tính song song được tích hợp trong mô hình lập trình CUDA, giảm bớt gánh nặng lập trình.
Chế độ lập trình CUDA cung cấp ba phần mở rộng ngôn ngữ chính:
- CUDA block: tập hợp các luồng hay thread
- Bộ nhớ dùng chung: bộ nhớ được chia sẻ trong một khối giữa tất cả các luồng
- Rào cản đồng bộ hóa: cho phép nhiều luồng đợi cho đến khi tất cả các luồng đã đạt đến một điểm thực thi cụ thể trước khi bất kỳ hoặc tất cả các luồng được tiếp tục.
Hãy xem một đoạn code ví dụ:
__global__ void vectorAdd( float *A, float *B, float *C, int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i];
}
}
Ví dụ về mã cho thấy CUDA Kernel thêm hai vectơ A và B với một vectơ đầu ra là C. Kernel code thực thi trên GPU và có bản chất vô hướng vì nó thêm hai vectơ theo cách trông giống như cộng hai con số vô hướng.
Khi mã này chạy trên GPU, nó chạy theo kiểu song song ồ ạt. Mỗi phần tử của vectơ được thực thi bởi một luồng trong khối CUDA và tất cả các luồng chạy song song và độc lập. Điều này đơn giản hóa chi phí lập trình song song.
Sơ đồ bên dưới cho thấy chương trình CUDA có thể mở rộng như thế nào. CUDA Runtime có thể chọn cách phân bổ các khối này cho các streaming multiprocessor (SM).
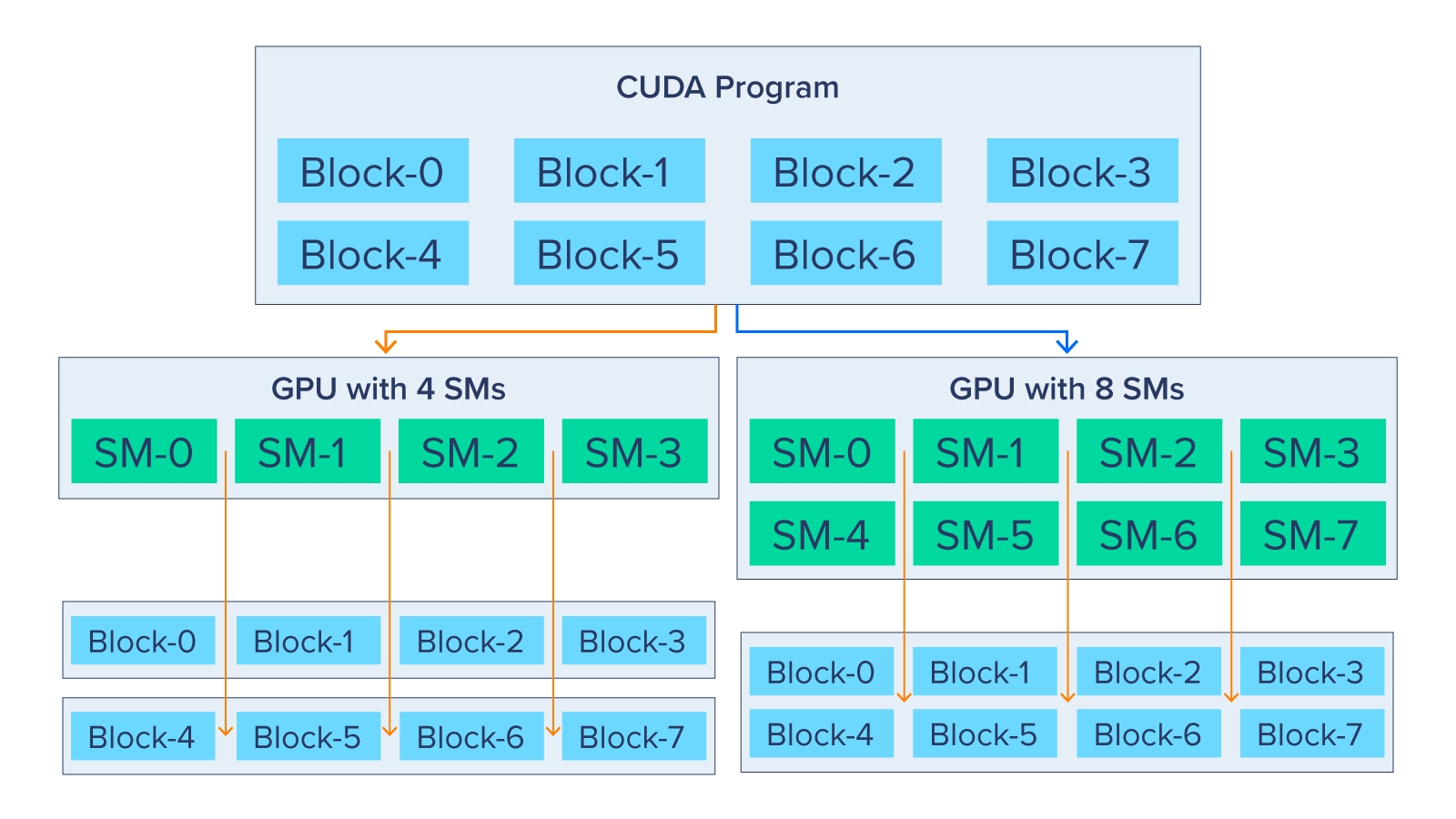
GPU nhỏ hơn có 4 SM sẽ có hai khối CUDA riêng biệt trong khi GPU lớn có 8 SM sẽ chỉ có 1 khối CUDA. GPU có 4 SM sẽ phải thực thi đồng thời các khối luồng 0, 1, 2 và 3 rồi bắt đầu đồng thời 4, 5, 6 và 7. Tất nhiên, nhiều SM hơn có nghĩa là khả năng song song hóa cao hơn trong đó các khối luồng 0-7 đều được thực thi đồng thời trong GPU có 8 SM.
Điều này cho phép khả năng mở rộng hiệu suất cho các ứng dụng có GPU mạnh hơn mà không cần bất kỳ thay đổi mã nào và đây chính là lý do tại sao GPU của trung tâm dữ liệu và tài nguyên điện toán của chúng lại có giá trị như vậy..
Các thực tiễn triển khai tốt nhất về CUDA Toolkit
Tối đa hóa việc thực thi song song
Tối đa hóa khả năng thực thi song song bắt đầu bằng việc cấu trúc thuật toán theo cách thể hiện nhiều tính song song nhất có thể và ánh xạ tới phần cứng hiệu quả nhất có thể bằng cách chọn cẩn thận cấu hình thực thi của mỗi lần khởi chạy kernel. Ứng dụng cũng phải tối đa hóa việc thực thi song song ở mức cao hơn bằng cách hiển thị rõ ràng việc thực thi đồng thời trên thiết bị thông qua các luồng, cũng như tối đa hóa việc thực thi đồng thời giữa máy chủ và thiết bị.
Tối ưu hóa việc sử dụng bộ nhớ/Đạt băng thông tối đa
Tối ưu hóa việc sử dụng bộ nhớ bắt đầu bằng việc giảm thiểu việc truyền dữ liệu giữa máy chủ và thiết bị. Giữ dữ liệu gần máy chủ và nội bộ có thể làm giảm đáng kể số lượng truyền dữ liệu không cần thiết đến thiết bị. Quyền truy cập ở mức kernel vào bộ nhớ chung cũng cần được giảm thiểu bằng cách tối đa hóa việc sử dụng bộ nhớ dùng chung trên thiết bị. Mặc dù có vẻ phản trực giác, do GPU có khả năng tính toán xuất sắc, đôi khi cách tối ưu hóa tốt nhất thậm chí có thể là tránh mọi hoạt động truyền dữ liệu ngay từ đầu bằng cách chỉ cần tính toán lại dữ liệu bất cứ khi nào cần.
Tối ưu hóa việc sử dụng lệnh/Đạt được thông lượng cao nhất
Băng thông hiệu quả có thể khác nhau tùy thuộc vào kiểu truy cập cho từng loại bộ nhớ. Tối ưu hóa việc sử dụng bộ nhớ có thể đơn giản như việc tổ chức truy cập bộ nhớ theo các mẫu truy cập bộ nhớ tối ưu. Sự tối ưu hóa này đặc biệt quan trọng đối với việc truy cập bộ nhớ toàn cục vì độ trễ truy cập tốn hàng trăm chu kỳ xung nhịp.
Để tối ưu hóa việc sử dụng lệnh, nên tránh sử dụng các lệnh số học có thông lượng thấp. Điều này cho thấy việc đánh đổi độ chính xác để lấy tốc độ khi nó không ảnh hưởng đến kết quả, chẳng hạn như sử dụng nội tại thay vì các hàm thông thường hoặc độ chính xác đơn thay vì độ chính xác kép.
GPU tốt nhất của NVIDIA dành cho CUDA
Không có gì ngạc nhiên khi NVIDIA H100 có vẻ là GPU tốt nhất cho tải xử lý AI sử dụng CUDA Toolkit. Với tư cách là công cụ tăng tốc GPU và AI trung tâm dữ liệu hàng đầu của NVIDIA, nó đã được triển khai nhiều thực tiễn hay nhất được tích hợp trong kiến trúc của mình.
Thread Block Cluster
Sự phức tạp của NVIDIA H100 cần một cách mới để tổ chức và kiểm soát vị trí của các khối luồng (Thread Block). Khối luồng chứa các luồng đồng thời trên SM; Để sắp xếp hợp lý hơn nữa, việc bổ sung theo cấp bậc các cụm khối luồng sẽ làm tăng hiệu quả của các luồng đồng thời trên toàn bộ SM. Nhóm này cũng đã kích hoạt bộ nhớ chia sẻ phân tán (DSMEM) để cho phép trao đổi dữ liệu hiệu quả bằng cách sử dụng mạng SM-to-SM thay vì mạng bộ nhớ chung. Thread Bl8ck Cluster và dữ liệu DSMEM được tăng tốc trao đổi khoảng 7 lần.
Transformer Engine với FP8
Họ cũng đã tham gia vào việc sử dụng hướng dẫn tối ưu hóa bằng cách cho phép H100 huấn luyện trên định dạng xử lý tensor mới FP8. FP8 hỗ trợ các tính toán yêu cầu phạm vi động ít hơn với độ chính xác cao hơn, giảm một nửa yêu cầu lưu trữ trong khi tăng gấp đôi thông lượng so với FP16. Để tăng độ chính xác một cách đáng kể, NVIDIA H100 kết hợp transformer engine mới sử dụng các lệnh thực thi bằng cách sử dụng xử lý chính xác hỗn hợp động trên cả hai định dạng số FP8 và FP16 để giảm mức sử dụng dữ liệu và tăng tốc độ trong khi vẫn giữ được độ chính xác và chính xác.

Cài đặt CUDA
Đây là cách chuẩn bị hệ thống sẵn sàng cho việc cài đặt CUDA. Sau khi cài đặt CUDA, bạn có thể bắt đầu viết các ứng dụng song song và tận dụng tính năng song song lớn có sẵn trong GPU.
Dưới đây là một số tài nguyên trên trang web của NVIDIA có thể giúp tìm hiểu xem CUDA có phù hợp với tải xử lý của bạn hay không cũng như một số tài liệu hữu ích khác.
Để biết thêm thông tin, hãy xem Hướng dẫn lập trình CUDA .
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent