Người ta khẳng định rằng mức cải thiện tiến trình (process) ở các con chip xử lý ít quan trọng hơn nhiều so với những cải tiến về hiệu suất suy luận GPU khi nó đã hơn gấp 1.000 lần so với thập kỷ trước.
Khi mọi người tranh luận liệu Định luật Moore có đang chậm lại, vẫn còn có thể áp dụng hay thậm chí có còn tồn tại hay đã chết ở những năm 2020 này, các nhà khoa học của NVIDIA đã báo trước động lực ấn tượng đằng sau cái gọi là ‘Định luật Huang’. Trong thập kỷ qua, năng lực xử lý AI của GPU NVIDIA được cho là đã tăng gấp 1000 lần. Định luật Huang cho thấy rằng tốc độ tăng tốc mà chúng ta đã thấy trong “hiệu suất suy luận của một con chip” giờ đây sẽ không giảm dần mà sẽ tiếp tục tăng lên.
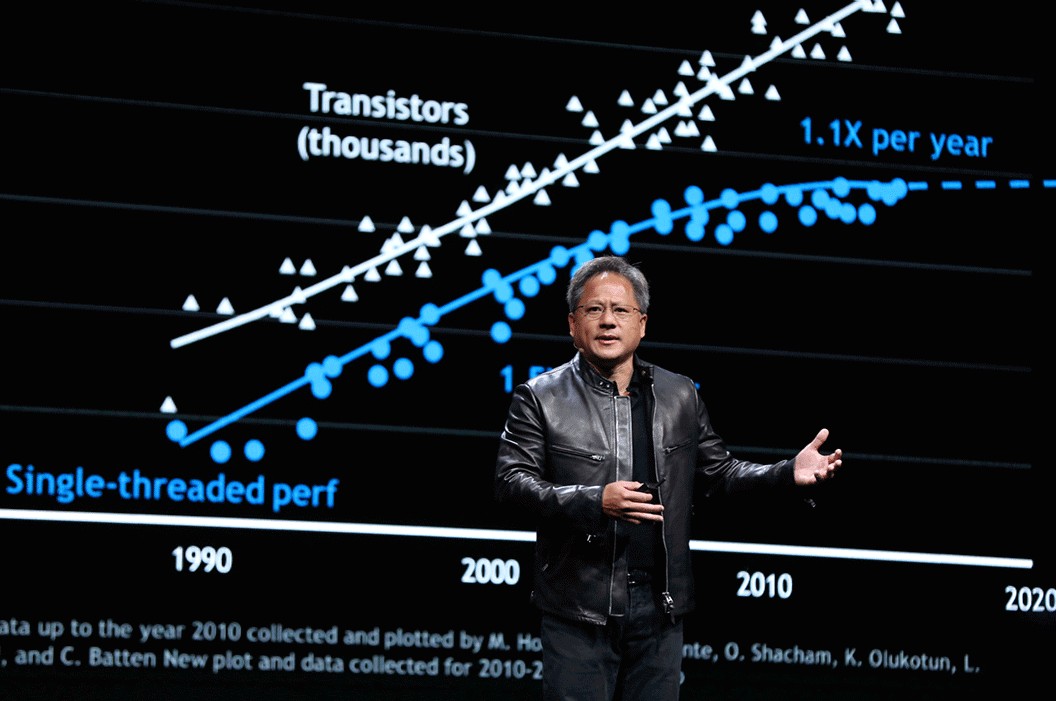
NVIDIA đã vừa xuất bản một bài đăng trên blog về Định luật Huang, nêu rõ niềm tin và công việc thực tế đằng sau nó. Điều mà Nhà khoa học trưởng của NVIDIA, Bill Dally, mô tả là “sự thay đổi mang tính kiến tạo về cách thức đạt được hiệu suất máy tính trong thời kỳ hậu Định luật Moore” lại chủ yếu dựa trên sự khéo léo của con người một cách thú vị. Đặc điểm này có vẻ hơi khó đoán định để thiết lập một định luật mới, nhưng Dally tin rằng biểu đồ ấn tượng dưới đây đánh dấu sự khởi đầu của Định luật Huang.

Theo một cuộc tọa đàm tại hội nghị Hot Chips 2023 gần đây của Dally, biểu đồ trên cho thấy hiệu suất suy luận AI của GPU đã tăng gấp 1000 lần trong 10 năm qua. Điều thú vị là, không giống như Định luật Moore, việc thu nhỏ tiến trình (process) có rất ít tác động đến sự phát triển của Định luật Huang, Nhà khoa học trưởng của NVIDIA cho biết.

Dally nhắc lại mức tăng 16 lần đạt được từ việc thay đổi cách xử lý số cơ bản của GPU NVIDIA. Một sự đột phá lớn khác đã được thực hiện với sự xuất hiện của kiến trúc NVIDIA Hopper, sử dụng Transformer Engine. Hopper sử dụng sự kết hợp động giữa dấu phẩy động 8-bit và 16-bit, và phép toán số nguyên để mang lại bước nhảy vọt về hiệu suất gấp 12,5 lần – cùng với việc tiết kiệm điện năng – và điều đó đã được xác thực. Trước đó, NVIDIA Ampere đã giới thiệu ‘cấu trúc thưa thớt’ để tăng hiệu suất gấp 2 lần. Những tiến bộ như NVLink và công nghệ mạng của NVIDIA đã củng cố thêm những thành tựu ấn tượng này.
Một trong những tuyên bố của Dally đáng ngạc nhiên nhất là mức tăng kép gấp 1000 lần về hiệu suất suy luận AI, tương phản hoàn toàn với mức tăng do việc cải tiến tiến trình. Trong thập kỷ qua, khi GPU NVIDIA chuyển từ tiến trình 28nm sang 5nm, các cải tiến về tiến trình bán dẫn “chỉ chiếm 2,5 lần tổng mức lợi ích thu được”, Dally khẳng định tại Hot Chips.
Với những khái niệm như “sự khéo léo, nỗ lực phát minh và xác thực các nhân tố hoàn toàn mới” đằng sau nó, Định luật Huang sẽ tiếp tục phát triển như thế nào? Rất may, Dally cho biết ông và nhóm của mình vẫn nhìn thấy “một số cơ hội” để tăng tốc quá trình xử lý suy luận AI. Các giải pháp cần khai phá bao gồm “đơn giản hóa hơn nữa cách biểu diễn các con số, tạo ra sự thưa thớt hơn trong các mô hình AI và thiết kế các mạch truyền dẫn và bộ nhớ tốt hơn”.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- Bước vào kỷ nguyên trợ lý AI cá nhân – so sánh chi tiết NVIDIA RTX Spark và DGX Spark
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?