
Các mô hình ngôn ngữ lớn (LLM) đang chen sâu vào cuộc sống của chúng ta. Ý tôi không phải là theo nghĩa đen (ít nhất là trong thời điểm hiện tại), mà đúng hơn là có vẻ như mỗi ngày đều có vô số mô hình và ứng dụng mới xuất hiện. Sự khởi đầu tưởng chừng chỉ là dịch vụ độc quyền được quảng cáo rầm rộ của OpenAI giờ đây đã thực sự bùng nổ, chúng trở thành nền tảng mã nguồn mở sau khi bản phát hành LLaMA của Meta và các mô hình nguồn mở mới nhất được công bố.
Nếu bạn giống tôi, có thể bạn cũng cảm thấy mình muốn sử dụng LLM nguồn mở. Với cá nhân tôi, một phần công việc hàng ngày là phân tích và đánh giá các mô hình khác nhau. Vì vậy tôi muốn tìm một cách hiệu quả để triển khai LLM và giao diện của nó để có thể khai thác hết các khả năng.
Trước khi đi sâu vào chi tiết việc triển khai, dưới đây là những yêu cầu chính mà tôi đưa ra:
- Dễ truy cập: Việc truy cập mô hình phải được thực hiện thông qua giao diện người dùng web (web UI)
- Tính bền vững: Thiết lập có thể được khởi động lại sau khi reboot laptop/cloud instance của mình
- Khả năng mở rộng: Tôi muốn có thể mở rộng thông lượng của giải pháp bằng cách bổ sung thêm sức mạnh tính toán để chạy mô hình
- Tính khả dụng: Mặc dù không phải là yêu cầu bắt buộc, nhưng tôi muốn có thể cung cấp các đảm bảo dịch vụ tối thiểu bằng cách bảo vệ thiết lập khỏi lỗi node
- Tính hoàn hảo: Lý tưởng nhất là tôi muốn gõ một lệnh duy nhất để tự động chạy mọi thứ.
Những gì tôi nghĩ ra phục vụ tốt cho tôi. Tuy nhiên, tôi cho rằng nó cũng có thể giúp ích cho bất kỳ ai muốn thiết lập một dịch vụ tương tự cho mục đích sử dụng cá nhân hoặc thậm chí với các tổ chức. Nếu bạn là một trong số đó, hãy đọc tiếp.
Giải pháp của tôi dựa vào Kubernetes để xử lý tất cả các công việc nặng nhọc của cơ sở hạ tầng, bao gồm tính ổn định của trạng thái, tính khả dụng và khả năng mở rộng. Ngoài ra, phương pháp này mang lại cho tôi sự linh hoạt hoàn toàn trong việc triển khai local, lên cloud hoặc dịch vụ K8s được quản lý (managed).
Đối với mục đích minh hoạ, ứng dụng sử dụng GPT-2 từ Hugging Face, nhưng bạn có thể chọn bất kỳ model nào khác thay cho nó. Tôi đã chọn LLM này vì các model lớn hơn cần nhiều tài nguyên hơn và có thể không hoạt động tốt trên laptop tầm trung.
Cuối cùng, giao diện người dùng của ứng dụng được triển khai với Gradio. Gradio tự động tạo một giao diện web đầy đủ chức năng đơn giản, phù hợp với model nguồn mở đã chọn.
Điều kiện tiên quyết
Để bắt đầu, bạn cần có khả năng tạo các container image. Tôi đang sử dụng Docker cho việc đó nhưng bạn có thể sử dụng bất kỳ giải pháp thay thế nào. Bạn có thể tìm thấy hướng dẫn tải xuống và cài đặt Docker tại đây.
Tiếp theo, bạn sẽ cần quyền truy cập vào cluster K8s thông qua lệnh ‘kubeconfig’ và có vai trò ‘cluster-admin’. Tôi thích sử dụng kind để tạo và quản lý cluster dockerized local của mình, nhưng đó chỉ là tôi. Bạn chắc chắn có thể sử dụng công cụ mà bạn đã quen dùng, nhưng nếu bạn muốn thử, chỉ cần làm theo hướng dẫn bắt đầu nhanh về cài đặt tại đây.
Tạo Cluster
Tại thời điểm này, chúng ta có thể tạo cluster tối thiểu của mình, bao gồm control plane và các node worker. Để làm điều đó, trước tiên, hãy tạo file ‘cluster.yaml’ với nội dung sau:
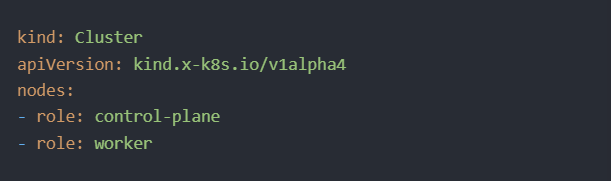
Sau đó, tạo và xuất cluster kind bằng các lệnh này từ shell promt:

Container ứng dụng
Hãy tạo một ứng dụng Python được đóng gói (containerized) – cung cấp giao diện và chạy mô hình GPT-2. Đầu tiên, tạo một file có tên ‘app.py’ với nội dung sau:

Và sau đó là file ‘requirements.txt’:

Tiếp theo, xác định container image của ứng dụng bằng cách thêm file ‘Dockerfile’ mới với nội dung sau:
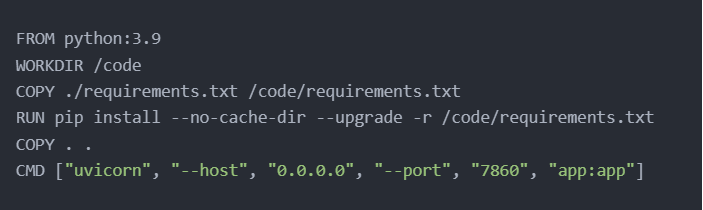
Bây giờ, tạo image bằng cách dán lệnh này vào prompt và chạy nó:

Cuối cùng, tải image vào các node của cluster:

Triển khai ứng dụng và dịch vụ
Bắt đầu bằng cách xác định triển khai của ứng dụng thông qua việc tạo file ‘deployment.yaml’:
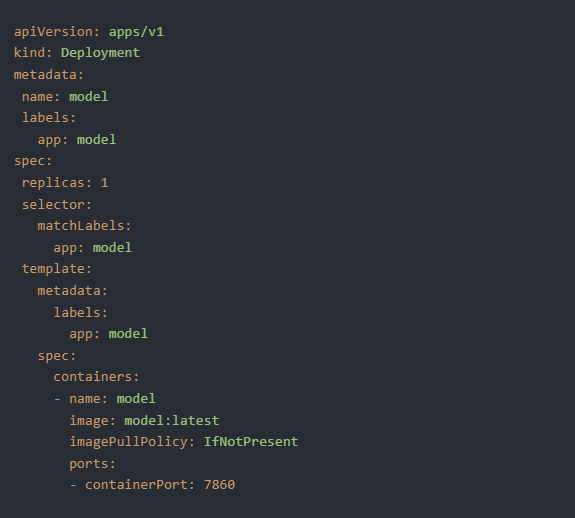
Và áp dụng nó cho cluster K8s:

Bây giờ, xác định dịch vụ bằng cách tạo file ‘service.yaml’:
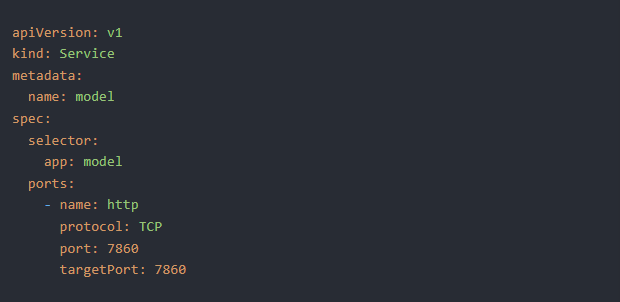
Và một lần nữa, áp dụng nó cho cluster:

Vì quá trình này có thể mất vài phút để hoàn thành, bạn có thể theo dõi tiến trình bằng lệnh sau:

Cuối cùng, nhưng không kém phần quan trọng, bạn cần bật port forwarding cho dịch vụ để có thể truy cập dịch vụ này từ trình duyệt:

Đó là tất cả những gì cần làm để có nó. Bây giờ, bạn có thể trỏ trình duyệt của mình tới http://localhost:7860/ và bắt đầu sử dụng GPT-2 LLM:

Tất nhiên, bạn có thể tùy chỉnh bản dựng để sử dụng các mô hình mã nguồn mở khác, chẳng hạn như LLaMA của Meta hoặc Falcon của TII.
Theo Run:ai
Bài viết liên quan