
Đa GPU trong Deep Learning là gì?
Học sâu là một tập hợp con của học máy, không dựa vào dữ liệu có cấu trúc để phát triển các mô hình dự đoán chính xác. Phương pháp này sử dụng các mạng thuật toán được mô hình hóa sau các mạng thần kinh trong não để chắt lọc và tương quan một lượng lớn dữ liệu. Bạn càng cung cấp nhiều dữ liệu cho mạng của mình, mô hình càng trở nên chính xác.
Bạn có thể huấn luyện chức năng cho các mô hình học sâu bằng các phương pháp xử lý tuần tự. Tuy nhiên, lượng dữ liệu cần thiết và thời gian xử lý dữ liệu khiến việc đào tạo các mô hình mà không xử lý song song trở nên không thực tế nếu không muốn nói là không thể. Xử lý song song cho phép xử lý nhiều đối tượng dữ liệu cùng một lúc, giảm đáng kể thời gian đào tạo. Quá trình xử lý song song này thường được thực hiện thông qua việc sử dụng các đơn vị xử lý đồ họa (GPU).
GPU là bộ xử lý chuyên biệt được tạo ra để xử lý song song. Các bộ xử lý này có thể mang đến lợi thế đáng kể so với CPU truyền thống, ví dụ như tốc độ cao hơn đến 10 lần. Thông thường, nhiều GPU được tích hợp vào một hệ thống bên cạnh CPU. Trong khi CPU có thể xử lý các tác vụ tổng quát hoặc phức tạp hơn thì GPU có thể xử lý rất nhiều tác vụ nhỏ, có tính lặp lại cao.
Trong bài này, bạn sẽ tìm hiểu về:
- Chiến lược Deep Learning phân tán đa GPU
- Multi GPU hoạt động như thế nào trong các Framework Deep Learning phổ biến?
- TensorFlow Nhiều GPU
- GPU đa năng PyTorch
- Mô hình triển khai đa GPU
- Máy chủ GPU
- Cụm GPU
- Kubernetes với GPU
Chiến lược học sâu đa GPU
Khi nhiều GPU được thêm vào hệ thống của bạn, bạn cần xây dựng đặc tính song song trong các quy trình học sâu của mình. Có hai phương pháp chính để bổ sung tính song song — mô hình và dữ liệu.

Model parallelism – Song song hóa Mô hình
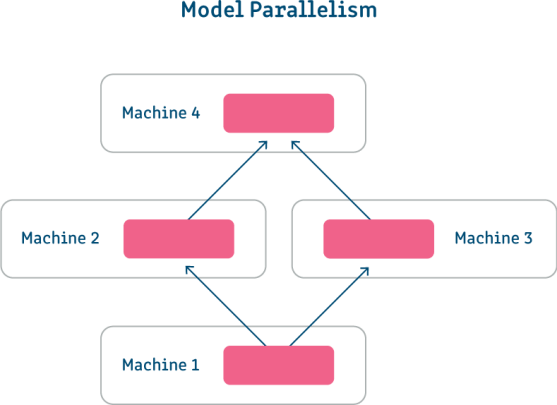
Song song hóa mô hình là một phương pháp bạn có thể sử dụng khi các tham số của bạn quá lớn so với giới hạn bộ nhớ của bạn. Sử dụng phương pháp này, bạn chia các quy trình đào tạo mô hình của mình trên nhiều GPU và thực hiện song song từng quy trình (như minh họa trong hình ảnh bên dưới) hoặc theo chuỗi. Tính song song của mô hình sử dụng cùng một tập dữ liệu cho từng phần trong mô hình của bạn và yêu cầu đồng bộ hóa dữ liệu giữa các phần tách.
Song song hóa dữ liệu
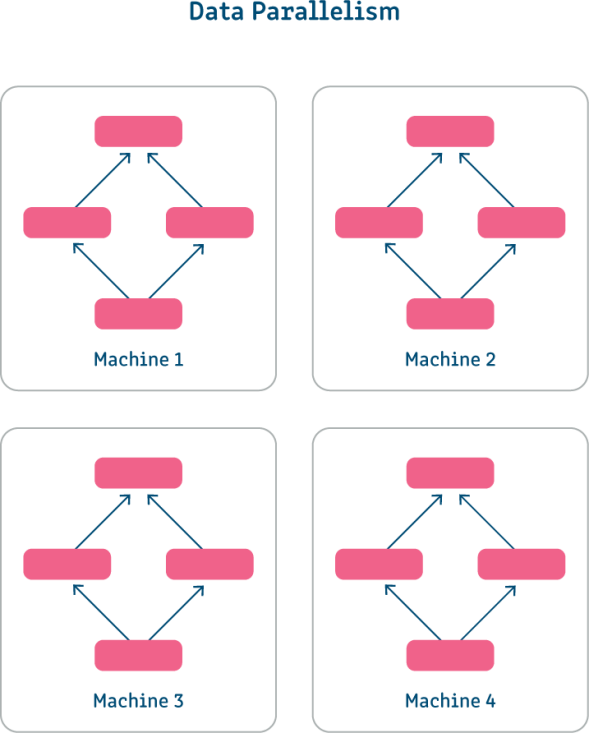
Song song hóa dữ liệu là một phương pháp sử dụng các bản sao mô hình của bạn trên các GPU. Phương pháp này hữu ích khi kích thước lô mà mô hình của bạn sử dụng quá lớn để phù hợp với một máy duy nhất hoặc khi bạn muốn tăng tốc quá trình đào tạo. Với tính song song của dữ liệu, mỗi bản sao của mô hình của bạn được đào tạo đồng thời trên một tập hợp con của tập dữ liệu của bạn. Sau khi hoàn thành, kết quả của các mô hình được kết hợp và đào tạo tiếp tục như bình thường.
Multi GPU hoạt động như thế nào trong các Framework Deep Learning phổ biến?
TensorFlow đa GPU
TensorFlow là một framework mã nguồn mở do Google tạo ra mà bạn có thể sử dụng để thực hiện các hoạt động học máy. Thư viện này bao gồm nhiều mô hình và thuật toán học máy và học sâu mà bạn có thể sử dụng làm cơ sở cho quá trình đào tạo của mình. Nó cũng bao gồm các phương pháp tích hợp để đào tạo phân tán bằng GPU.
Thông qua API, bạn có thể sử dụng phương pháp tf.distribute.Strategy để phân phối hoạt động của mình trên GPU, TPU hoặc các máy tính. Phương pháp này cho phép bạn tạo và hỗ trợ nhiều phân khúc người dùng cũng như chuyển đổi giữa các chiến lược phân tán một cách dễ dàng.
Hai chiến lược bổ sung mở rộng phương pháp phân phối là MirroredStrategy và TPUStrategy. Cả hai điều này đều cho phép bạn phân phối khối lượng công việc của mình, cái trước phân phối trên nhiều GPU và cái sau trên nhiều Bộ xử lý Tensor (TPU). TPU là các đơn vị có sẵn thông qua Google Cloud Platform được tối ưu hóa đặc biệt để đào tạo với TensorFlow.
Cả hai phương pháp này đều sử dụng gần như cùng một quy trình song song dữ liệu, được tóm tắt như sau:
- Tập dữ liệu của bạn được phân đoạn để dữ liệu được phân phối đồng đều nhất có thể.
- Bản sao mô hình của bạn được tạo và gán cho GPU. Sau đó, một tập hợp con của tập dữ liệu được gán cho bản sao đó.
- Tập hợp con cho mỗi GPU được xử lý và độ dốc được tạo ra.
- Độ dốc từ tất cả các bản sao mô hình được tính trung bình và kết quả được sử dụng để cập nhật mô hình ban đầu.
- Quá trình lặp lại cho đến khi mô hình của bạn được đào tạo đầy đủ.
Tìm hiểu thêm trong hướng dẫn của chúng tôi về TensorFlow nhiều GPU và Keras nhiều GPU
PyTorch đa GPU
PyTorch là một framework khoa học mã nguồn mở dựa trên Python. Bạn có thể sử dụng nó để đào tạo các mô hình học máy bằng cách sử dụng tính toán tensor và GPU. Framework này hỗ trợ đào tạo phân tán thông qua chương trình phụ trợ torch.distributed.
Với PyTorch, có ba lớp song song (hoặc phân phối) mà bạn có thể thực hiện với GPU. Bao gồm các:
- DataParallel — cho phép bạn phân phối các bản sao mô hình trên nhiều GPU trong một máy. Sau đó, bạn có thể sử dụng các mô hình này để xử lý các tập hợp con khác nhau của tập dữ liệu của mình.
- DistributedDataParallel —mở rộng lớp DataParallel để cho phép bạn phân phối các bản sao mô hình trên các máy ngoài GPU. Bạn cũng có thể sử dụng lớp này kết hợp với model_parallel để thực hiện song song cả mô hình và dữ liệu.
- model_parallel —cho phép bạn chia các mô hình lớn thành nhiều GPU với quá trình đào tạo từng phần diễn ra trên mỗi GPU. Điều này yêu cầu đồng bộ hóa dữ liệu đào tạo giữa các GPU do các hoạt động được thực hiện tuần tự.
Mô hình triển khai đa GPU
Có ba mô hình triển khai chính mà bạn có thể sử dụng khi triển khai các hoạt động máy học sử dụng nhiều GPU. Mô hình bạn sử dụng phụ thuộc vào nơi tài nguyên của bạn được lưu trữ và quy mô hoạt động của bạn.
Máy chủ GPU
Máy chủ GPU là máy chủ tích hợp GPU kết hợp với một hoặc nhiều CPU. Khi khối lượng công việc được gán cho các máy chủ này, CPU hoạt động như một trung tâm quản lý trung tâm cho GPU, phân phối tác vụ và thu thập kết quả đầu ra khi có sẵn.
Cụm GPU
Cụm GPU là cụm máy tính có các nút chứa một hoặc nhiều GPU. Các cụm này có thể được hình thành từ các bản sao của cùng một GPU (đồng nhất) hoặc từ các GPU khác nhau (không đồng nhất). Mỗi nút trong một cụm được kết nối thông qua một kết nối để cho phép truyền dữ liệu.
Kubernetes với nhiều GPU
Kubernetes là một nền tảng mã nguồn mở mà bạn có thể sử dụng để sắp xếp và tự động hóa việc triển khai vùng chứa. Nền tảng này cung cấp hỗ trợ cho việc sử dụng GPU theo cụm để cho phép tăng tốc khối lượng công việc, bao gồm cả học sâu.
Khi sử dụng GPU với Kubernetes, bạn có thể triển khai các cụm không đồng nhất và chỉ định tài nguyên của mình, chẳng hạn như yêu cầu bộ nhớ. Bạn cũng có thể theo dõi các cụm này để đảm bảo hiệu suất đáng tin cậy và tối ưu hóa việc sử dụng GPU.
Đa GPU với Run:AI
Run:AI tự động hóa việc quản lý tài nguyên và điều phối khối lượng công việc cho cơ sở hạ tầng máy học. Với Run:AI, bạn có thể tự động chạy nhiều thử nghiệm deep learning nếu cần trên cơ sở hạ tầng đa GPU.
Dưới đây là một số khả năng bạn có được khi sử dụng Run:AI:
- Khả năng hiển thị nâng cao —tạo ra một hệ thống chia sẻ tài nguyên hiệu quả bằng cách tập hợp các tài nguyên điện toán GPU.
- Không còn tắc nghẽn nữa —bạn có thể thiết lập hạn ngạch tài nguyên GPU được đảm bảo để tránh tắc nghẽn và tối ưu hóa việc thanh toán.
- Mức độ kiểm soát cao hơn —Run:AI cho phép bạn tự động thay đổi phân bổ tài nguyên, đảm bảo mỗi công việc đều nhận được tài nguyên cần thiết vào bất kỳ thời điểm nào.
Run:AI đơn giản hóa quy trình cơ sở hạ tầng máy học, giúp các nhà khoa học dữ liệu tăng tốc năng suất và chất lượng mô hình của họ.
Tìm hiểu thêm về Cơ sở hạ tầng đa GPU
Tìm hiểu thêm một số chủ đề về cách làm việc với cơ sở hạ tầng đa GPU:
Tensorflow với nhiều GPU: Chiến lược và Hướng dẫn
TensorFlow là một trong những khuôn khổ phổ biến nhất cho đào tạo học máy và học sâu. Nó bao gồm một loạt các chức năng và công cụ tích hợp để giúp bạn đào tạo hiệu quả, bao gồm cả việc cung cấp các phương pháp đào tạo phân tán với GPU.
Trong bài viết này, bạn sẽ tìm hiểu TensorFlow là gì và cách bạn có thể thực hiện đào tạo phân tán bằng các phương pháp TensorFlow. Bạn cũng sẽ thấy hai hướng dẫn ngắn gọn cho biết cách sử dụng TensorFlow được phân phối với công cụ ước tính và Horovod.
Đọc thêm: Tensorflow với nhiều GPU: Cách thực hiện đào tạo phân tán
Keras Multi GPU: Hướng dẫn thực hành
Keras là API học sâu mà bạn có thể sử dụng để thực hiện đào tạo phân tán nhanh với nhiều GPU. Đào tạo phân tán với GPU cho phép bạn thực hiện các nhiệm vụ đào tạo song song, do đó phân phối các nhiệm vụ đào tạo mô hình của bạn trên nhiều tài nguyên. Bạn có thể làm điều đó thông qua mô hình song song hoặc thông qua dữ liệu song song. Bài viết này giải thích cách Keras multi GPU hoạt động và xem xét các mẹo để quản lý các giới hạn của đào tạo multi GPU với Keras.
Tìm hiểu kiến thức cơ bản về đào tạo phân tán, cách sử dụng Keras Multi GPU và các mẹo để quản lý các giới hạn của Keras với nhiều GPU.
Đọc thêm: Keras Multi GPU: Hướng dẫn thực hành
PyTorch Multi GPU: Giải thích 4 kỹ thuật
PyTorch cung cấp gói thư viện dựa trên Python và nền tảng học sâu cho các tác vụ điện toán khoa học. Tìm hiểu bốn kỹ thuật mà bạn có thể sử dụng để tăng tốc tính toán tensor với các kỹ thuật đa GPU của PyTorch—song song dữ liệu, song song dữ liệu phân tán, song song mô hình và đào tạo đàn hồi.
Tìm hiểu cách tăng tốc tính toán tensor deep learning với 3 kỹ thuật đa GPU—song song dữ liệu, song song dữ liệu phân tán và song song mô hình.
Đọc thêm: PyTorch Multi GPU: Giải thích về 4 kỹ thuật
Cách xây dựng cụm GPU của bạn: Tùy chọn phần cứng và quy trình
Cụm GPU là một nhóm máy tính có bộ xử lý đồ họa (GPU) trên mỗi nút. Nhiều GPU cung cấp sức mạnh tính toán tăng tốc cho các tác vụ tính toán cụ thể, chẳng hạn như xử lý hình ảnh và video, mạng thần kinh đào tạo và các thuật toán máy học khác.
Tìm hiểu cách xây dựng cụm GPU cho nghiên cứu AI/ML và khám phá các tùy chọn phần cứng bao gồm GPU cấp trung tâm dữ liệu và máy chủ GPU quy mô lớn.
Đọc thêm: Cách xây dựng cụm GPU của bạn: Tùy chọn phần cứng và quy trình
GPU Kubernetes: Lập lịch cho GPU tại chỗ hoặc trên EKS, GKE và AKS
Kubernetes là một công cụ điều phối vùng chứa rất phổ biến, có thể được triển khai tại chỗ, trên đám mây và trong các môi trường kết hợp.
Tìm hiểu cách lên lịch tài nguyên GPU với Kubernetes, hiện hỗ trợ GPU NVIDIA và AMD. GPU Kubernetes tự lưu trữ hoặc khai thác tài nguyên GPU trên các dịch vụ Kubernetes được quản lý dựa trên đám mây.
Đọc thêm: GPU Kubernetes: Lập lịch cho GPU tại chỗ hoặc trên EKS, GKE và AKS
Lập lịch trình GPU: Các tùy chọn là gì?
Đơn vị xử lý đồ họa (GPU) là một chip điện tử hiển thị đồ họa bằng cách thực hiện nhanh các phép tính toán học. GPU sử dụng xử lý song song để cho phép một số bộ xử lý xử lý các phần khác nhau của một tác vụ.
Tìm hiểu những thách thức của việc lên lịch GPU và cách lên lịch khối lượng công việc trên GPU bằng Kubernetes, Hashicorp Nomad và Microsoft Windows 10 DirectX.
Đọc thêm: Lập lịch trình GPU: Tùy chọn là gì?
CPU so với GPU: Kiến trúc, ưu và nhược điểm và các trường hợp sử dụng đặc biệt
Bộ xử lý đồ họa (GPU) là bộ xử lý máy tính thực hiện các phép tính nhanh để hiển thị hình ảnh và đồ họa. CPU là bộ xử lý bao gồm các cổng logic xử lý các lệnh cấp thấp trong hệ thống máy tính.
Tìm hiểu về kiến trúc CPU và GPU, ưu và nhược điểm cũng như cách sử dụng CPU/GPU cho các trường hợp sử dụng đặc biệt như máy học và điện toán hiệu năng cao (HPC).
Đọc thêm: CPU so với GPU: Kiến trúc, ưu và nhược điểm và các trường hợp sử dụng đặc biệt
Tự động điều chỉnh siêu tham số trên nhiều GPU
Trong bài đăng này, chúng tôi sẽ xem xét vai trò quan trọng của siêu tham số và điều chỉnh siêu tham số trong việc thiết kế và đào tạo mạng máy học. Việc chọn các giá trị siêu tham số tối ưu ảnh hưởng trực tiếp đến kiến trúc và chất lượng của mô hình. Quá trình quan trọng này cũng là một trong những nhiệm vụ khó khăn, tẻ nhạt và phức tạp nhất trong đào tạo máy học.
Đọc thêm: Tự động điều chỉnh siêu tham số trên nhiều GPU
Nguồn Run:AI
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA hiện đang cung cấp những dòng GPU nào?
- Hướng dẫn lựa chọn GPU phù hợp cho AI, Machine Learning
- Cải thiện khả năng làm mát GPU trong hạ tầng AI
- Tôi có cần CPU kép không?
- Đánh giá GPU máy trạm: Nvidia RTX 6000 Ada Generation