
NVIDIA Grace CPU là CPU đầu tiên cho trung tâm dữ liệu được phát triển bởi NVIDIA. Nó được xây dựng theo tiêu chuẩn cao nhất để tạo ra các vi xử lý siêu tiên tiến, mạnh mẽ nhất trên thế giới.
Được thiết kế để cung cấp hiệu suất tuyệt vời và tiết kiệm năng lượng và đáp ứng nhu cầu của các tác vụ trung tâm dữ liệu hiện đại, đẩy mạnh các kỹ thuật cao như tạo ra các bản sao kỹ thuật số của các đối tượng, trò chơi đám mây, đồ họa, AI và tính toán cao hiệu suất (HPC), NVIDIA Grace CPU có 72 nhân CPU Armv9 cung cấp tập lệnh Arm Scalable Vector Extensions phiên bản hai (SVE2) và có khả năng mở rộng ảo hóa với tính năng ảo hóa lồng nhau và hỗ trợ S-EL2.


NVIDIA Grace CPU cũng tuân thủ các quy chuẩn Arm sau: RAS v1.1 Generic Interrupt Controller (GIC) v4.1 Memory Partitioning and Monitoring (MPAM) System Memory Management Unit (SMMU) v3.1

Grace CPU được xây dựng để kết hợp với NVIDIA Hopper GPU để tạo ra NVIDIA Grace CPU Superchip cho việc huấn luyện AI, suy luận và HPC tại quy mô lớn, hoặc kết hợp với một CPU Grace khác để xây dựng một CPU cao hiệu suất đáp ứng nhu cầu của các tác vụ HPC và đám mây tính toán.
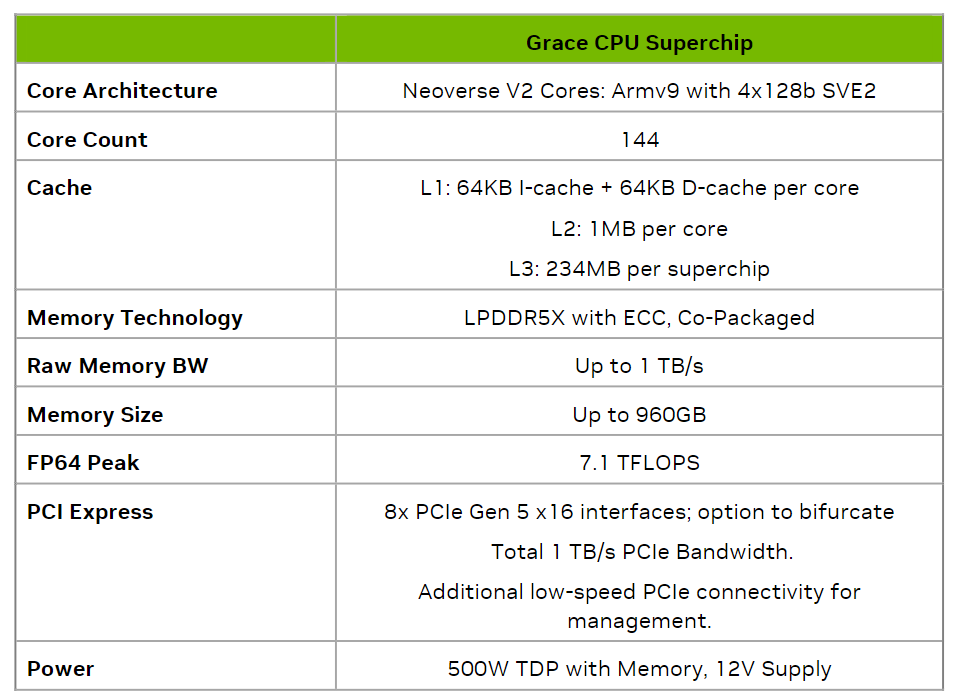
Kết nối chip đến chip với tốc độ cao NVLink-C2C
Cả Grace Hopper và Grace Superchips đều được kích hoạt bởi kết nối chip đến chip tốc độ cao NVIDIA NVLink-C2C, trở thành cầu nối cho việc truyền thông của superchip. NVLink-C2C mở rộng NVIDIA NVLink dùng để kết nối nhiều GPU trong một máy chủ và, với NVLink Switch System, nhiều nút GPU.
Với 900 GB/s dung lượng band dọc bidirectional giữa các die trên gói, NVLink-C2C cung cấp 7 lần dung lượng band của một liên kết PCIe Gen 5 x16 (cùng dung lượng band có sẵn giữa NVIDIA Hopper GPUs khi sử dụng NVLink) với thời gian trễ thấp hơn. NVLink-C2C cũng chỉ cần 1,3 picojoules/bit được truyền, đây là hơn 5 lần hiệu suất năng lượng so với PCIe Gen 5.
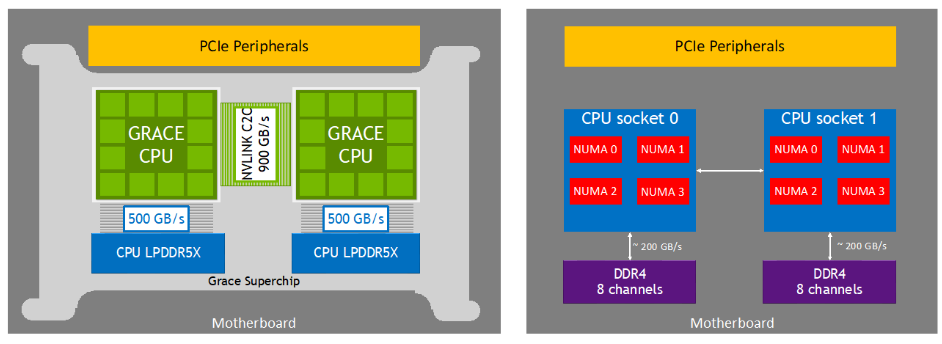
NVLink-C2C cũng là một kết nối tổng thể, cho phép tổng thể khi lập trình một nền tảng CPU tổng thể bằng cách sử dụng Grace CPU Superchip, cũng như mô hình lập trình đa dạng với Grace Hopper Superchip. Grace CPU cố gắng đạt đến các tiêu chuẩn hệ thống của Arm để cung cấp tương thích với hệ điều hành và phần mềm sẵn có, và Grace CPU sẽ nhận lợi thế từ cấu trúc phần mềm Arm của NVIDIA từ đầu.
Grace CPU cũng tuân thủ kế hoạch Arm Server Base System Architecture (SBSA) để hỗ trợ các giao diện phần cứng và phần mềm tiêu chuẩn. Ngoài ra, để cho phép quá trình khởi động theo tiêu chuẩn trên hệ thống dựa trên Grace CPU, Grace CPU đã được thiết kế để hỗ trợ Arm Server Base Boot Requirements (SBBR). Về phân chia cache và băng thông, cũng như theo dõi băng thông, Grace CPU cũng hỗ trợ Arm Memory Partitioning and Monitoring (MPAM).
Grace CPU cũng bao gồm các Đơn vị Giám sát Hiệu suất của Arm, cho phép giám sát hiệu suất của các lõi CPU và các hệ thống con khác trong kiến trúc hệ thống trên một chiếc (SoC). Điều này cho phép sử dụng các công cụ tiêu chuẩn, chẳng hạn như Linux perf, để thực hiện điều tra về hiệu suất.
Bộ nhớ đồng bộ của Grace Hopper Superchip Kết hợp Grace CPU với GPU Hopper, NVIDIA Grace Hopper Superchip mở rộng mô hình lập trình CUDA Unified Memory được giới thiệu đầu tiên trong CUDA 8.0.
NVIDIA Grace Hopper Superchip giới thiệu Bộ nhớ Đồng bộ với bảng trang được chia sẻ, cho phép Grace CPU và GPU Hopper chia sẻ không gian địa chỉ và cả bảng trang với một ứng dụng CUDA.
GPU Hopper cũng có thể truy cập các phân bổ bộ nhớ có thể trang hoá. Grace Hopper Superchip cho phép lập trình viên sử dụng các bộ phân bổ hệ thống để phân bổ bộ nhớ GPU, bao gồm khả năng trao đổi con trỏ đến bộ nhớ malloc với GPU.
NVLink-C2C cho phép hỗ trợ hợp lý nội tại giữa Grace CPU và GPU Hopper, mở ra tiềm năng đầy đủ cho các từng điểm hợp lý C++ được giới thiệu đầu tiên trong CUDA 10.2.
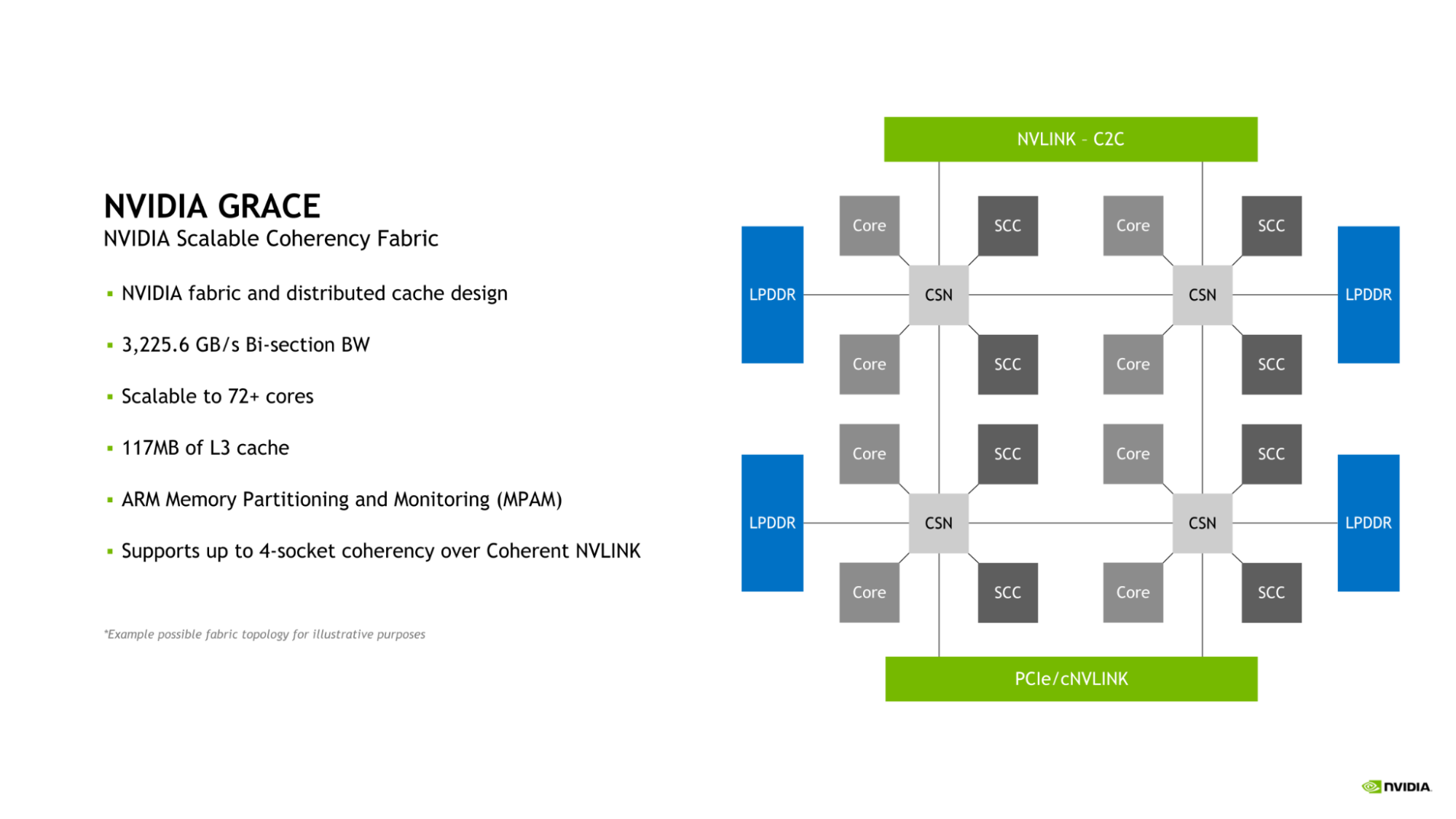
Mạng tương thích NVIDIA Scalable Coherency Fabric
Grace CPU giới thiệu mạng tương thích NVIDIA Scalable Coherency Fabric (SCF). Được thiết kế bởi NVIDIA, SCF là một mạng vải và cache phân tán được thiết kế để mở rộng theo nhu cầu của trung tâm dữ liệu. SCF cung cấp 3,2 TB/giây độ rộng băng thông phân nửa để đảm bảo chuyển đổi dữ liệu giữa NVLink-C2C, CPU cores, bộ nhớ và các IO hệ thống.
Một Grace CPU bao gồm 72 CPU cores và 117MB cache, nhưng SCF được thiết kế để mở rộng ngoài cấu hình này. Khi hai Grace CPU được kết hợp để tạo thành một Grace Superchip, số lượng CPU cores và cache L3 tăng lên 144 và 234MB, tương ứng.

CPU cores và phân đoạn SCF Cache (SCCs) được phân bố trên toàn bộ mạng. Cache Switch Nodes (CSNs) điều hướng dữ liệu qua mạng vải và dịch vụ như các giao diện giữa CPU cores, bộ nhớ cache và phần còn lại của hệ thống, cho phép cao độ rộng băng thông.
Hỗ trợ phân chia và giám sát bộ nhớ Grace CPU cung cấp tính năng Hỗ trợ Phân chia và Giám sát Tài nguyên Hệ thống Bộ nhớ (MPAM), đó là tiêu chuẩn Arm cho việc phân chia cả bộ nhớ cache và tài nguyên bộ nhớ.

MPAM thực hiện bằng cách gán các ID phân vùng (PARTID) cho yêu cầu trong hệ thống. Thiết kế này cho phép các tài nguyên như dung lượng cache và băng thông bộ nhớ được phân chia hoặc giám sát dựa trên PARTID tương ứng của chúng.
Bộ nhớ Cache SCF trong Grace CPU hỗ trợ cả việc phân chia dung lượng cache và băng thông bộ nhớ sử dụng MPAM. Ngoài ra, các Nhóm Giám sát Hiệu suất (PMGs) cũng có thể được sử dụng để giám sát sử dụng tài nguyên.
Tăng cường băng thông và hiệu suất năng lượng với hệ thống bộ nhớ Để cung cấp băng thông và hiệu suất năng lượng tuyệt vời, Grace CPU sử dụng giao diện bộ nhớ LPDDR5X 32 kênh. Điều này cung cấp dung lượng bộ nhớ lên đến 512 GB và băng thông bộ nhớ lên đến 546 GB/s.
Bộ nhớ mở rộng của GPU
Một tính năng quan trọng của NVIDIA Grace Hopper Superchip là sự giới thiệu của bộ nhớ mở rộng cho GPU (EGM). Bằng cách cho phép bất kỳ GPU Hopper nào được kết nối từ mạng NVLink lớn hơn để truy cập bộ nhớ LPDDR5X được kết nối với CPU Grace trong NVIDIA Grace Hopper Superchip, hệ thống bộ nhớ sẵn có cho GPU được mở rộng rất nhiều.
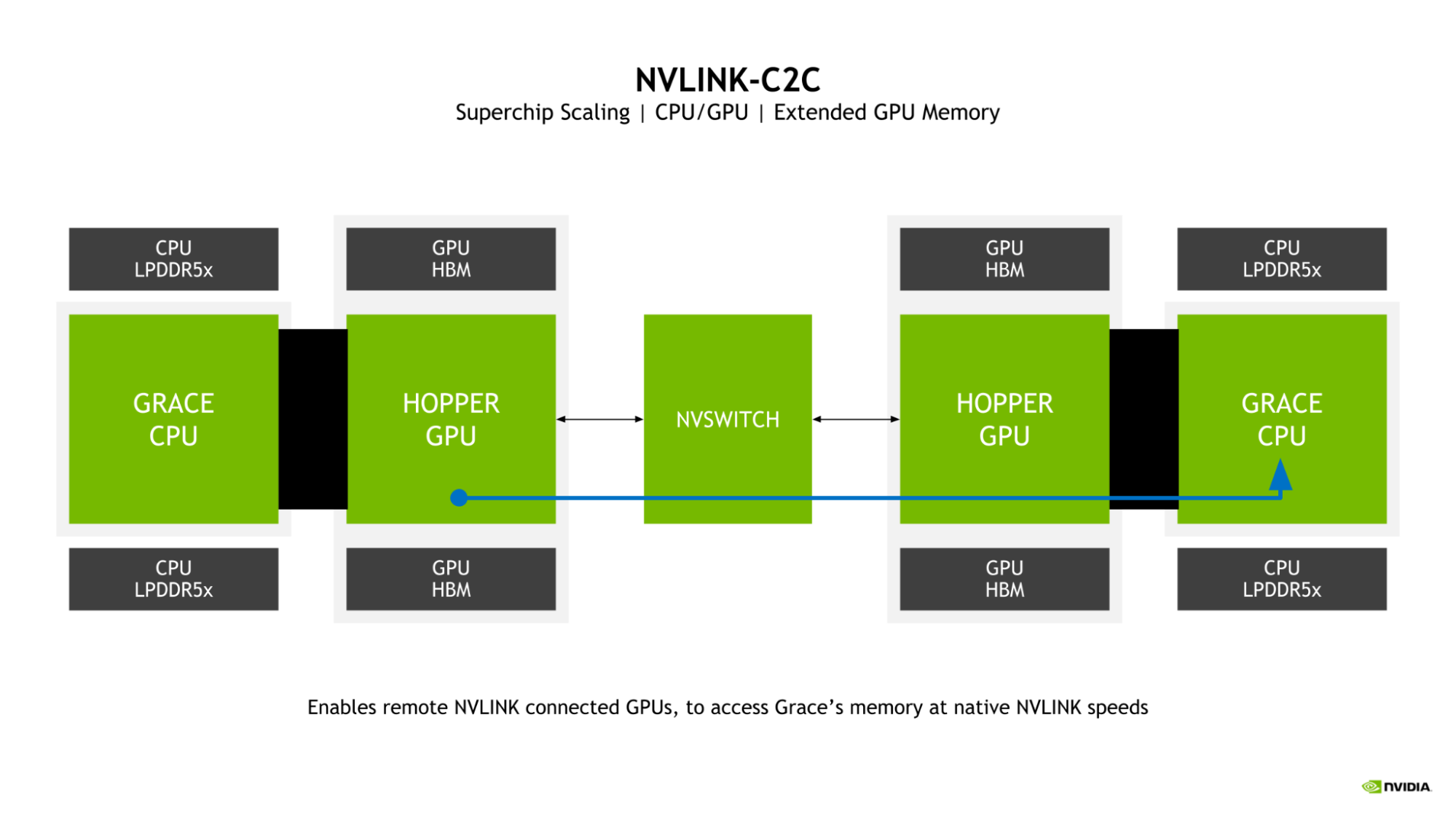
Băng thông NVLink giữa GPU và GPU và NVLink-C2C hai chiều được phù hợp trong một superchip, điều này cho phép GPU Hopper truy cập bộ nhớ CPU Grace với tốc độ NVLink gốc.
Để cân bằng tốc độ và hiệu suất năng lượng, LPDDR5X được chọn cho Grace CPU Chọn sử dụng LPDDR5X cho Grace CPU được điều hành bởi nhu cầu đạt được cân bằng tốt nhất giữa tốc độ, hiệu suất năng lượng, dung lượng và chi phí cho các tác vụ AI và HPC lớn.
Mặc dù một hệ thống bộ nhớ HBM2e có 4 địa điểm có thể cung cấp tốc độ và hiệu suất năng lượng tốt, nó sẽ làm việc với chi phí hơn 3 lần mỗi gigabyte so với DDR5 hoặc LPDDR5X. Ngoài ra, một cấu hình như vậy sẽ bị giới hạn dung lượng chỉ là 64 GB, đó là một phần tám của dung lượng tối đa có sẵn cho Grace CPU với LPDDR5X.
So sánh với một thiết kế DDR5 8 kênh truyền thống hơn, hệ thống bộ nhớ LPDDR5X của Grace CPU cung cấp tới 53% tốc độ hơn và rất hiệu quả năng lượng, chỉ cần tám phần của sức mạnh mỗi gigabyte.
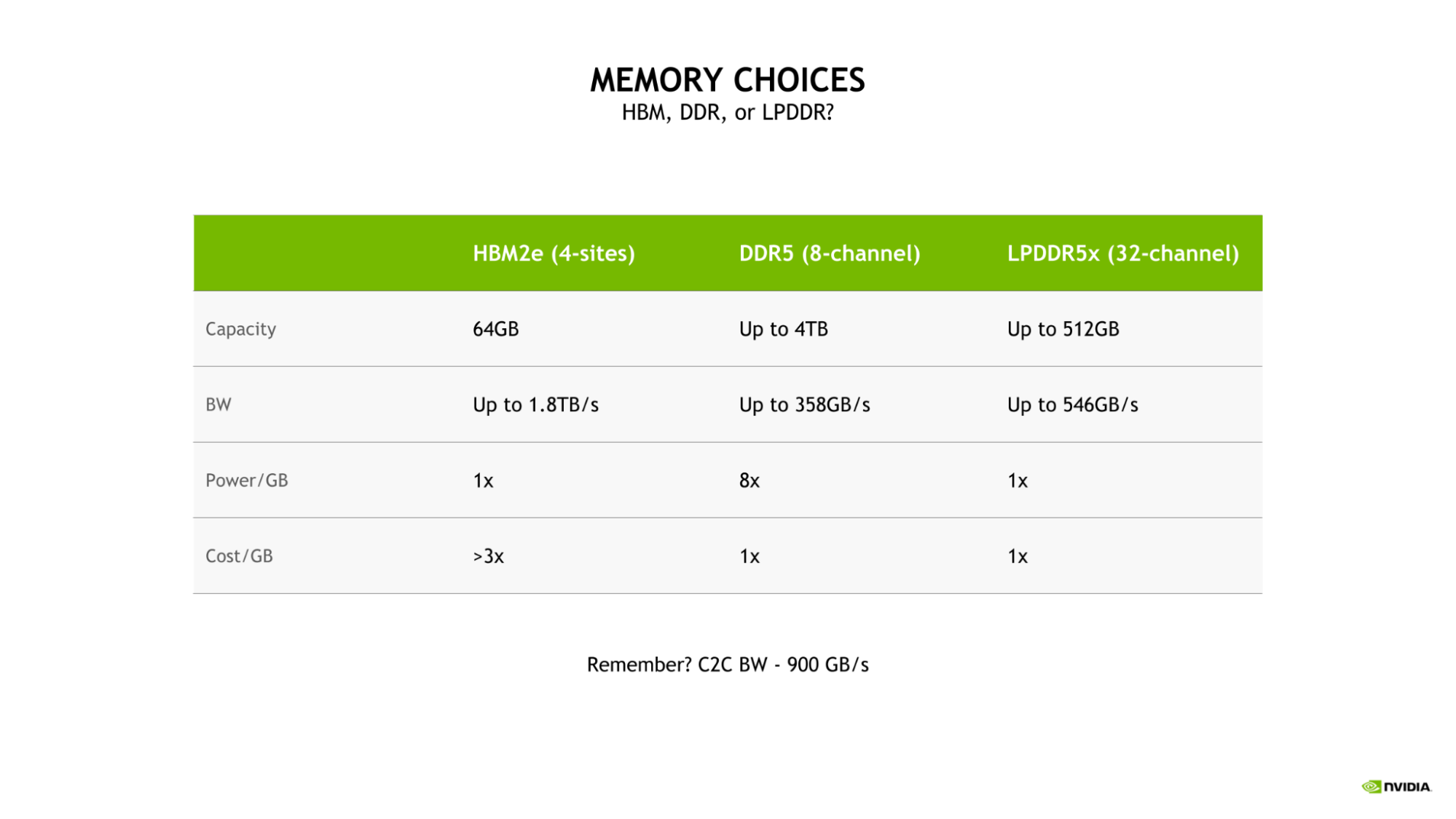
LPDDR5X có hiệu suất năng lượng tuyệt vời giúp phân bổ thêm nguồn năng lượng cho các tài nguyên tính toán như lõi CPU hoặc các đồng nghiệp dòng GPU (SMs).
I/O của NVIDIA Grace CPU
Grace CPU bao gồm một bộ I/O cao tốc để phục vụ nhu cầu của trung tâm dữ liệu hiện đại. SoC Grace CPU cung cấp tối đa 68 đường kết nối PCIe và tối đa 4 liên kết PCIe Gen 5 x16. Mỗi liên kết PCIe Gen 5 x16 cung cấp tối đa 128 GB/s băng thông hai chiều và có thể được chia thành hai liên kết PCIe Gen 5 x8 để kết nối thêm.
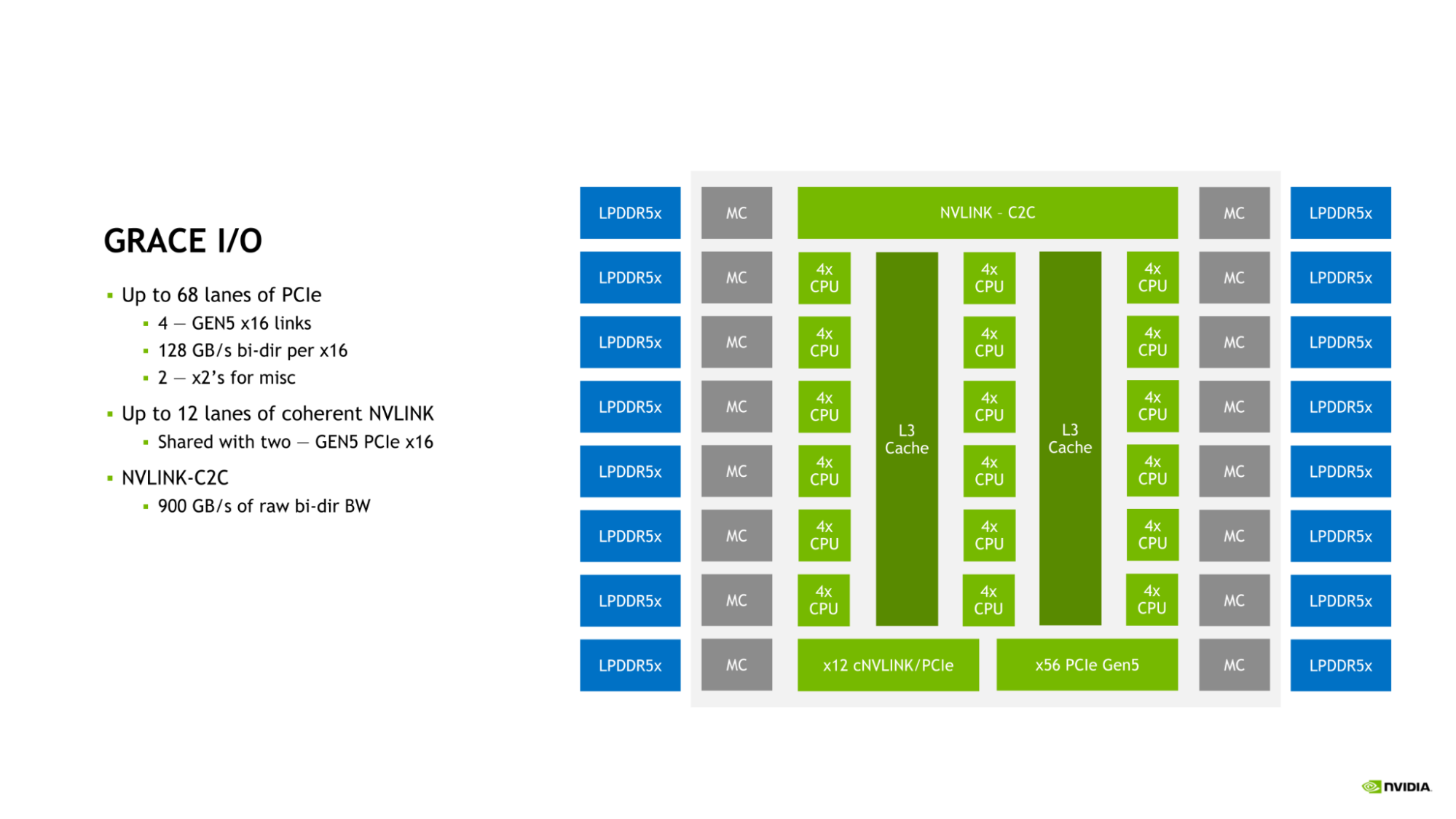
Bộ nối tiếp của NVIDIA Grace CPU Bộ vi xử lý NVIDIA Grace CPU tích hợp một bộ nối tiếp cao tốc để phục vụ nhu cầu của trung tâm dữ liệu hiện đại. Bộ vi xử lý SoC của Grace CPU cung cấp lên đến 68 đường kết nối PCIe và lên đến 4 liên kết PCIe Gen 5 x16. Mỗi liên kết PCIe Gen 5 x16 cung cấp lên đến 128 GB/s băng thông hai chiều và có thể được chia thành hai liên kết PCIe Gen 5 x8 cho thêm sự kết nối.
Kết hợp của NVLink, NVLink-C2C và PCIe Gen 5 cung cấp cho Grace CPU một bộ tùy chọn nối tiếp đa dạng và băng thông đủ để mở rộng hiệu suất trong trung tâm dữ liệu hiện đại.
Hiệu suất của NVIDIA Grace CPU NVIDIA Grace CPU được thiết kế để cung cấp hiệu suất tính toán tuyệt vời trong cả cấu hình chứa một chip và cấu hình Superchip, với điểm ước tính SPECrate2017_int_base lần lượt là 370 và 740. Những ước tính này trước khi sản xuất được dựa trên sử dụng Bộ biên dịch GNU (GCC).
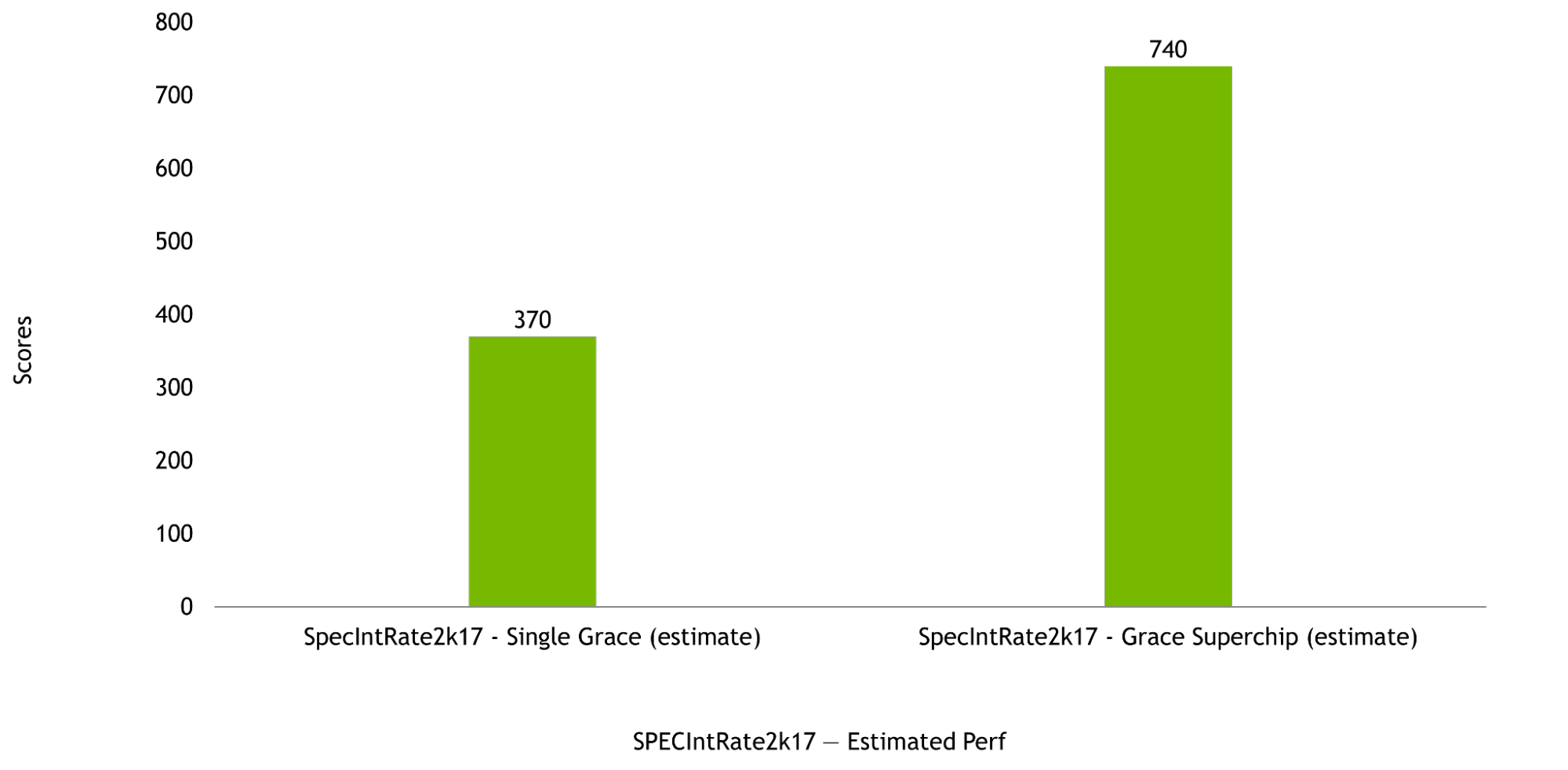
Băng thông bộ nhớ là yếu tố quan trọng cho các công việc mà CPU Grace được thiết kế, và trong chuỗi đánh giá Stream, một CPU Grace được dự đoán sẽ cung cấp đến 536 GB/s băng thông đã thực hiện, tượng trưng cho hơn 98% của băng thông lý thuyết tối đa của chip.
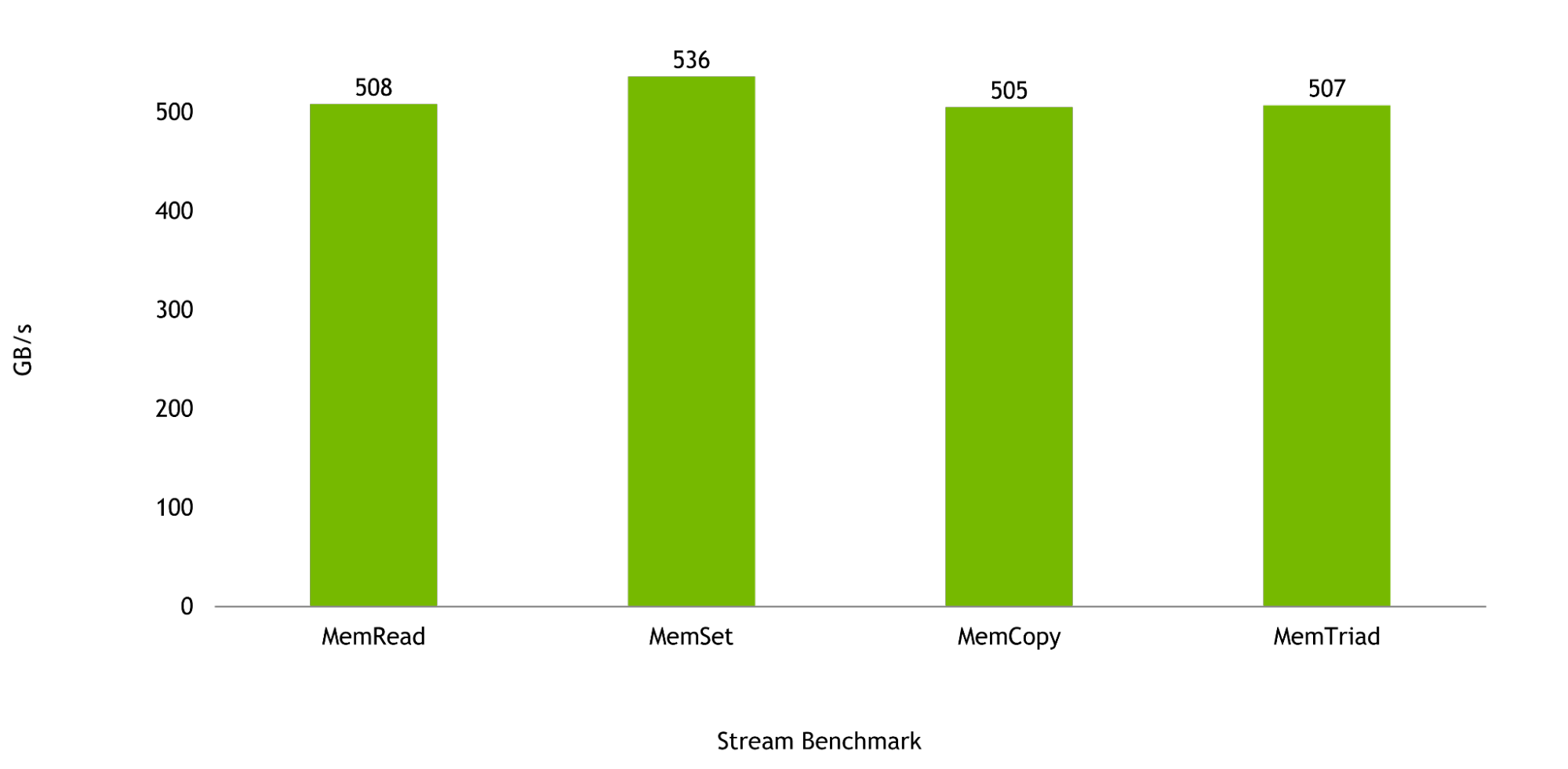
Và cuối cùng, băng thông giữa GPU Hopper và CPU Grace là quan trọng để tối đa hóa hiệu suất của Superchip Grace Hopper. Đọc và ghi bộ nhớ từ GPU đến CPU được dự đoán là 429 GB/s và 407 GB/s, tương ứng, tượng trưng cho hơn 95% và hơn 90% của tốc độ truyền tải đơn hướng lý thuyết tối đa của NVLink-C2C. Tổng cộng, hiệu suất đọc và ghi được dự đoán là 506 GB/s, tượng trưng cho hơn 92% băng thông bộ nhớ lý thuyết tối đa có sẵn cho một SoC NVIDIA Grace CPU đơn.
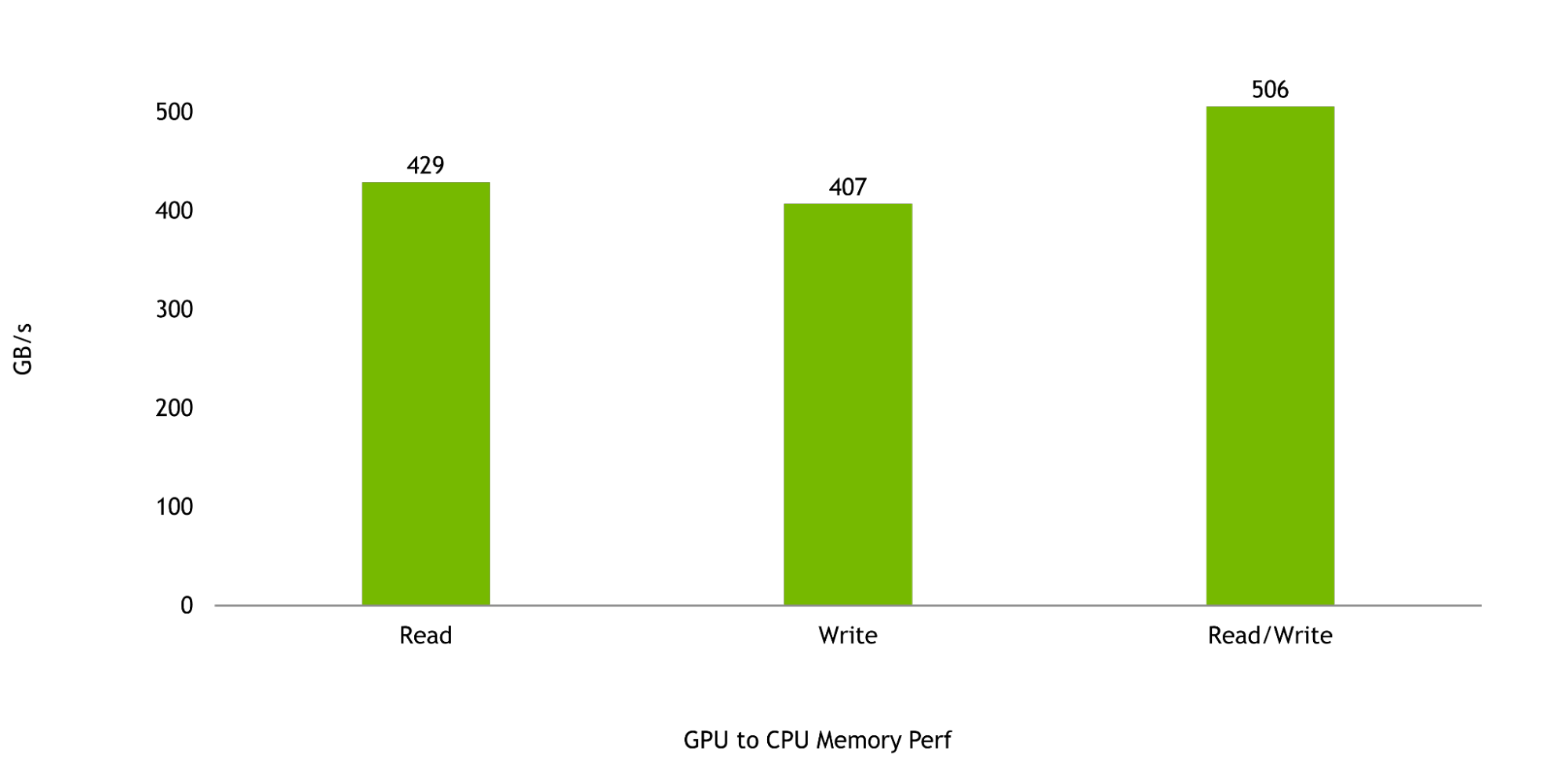
NVIDIA Grace CPU Superchip sẽ mang lại những lợi ích tuyệt vời.
Với 144 nhân và 1TB/s băng thông bộ nhớ, NVIDIA Grace CPU Superchip sẽ cung cấp hiệu năng tuyệt vời cho các ứng dụng tính toán cao cấp. Các ứng dụng tính toán cao cấp yêu cầu những nhân có hiệu năng tốt nhất, băng thông bộ nhớ cao nhất và dung lượng bộ nhớ phù hợp mỗi nhân để tăng tốc độ hoàn thành.

NVIDIA đang hợp tác với những khách hàng lớn trong lĩnh vực tính toán cao cấp, supercomputing, hyperscale và đám mây cho Grace CPU Superchip. Dự kiến Grace CPU và Grace Hopper Superchip sẽ có sẵn trong nửa đầu của năm 2023.
Để biết thêm chi tiết về NVIDIA Grace Hopper Superchip và NVIDIA Grace CPU Superchip, hãy truy cập tại đây.
 Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Nhất Tiến Chung (NTC) hiện là nhà cung cấp các giải pháp hạ tầng CNTT, điện toán hiệu năng cao (HPC) và lưu trữ cho AI. Chúng tôi là đối tác NPN cấp Elite của NVIDIA cho các hệ thống DGX và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và kết nối mạng tốc độ cao từ hãng Mellanox (thuộc NVIDIA).
Với vai trò là đối tác NPN chính thức của NVIDIA, chúng tôi có thể giúp bạn có được các sản phẩm GPU cao cấp nhất của NVIDIA như L4, L40S, H200, H200 NVL, B200,…, đặc biệt là với thực trạng khan hiếm GPU do các hạn chế thương mại về nhập khẩu GPU như hiện nay.
Bạn muốn trở thành đối tác bán hàng NVIDIA của NTC?
Bài viết liên quan
- NVIDIA RTX PRO 4500 Blackwell Server Edition: Bước nhảy vọt từ thế hệ L4 cho hạ tầng AI suy luận hiệu năng cao
- NVIDIA NGC‑ready Low‑latency Edge AI: Giải pháp cho Retail, Manufacturing và Smart Cities
- So sánh sức mạnh của máy tính AI DGX Spark với các card GPU máy trạm chuyên nghiệp của NVIDIA
- Từ Orin đến Thor: Bước nhảy vọt kiến trúc của NVIDIA JetPack 7.0 và tương lai của robot hình người
- Tại sao gọi NVIDIA DGX Spark là Siêu máy tính AI cá nhân?
- Cơ chế quản lý bộ nhớ trên các nền tảng phần cứng nhất quán – Hardware-coherent