











Kiến trúc tham khảo cho EsgynDB® dựng trên Supermicro 2U 4-Node TwinPro2

Sơ lược
Supermicro và Esgyn đã hợp tác để đưa ra thị trường một công cụ dữ liệu lớn (Big Data Appliance) khai thác thông tin insights về doanh nghiệp nhanh hơn bằng EsgynDB, một cơ sở dữ liệu hội tụ cho Big Data được tối ưu hóa để chạy trên nền tảng SuperServer TwinPro2 SuperServer 2U 4 Node. Big Data Appliance này hoàn thiện với lớp phần mềm được cài đặt sẵn, cấu hình trước sẵn sàng và tinh chỉnh cho các tình huống sử dụng để hiện đại hóa các pool dữ liệu (“data lakes”) và tăng tốc việc khai thác giá trị của IoT, mang lại hiệu suất cao nhất theo các chuẩn benchmark như YCSB, TPC-C và TPC-DS. Trên thực tế, tất cả 99 truy vấn của chuẩn benchmark TPC-DS đều được vượt qua và EsgynDB là sản phẩm duy nhất trên Hadoop có thể làm được điều này. EsgynDB được tích hợp chặt chẽ với Hadoop, hỗ trợ HDFS, HBase, ORC và Parquet. Bộ appliance được hoàn chỉnh để sẵn sàng chạy hoặc có thể xem như một building-block và mở rộng theo bất kỳ kích thước cluster nào cần thiết.
Việc áp dụng công cụ Dữ liệu lớn Supermicro-Esgyn làm giảm đáng kể sự phức tạp trong việc triển khai một giải pháp Dữ liệu lớn để hiện đại hóa các “data lakes”, hỗ trợ phân tích cả hot và cold data từ IoT và tạo một nền tảng cơ sở dữ liệu tập trung cho các nhu cầu trong tương lai bao gồm hỗ trợ dữ liệu đa dạng và OLTP, ODS, BI và các workload cho việc phân tích.
EsgynDB, với giao diện ANSI SQL hoàn thiện trên Hadoop, chạy trên nền tảng SuperServer, có thể được sử dụng như một phương tiện không chỉ để thực hiện nhanh chóng các thử nghiệm hoặc thiết lập PoC các dự án một cách nhanh chóng, mà còn dùng để thể hiện rõ ràng khả năng tăng tốc ROI từ các khoản đầu tư cho Big Data.
Đối tượng mục tiêu: Tài liệu này dành cho người ra quyết định, chuyên gia kiến trúc hệ thống và giải pháp, quản trị hệ thống và người dùng có kinh nghiệm quan tâm đến việc giảm thời gian thiết kế hoặc đơn giản hóa việc mua một kiến trúc dữ liệu lớn chứa cả hai thành phần Supermicro và Esgyn. Kiến thức trung bình về Apache™ Hadoop® và cơ sở hạ tầng mở rộng là cần thiết.
Mục đích tài liệu: Mục đích của tài liệu này là để mô tả gói thiết bị chuẩn doanh nghiệp EsgynDB trên cụm Supermicro.
Giới thiệu
Kiến trúc tham chiếu này được tạo ra để hỗ trợ thiết kế và triển khai nhanh chóng phần mềm EsgynDB Enterprise trên cơ sở hạ tầng Supermicro. Nó cũng có ý nghĩa xác định các thành phần phần mềm và phần cứng cần có trong một giải pháp để đơn giản hóa quá trình mua sắm. Thiết bị Supermicro được đề xuất đã được kiểm tra cẩn thận với nhiều loại cấu hình I/O, CPU, mạng và bộ nhớ cho khối lượng công việc giao dịch và phân tích.
Tổng quan về giải pháp
Các giải pháp Supermicro và Esgyn cho phép mọi người rút ra những hiểu biết kinh doanh mới từ Big Data bằng cách cung cấp một nền tảng để lưu trữ, quản lý và xử lý dữ liệu theo quy mô. Tài liệu tham khảo này cung cấp kiến trúc một số cấu hình được tối ưu hóa hiệu suất để triển khai cụm EsgynDB Enterprise trên cơ sở hạ tầng Supermicro. Khi so sánh với các thế hệ trước đó, các cấu hình mới giúp giảm đáng kể độ phức tạp và tăng giá trị và hiệu suất. Các cấu hình bao gồm các phiên bản Linux, Hadoop được cài đặt sẵn, cấu hình sẵn và đã trải qua thử nghiệm, EsgynDB trên nền tảng máy chủ Supermicro – một máy chủ được tối ưu hóa cao với kết hợp đúng các đặc tính hiệu suất tính toán và lưu trữ để hệ thống xử lý song song, như Hadoop. Các cấu hình được chọn là kết quả của rất nhiều thử nghiệm và tối ưu hóa được thực hiện bởi các kỹ sư Esgyn dẫn đến bộ phần mềm, trình điều khiển phù hợp, phần firmware và phần cứng để mang lại hiệu suất khối lượng công việc tuyệt vời.
Các giải pháp Dữ liệu lớn của Supermicro / Esgyn cung cấp hiệu suất tuyệt vời và tính sẵn sàng cao, với phần mềm, dịch vụ, cơ sở hạ tầng và quản lý tích hợp – tất cả được phân phối dưới dạng một cấu hình đã được thử nghiệm để giảm đáng kể chi phí triển khai và chi phí vận hành.
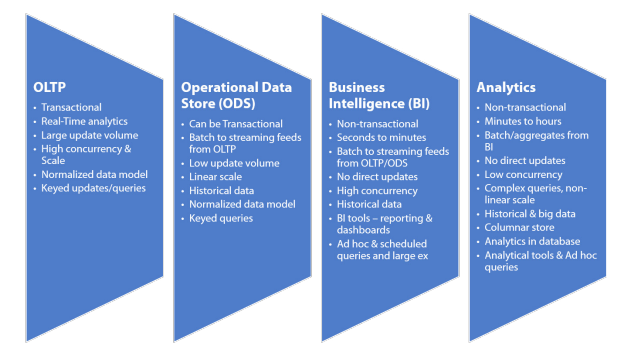
Tại sao cần đến Supermicro-EsgynDB?
Bộ công cụ Big Data hoàn chỉnh với các lớp phần mềm được cài đặt sẵn, được cấu hình sẵn và điều chỉnh trước từ hệ điều hành đến Hadoop, đến EsgynDB, tất cả đã được thử nghiệm và được chứng nhận bởi Esgyn Labs, hoàn tất trên nền tảng phần cứng Supermicro bao gồm máy chủ, bộ nhớ, lưu trữ và bộ kết nối mạng, tất cả được chọn cho tối ưu hiệu suất và độ tin cậy cao nhất, nhắm mục tiêu cho việc sử dụng các trường hợp hiện đại hóa các pool dữ liệu và tăng tốc giá trị cho IoT. Nó được đóng gói thành một khối hoàn chỉnh và được tích hợp khả năng dự phòng cho tính sẵn sàng cao, được định vị là một điểm hội tụ nền tảng cho một dải các workload DBMS từ xử lý giao dịch trực tuyến (OLTP-Online Transactional Processing) để lưu trữ dữ liệu vận hành (ODS-Operational Data Store) vào dữ liệu nhập kho (EDW-Enterprise Data Warehouse) cho doanh nghiệp thông minh (BI-Business Intelligence) để xử lý phân tích trực tuyến (OLAP-Online Analytical Processing). Có sẵn trên cơ sở dùng thử miễn phí lên đến 45 ngày.
Kiến trúc máy chủ Supermicro TwinPro
Kiến trúc Supermicro TwinPro dựa trên công nghệ Twin đã được chứng minh của Supermicro để cung cấp thông lượng, lưu trữ, kết nối mạng, I/O, bộ nhớ và khả năng xử lý đặc biệt trong một thiết kế 2U. Khách hàng có thể tối ưu hóa hơn nữa các giải pháp Supermicro để giải quyết các yêu cầu CNTT có tính thách thức cao và hưởng lợi từ việc cắt giảm tổng chi phí sở hữu (TCO).
Các giải pháp TwinPro được thiết kế để triển khai và bảo trì đơn giản hóa, và được lắp ráp với chất lượng cao nhất để đảm bảo hoạt động liên tục ngay cả ở mức tối đa. Khách hàng trong doanh nghiệp cao cấp, trung tâm dữ liệu, HPC và Điện toán đám mây, môi trường nhận được lợi thế cạnh tranh lớn nhất từ tài nguyên trung tâm dữ liệu với Supermicro TwinPro.
- Hiệu năng: Thế hệ bộ xử lý Intel Xeon mới nhất nâng cao đáng kể hiệu suất của các giải pháp Supermicro TwinPro. Với tối đa 28 core mỗi socket, 6 kênh DDR4 và tối đa 2TB DDR4-2666 trong 16 khe DIMM, tốc độ bộ nhớ sẽ đạt tối đa 2666 MHz. Hệ thống TwinPro của Supermicro X11 và X10 là tối ưu hóa để cung cấp hiệu suất đáng kinh ngạc cho môi trường hiệu suất cao và sẽ xử lý khối lượng công việc phức tạp một cách dễ dàng.
- Tính linh hoạt: Tính linh hoạt cao và các tùy chọn mạng khác nhau là các tính năng chính của TwinPro. Mỗi node bao gồm Mô-đun I/O Supermicro (SIOM) để kết nối mạng, các tùy chọn mở rộng 1G, 10G, 25G, 40G hoặc 100G và 2 Low-profile PCI-E 3.0 x16, mang đến cho khách hàng sự linh hoạt, bao gồm các add-on card khi họ cần bổ sung thiết bị.
- Hiệu quả: Dòng sản phẩm Supermicro Twin Architecture cung cấp mật độ sắp xếp dầy đặc nhất cho ngành công nghiệp máy chủ, hiệu quả nhất. So với truyền thống TwinPro tăng gấp đôi hiệu suất của một hệ thống 2U 4 node để giảm không gian lắp đặt trong trung tâm dữ liệu và bao gồm nguồn dự phòng Titanium Level Digital (96%) cho hiệu quả công suất tối đa.


Tổng quan về doanh nghiệp EsgynDB
EsgynDB cung cấp một giá trị độc nhất bằng cách hỗ trợ toàn bộ database workload ở quy mô Dữ liệu lớn trên một nền tảng cơ sở dữ liệu hội tụ, đơn giản hóa bức tranh cơ sở dữ liệu, giảm hoặc loại bỏ việc di chuyển dữ liệu và giảm độ trễ tổng thể.
Các workload được hỗ trợ của EsgynDB bao gồm:
• Online transaction processing (OLTP)
• Operational Data Store (ODS)
• Data Warehousing (EDW)
• Business Intelligence (BI)
• Online Analytical Processing (OLAP)
EsgynDB giảm chi phí ETL (Extract, Transform, Load) bằng cách chuyển đổi dữ liệu ELT (Extract, Load, Transform) trong cơ sở dữ liệu. Đó là kiến trúc xử lý song song cực lớn (MPP- Massively
Parallel Processing), đảm bảo cho các chỉ tiêu SLA nghiêm ngặt nhất có thể được thực hiện bằng cách thực hiện các truy vấn song song. Một công cụ SQL ANSI cho phép tính di động của ứng dụng gia tăng, đã được chứng minh để xử lý hàng petabyte dữ liệu đồng thời ở nhiều doanh nghiệp đòi hỏi khắt khe trong hơn 20 năm qua.
Dưới đây là tổng quan về các khả năng của EsgynDB:
- Hỗ trợ SQL toàn diện và đầy đủ chức năng cho phép các công ty sử dụng lại và tận dụng các kỹ năng SQL hiện có để cải thiện năng suất của nhà phát triển.
- Dễ dàng tích hợp với các thành phần hệ sinh thái khác để mở rộng nguồn dữ liệu có sẵn từ các hệ thống phụ phát trực tuyến để phân tích…
- Hỗ trợ dữ liệu Hot và Cold.
- Làm việc với dữ liệu có cấu trúc, bán cấu trúc và không cấu trúc từ các nguồn dữ liệu khác nhau tất cả trong một truy vấn SQL.
- Khả năng tương tác với các ứng dụng mới hoặc hiện có và các công cụ của bên thứ 3 thông qua hỗ trợ cho ODBC(Open Database Connectivity) và JDBC( Java Database Connectivity) tiêu chuẩn.
- Cung cấp bảo vệ giao dịch ACID(atomicity, consistency, isolation, and durability) đầy đủ trên nhiều hàng, bảng và các câu lệnh SQL.
- Công cụ cơ sở dữ liệu song song tinh vi và cực lớn hỗ trợ các truy vấn phức tạp tại một thời điểm và thông lượng cao.
- Trình tối ưu hóa đẳng cấp thế giới với khả năng điều chỉnh mức độ song song cho phù hợp truy vấn cá nhân và quy mô hoặc số lượng dữ liệu được truy vấn.
- Hỗ trợ đầy đủ các giao dịch phân tán hoạt động active-active trên khắp các trung tâm dữ liệu để mở rộng quy mô khối lượng công việc với các giao dịch bị mất ở tỉ lệ bằng không khi phục hồi sau thảm họa (Trong phiên bản EsgynDB Advanced ).
- Hỗ trợ multi-tenant để tối ưu hóa tốt nhất các tài nguyên có sẵn để đáp ứng SLA của các khách hàng khác nhau (tính năng ở phiên bản nâng cao của EsgynDB).
Khả năng rộng lớn này, được Gartner gọi là Hybrid Transactional and Analytical Processing (HTAP) và với Forrester là Translytics, làm cho EsgynDB phù hợp lý tưởng với phạm vi các trường hợp sử dụng, bao gồm:
- Internet of Things (IoT)
- Data Lakes
Các workload cho Big Data
Các workload Hadoop điển hình có thể được phân loại thành 4 loại khác nhau: Batch, NonInteractive, Interactive, và Operational. Các loại này khác nhau rất nhiều về mặt đáp ứng thời gian kỳ vọng, đồng thời, cũng như lượng dữ liệu được xử lý.
Hadoop được định vị tốt để giải quyết BI và phân tích khối lượng công việc. Hỗ trợ hoạt động khối lượng công việc trên Hadoop là một loại thị trường Hadoop mới nổi và Esgyn là công ty duy nhất có thể làm điều này. Theo truyền thống, các khối lượng công việc này đã được giảm xuống trong lĩnh vực cơ sở dữ liệu quan hệ truyền thống. Nhưng có sự quan tâm và áp lực ngày càng tăng đối với nắm lấy khối lượng công việc này trên Hadoop do lợi ích của Hadoop giảm đáng kể chi phí, giảm sự khóa phần cứng của nhà cung cấp và khả năng mở rộng quy mô liên tục đến khối lượng công việc lớn hơn và toàn bộ dữ liệu.
Các đổi mới của EsgynDB được xây dựng dựa trên các lớp phần mềm Big Data
EsgynDB được thiết kế để xây dựng và tận dụng các mô-đun lõi Apache Hadoop và HBase.
Các ứng dụng hoạt động sử dụng EsgynDB trong suốt đạt được các lợi thế của Hadoop về hiệu suất, khả năng mở rộng, độ co giãn, tính sẵn có, v.v. Hình 1 mô tả một tập hợp con của ngăn xếp phần mềm Hadoop. Các mục màu xanh lá cây được EsgynDB đặc biệt tận dụng, chẳng hạn như HBase và HDFS. Trong ngăn xếp này, EsgynDB thêm (các mục màu cam) trình điều khiển ODBC / JDBC, Phần mềm cơ sở dữ liệu EsgynDB và hệ thống con quản lý giao dịch phân tán (DTM) để bảo vệ giao dịch.
EsgynDB mang đến sự đổi mới Hadoop trong các lĩnh vực chính :
- Triển khai SQL ANSI đầy đủ tính năng có dịch vụ cơ sở dữ liệu có thể truy cập thông qua kết nối ODBC / JDBC tiêu chuẩn.
- Trình diễn mối quan hệ trong lược đồ SQL.
- Bảo vệ giao dịch ACID phân tán.
- Hỗ trợ giao dịch phân tán tích cực đầy đủ trong trung tâm dữ liệu, để mở rộng quy mô đọc và viết, hỗ trợ truy cập nội bộ và tuân thủ các quy tắc an toàn, không bị mất giao dịch khi thảm họa xảy ra.
- Thời gian phản hồi của người thực hiện đối với các giao dịch bao gồm cả đọc và ghi.
- Tối ưu hóa song song cho cả khối lượng công việc báo cáo giao dịch và hoạt động.

Thành phần giải pháp
Cấu hình cụm cluster
Một số yếu tố chính đã được xem xét trước khi thiết kế thiết bị dữ liệu lớn EsgynDB. Các tiểu mục sau đây nêu rõ các quyết định thiết kế trong việc tạo cơ sở cấu hình cho các kiến trúc tham khảo.
Hệ điều hành
Red Hat ® Enterprise Linux ®
Khối xử lý (computing)
Khi sizing quy mô xử lý cho cụm EsgynDB Ensterprise Supermicro, tính đồng thời và các loại khối lượng công việc là những cân nhắc quan trọng khác cho số lượng node cần đến. Số lượng node và core phản ánh số lượng xử lý song song có sẵn cho người dùng của các ứng dụng đang chạy trên cluster. Nếu khối lượng công việc điển hình là đồng thời cao với truy vấn ngắn, thì các node có số lượng core ít hơn có thể được chấp nhận. Nếu khối lượng công việc liên quan đến scan dữ liệu lớn, sau đó cần nhiều sức mạnh xử lý hơn. Hiểu được kiểu công việc, tần suất, kế hoạch và đồng thời hiểu điển hình của ứng dụng, lý tưởng nhất là thông qua tạo mẫu khối lượng công việc và truy vấn bất cứ khi nào có thể.
Memory
Khi định cỡ cụm EsgynDB Enterprise Supermicro để sử dụng bộ nhớ, hãy ghi nhớ rằng nhiều quy trình hệ sinh thái Hadoop là các quy trình Java. Do hiệu quả bộ nhớ tối ưu hóa cho JVM, có một hạn chế đáng kể chỉ dưới 32GB, Vượt qua ngưỡng này dẫn đến bộ nhớ ít sử dụng hơn vì biểu diễn bên trong của những điểm thay đổi theo cách tiêu tốn nhiều dung lượng hơn đáng kể. Lập kế hoạch cho các quá trình này để sử dụng mỗi khối có kích thước 16-32GB cho hiệu suất tối ưu trên một cụm lớn. Giảm bộ nhớ cho các thành phần này ảnh hưởng đáng kể đến hiệu suất, vì vậy hãy điều chỉnh cẩn thận và phân tích trước khi chọn một giá trị nhỏ hơn. Người dùng bộ nhớ trong các máy chủ cơ sở dữ liệu EsgynDB dựa trên truy vấn đồng thời và khối lượng công việc
Lưu trữ
Khi định cỡ cụm EsgynDB Enterprise để sử dụng đĩa, đối với các node dữ liệu, SSD chỉ có lợi cho việc viết đồng thời cao. Tuy nhiên, ổ đĩa cứng là đủ, đĩa dữ liệu ổ cứng cấu hình các đĩa dưới dạng lưu trữ được gắn trực tiếp trong cấu hình JBOD (Just a Bunch of Disks).
Phân chia RAID làm chậm HDFS và giảm đồng thời và khả năng phục hồi. Để kiểm soát các node, đĩa dữ liệu có thể được cấu hình là JBOD hoặc RAID1 hoặc RAID10.
Như với sức mạnh xử lý, đĩa là một đơn vị song song. Đối với tổng số đĩa cho mỗi node, nếu khối lượng công việc bao gồm nhiều lần quét lớn, thường có hiệu quả nhất là có nhiều các đĩa nhỏ hơn các đĩa lớn trên mỗi node trên các node dữ liệu. Kiến trúc tham khảo giả định rằng hầu hết khối lượng công việc bao gồm quét lớn. Nén HBase SNAPPY hoặc GZ là đề nghị mạnh mẽ. SNAPPY có ít chi phí CPU hơn, nhưng GZ nén tốt hơn. Mức độ nén rất khác nhau tùy thuộc vào dữ liệu và mô hình khối lượng công việc, nhưng nói chung tính toán được đề xuất giảm khoảng 30% -40%, tùy thuộc vào dữ liệu.
Mạng
Nói chung, 10GigE là tiêu chuẩn để kết nối mạng cho lưu lượng dữ liệu trong cụm EsgynDB. Sử dụng mạng chậm hơn cho luồng dữ liệu có thể ảnh hưởng đáng kể đến hiệu suất. 2 cổng mạng 10GigE cung cấp nhiều thông lượng hơn cho các ứng dụng chuyên sâu I/O.
Nền tảng máy chủ Supermicro
Supermicro TwinPro 2 được thể hiện trong Hình 2 bên dưới, là một lựa chọn tuyệt vời cho nhiệm vụ là máy chủ nền tảng cho node biên, node quản lý và node chính.


Liên hệ hotline
1900 558879
Để được tư vấn về sản phẩm này
Cấu hình mạng
Card mạng 2 port Ethernet 10G : 2 port Ethernet 10Gb với SFP + trên mỗi node
Kiến trúc tham khảo
Các phần sau đây minh họa một tiến trình tham chiếu của các cụm Hadoop từ một rack để cấu hình đa rack.
Kiến trúc Single 2U TwinPro
Kiến trúc tham khảo 2U Supermicro EsgynDB được thiết kế để thực hiện tốt như một thiết kế cụm một rack 2U nhưng cũng là cơ sở cho thiết kế một hệ thống đa rack lớn hơn nhiều. Khi chuyển từ thiết kế 2U đơn sang Multi-2U, người ta có thể chỉ cần thêm các rack vào cụm mà không phải thay đổi bất kỳ thành phần nào trong 2U đơn.
Kiến trúc Multiple 2U TwinPro
Thiết kế multi-2U từ cơ sở thiết kế 1 node đã có sẵn và khả năng mở rộng. Cấu hình node đơn đảm bảo quản lý số lượng cần thiết dịch vụ được đưa ra cho quy mô lớn. Đối với cụm nhiều node 2U, chỉ cần thêm phần rack mở rộng của một cấu hình tương tự.
Các lưu ý về hiệu suất
Thiết bị Supermicro EsgynDB mang lại hiệu suất, quy mô và độ ổn định, cho phép khách hàng triển khai các cụm Supermicro với nhiều node 2U để chạy hàng triệu truy vấn và đồng thời. Các tiêu chuẩn như YCSB, TPC-C và TPC-DS cho thấy EsgynDB là công cụ khối lượng công việc hỗn hợp duy nhất có thể chạy liên tục OLTP, ODS, BI và khối lượng công việc phân tích.
Điều chỉnh / Tối ưu hóa cụm Esgyn
Công nghệ tối ưu hóa đại diện cho một trong những nguồn khác biệt lớn nhất của EsgynDB thay thế
so với các dự án hoặc sản phẩm SQL trên Hadoop. Hai khu vực chính là bản chất mở rộng của trình tối ưu hóa để thích ứng với thay đổi và thêm các cải tiến; độ tinh vi và mức độ phát triển của trình tối ưu hóa để chọn gói tối ưu hóa tốt nhất để thực hiện.
Giới thiệu về Super Micro Computer, Inc.
Supermicro ® (NASDAQ: SMCI), nhà cải tiến hàng đầu về công nghệ máy chủ hiệu suất cao, là nhà cung cấp hàng đầu của máy chủ Building Block Solutions® for Data Center, Cloud Computing, Enterprise IT, Hadoop/Big Data, HPC and Embedded Systems worldwide trên toàn thế giới. Supermicro cam kết bảo vệ môi trường thông qua sáng kiến “We Keep IT Green ®” và cung cấp cho khách hàng các giải pháp tiết kiệm năng lượng, thân thiện với môi trường nhất hiện có trên thị trường.
Website: www.supermicro.com
Về Esgyn
Esgyn là công ty hàng đầu trong các giải pháp Dữ liệu lớn hội tụ, trao quyền cho các doanh nghiệp toàn cầu nhận ra tiềm năng của Dữ liệu lớn. Với cơ sở dữ liệu SQL thích ứng, có thể mở rộng và có khả năng mở rộng nhất cho Big data, Esgyn đang dẫn đầu cách các doanh nghiệp đối phó với sự gia tăng không ngừng quản lý dữ liệu cần tại chỗ và trong đám mây.

