











Hệ thống đào tạo AI hiệu suất cao của Supermicro và Habana

Nhu cầu về điện toán cho đào tạo AI / Học sâu (DL) hiệu suất cao đã tăng gấp đôi sau mỗi 3 tháng kể từ năm 2013 (theo OpenAI) và đang tăng tốc với số lượng ứng dụng và dịch vụ ngày càng tăng dựa trên thị giác máy tính, xử lý ngôn ngữ tự nhiên, hệ thống đề xuất và nhiều hơn nữa. Với nhu cầu như thế, các ngành công nghiệp đang cần các hệ thống đào tạo mang lại hiệu quả cao hơn, chi phí thấp hơn, có tính linh hoạt để cho phép tùy chỉnh và dễ thực hiện cũng như mở rộng hệ thống đào tạo.
Ngoài ra, AI đang trở thành một công nghệ thiết yếu cho các lĩnh vực đa dạng như trợ lý ảo, hoạt động sản xuất, vận hành xe tự hành và hình ảnh y tế PACS. Supermicro đã hợp tác với Habana Labs để giải quyết những yêu cầu ngày càng tăng này. Bộ xử lý Habana Gaudi AI được thiết kế để tối đa hóa thông lượng và hiệu quả đào tạo đồng thời cung cấp cho các nhà phát triển phần mềm và công cụ được tối ưu hóa có quy mô phù hợp với nhiều khối lượng công việc và hệ thống.
Hỗ trợ triển khai bộ xử lý Gaudi là Nền tảng phần mềm Habana SynapseAI, được tạo ra với sự chú ý của các nhà phát triển và nhà khoa học dữ liệu, cung cấp tính linh hoạt và dễ lập trình để giải quyết nhu cầu riêng của người dùng cuối đồng thời cho phép chuyển đổi đơn giản và liền mạch các mô hình hiện có của họ sang Gaudi.
Để tối ưu cho những yêu cầu trên, Habana cùng với Supermicro đã hợp tác và mang đến một hệ thống Đào tạo AI Supermicro X12 Gaudi hiệu suất cao để cho phép tính toán hiệu suất cao cho khối lượng công việc học sâu với tính linh hoạt cao với chi phí đầu tư hợp lý.

Tổng quan về hệ thống đào tạo AI Supermicro X12 Gaudi
Hệ thống đào tạo AI Supermicro X12 Gaudi dựa trên platform SYS-420GH-TNGR, được cung cấp bởi Bộ xử lý học sâu Habana Gaudi, giúp thúc đẩy ranh giới của đào tạo học sâu và có thể mở rộng quy mô lên đến hàng trăm bộ xử lý Gaudi trong một cụm AI. Gaudi là bộ xử lý đào tạo Deep Learning đầu tiên có tích hợp sức mạnh RDMA qua Ethernet hội tụ (RoCE v2) trên chip. Với thông lượng hai chiều lên đến 2 TB/s, các bộ xử lý này đóng một vai trò quan trọng trong giao tiếp giữa các bộ xử lý cần thiết trong quá trình đào tạo. Sự tích hợp nguyên bản này của RoCE cho phép khách hàng sử dụng cùng một công nghệ mở rộng quy mô, cả bên trong máy chủ và tủ rack (mở rộng quy mô) và trên các giá đỡ rack (scale-out). Chúng có thể được kết nối trực tiếp giữa các bộ xử lý Gaudi hoặc thông qua bất kỳ số lượng thiết bị chuyển mạch Ethernet switch
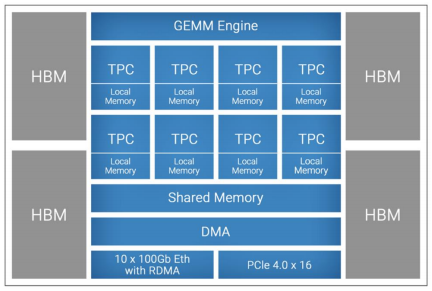
Với khả năng sử dụng máy tính cao cho GEMM, thiết kế hệ thống năng lượng thấp và hỗ trợ Bfloat16 cho phép độ chính xác FP32 với tốc độ đào tạo 16 bit, Hệ thống đào tạo AI Supermicro X12 Gaudi được xây dựng để ưu tiên hai “demand” chính trong thế giới thực: đào tạo mô hình AI nhanh nhất càng tốt và giảm chi phí đào tạo. Hệ thống cho phép đào tạo mô hình AI hiệu quả cao cho các ứng dụng thị giác như lỗi sản xuất, giúp tạo ra các sản phẩm tốt hơn với ít vấn đề bảo hành hơn và phát hiện gian lận, tiết kiệm hàng tỷ đô la mỗi năm. Quản lý hàng tồn kho là một lĩnh vực khác được hưởng lợi từ công nghệ AI bằng cách cho phép các doanh nghiệp trở nên hiệu quả hơn. Sử dụng công nghệ AI, hình ảnh y tế trở nên chính xác hơn và nhanh hơn trong việc phát hiện các bất thường và nhận dạng từ ảnh hoặc video có thể tăng cường bảo mật khi cần thiết. AI cũng cho phép các ứng dụng ngôn ngữ, bao gồm trả lời câu hỏi, truy vấn chủ đề, chatbot, bản dịch và phân tích tình cảm cho các hệ thống đề xuất, nâng cao các tổ chức dịch vụ khách hàng với kiến thức chính xác và nhất quán hơn.
Thông số kỹ thuật
Hệ thống 420GH-TNGR bao gồm 8 card Gaudi HL-205, bộ xử lý Intel® Xeon® Có thể mở rộng thế hệ thứ ba dual-socket hiệu năng cao, hai switch PCIe Gen 4, bốn ổ cứng hybird NVMe / SATA có thể hoán đổi nóng, nguồn điện dự phòng hoàn toàn công suất cao và 24 x 100GbE RDMA (6 QSFP-DD) cho băng thông hệ thống mở rộng chưa từng có. Hệ thống này chứa tối đa 8TB bộ nhớ DDR4-3200MHz, mở ra toàn bộ tiềm năng của bộ vi xử lý Gaudi. HL-205 tuân thủ đặc điểm kỹ thuật OCP-OAM (Mô-đun tăng tốc dự án máy tính mở). Mỗi thẻ tích hợp bộ vi xử lý Gaudi HL-2000 với bộ nhớ HBM2 32 GB và mười cổng mạng tốc độ cao, tích hợp nguyên bản 100GbE RoCE v2 RDMA.
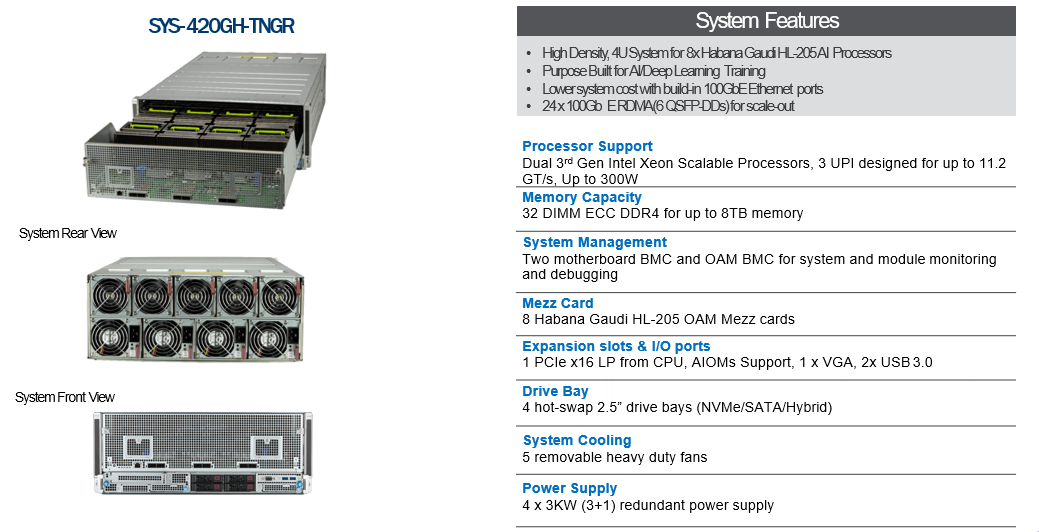
Thông số kỹ thuật SYS-420GH-TNGR
Mỗi bộ vi xử lý Gaudi sử dụng bảy trong số mười cổng RoCE 100GbE của nó để kết nối tất cả cho tất cả trong hệ thống, với ba cổng có sẵn để mở rộng với tổng số 24 cổng RoCE x100GbE cho mỗi hệ thống 8 card Gaudi. Điều này cho phép khách hàng có thể mở rộng quy mô triển khai của họ bằng cách sử dụng các thiết bị chuyển mạch 100GbE tiêu chuẩn. Thông lượng cao của băng thông RoCE bên trong và bên ngoài cùng giao thức tiêu chuẩn thống nhất được sử dụng để mở rộng quy mô làm cho giải pháp dễ dàng mở rộng và tiết kiệm chi phí hơn. Sơ đồ dưới đây cho thấy các bộ xử lý Gaudi HL-205 và các đường dẫn giao tiếp giữa các bộ xử lý và CPU máy chủ.

Thông số kỹ thuật SYS-420GH-TNGR
Hình ảnh dưới đây cho thấy cách một giải pháp đào tạo phân tán, quy mô lớn được xây dựng bằng cách sử dụng Hệ thống AI Gaudi làm thành phần cơ bản với kết nối Ethernet tiêu chuẩn. Nó cung cấp ba mức giảm – một trong hệ thống, một giữa 11 Hệ thống AI của Gaudi và một mức khác giữa 12 hệ thống Gaudi. Nhìn chung, hệ thống này lưu trữ 8 * 11 * 12 = 1056 thẻ Gaudi. Các hệ thống lớn hơn có thể được xây dựng với một lớp tổng hợp bổ sung hoặc với băng thông ít hơn trên mỗi Gaudi.


Các cấu trúc liên kết để mở rộng các mô hình đào tạo khác nhau
SUPERMICRO 420GH-TNGR HIỂN THỊ LỢI ÍCH CỦA BỘ XỬ LÝ ĐÀO TẠO AI HABANA GAUDI
- Hiệu suất cao, hiệu quả cao
- Hiệu suất về giá cho phép tiếp cận nhiều khách hàng cuối hơn để đào tạo về AI
- Hiệu suất ở quy mô: thông lượng cao ở quy mô thấp
- Công suất hệ thống thấp
- Khả năng mở rộng đầu tiên của loại hình này với khả năng mở rộng quy mô Ethernet gốc
- Tránh các giao diện độc quyền với Ethernet tiêu chuẩn công nghiệp
- Loại bỏ tắc nghẽn với NIC tích hợp RDMA được tích hợp qua Ethernet hội tụ (RoCE v2)
Giảm độ phức tạp, chi phí và sức mạnh của hệ thống với tích hợp các thành phần - Tận dụng tính khả dụng rộng rãi của các bộ chuyển mạch Ethernet tiêu chuẩn
Giải pháp linh hoạt và hỗ trợ tùy chỉnh và dễ thực hiện- Nền tảng phần mềm Habana SynapseAI có tính năng:
- TPC có thể lập trình và thư viện TPC phong phú
- Cơ sở hạ tầng và công cụ phần mềm
- Trình biên dịch đồ thị và thời gian chạy
- Hỗ trợ các khuôn khổ và mô hình phổ biến
- Nền tảng phần mềm Habana SynapseAI có tính năng:
- Tuân thủ Mô-đun Tăng tốc Dự án Máy tính Mở (OCP) (OAM)
Hiệu suất ResNet-50
Supermicro 420GH-TNGR với bộ vi xử lý có thể mở rộng Intel Xeon thế hệ thứ 3 và tám bộ xử lý đào tạo AI của Habana Gaudi đã cho thấy hiệu suất và khả năng mở rộng tuyệt vời khi chạy ResNet-50 trong khuôn khổ TensorFlow. Dưới đây là biểu đồ cho thấy, khi số lượng thẻ đào tạo AI của Habana Gaudi được tăng lên, thông lượng, được đo bằng số hình ảnh mỗi giây, tăng lên theo tỷ lệ gần tuyến tính. Khi so sánh với các hệ thống khác trên cơ sở giá cả và hiệu suất, giải pháp này đã cho thấy hiệu suất vượt bậc và ngoài mong đợi.

Hiệu suất khi thẻ Gaudi được tăng lên
Nghiên cứu điển hình: Đào tạo AI phân tán, quy mô lớn tại Trung tâm Siêu máy tính San Diego
Trung tâm Siêu máy tính San Diego (SDSC) là công ty dẫn đầu và tiên phong trong lĩnh vực máy tính hiệu suất cao và sử dụng nhiều dữ liệu, cung cấp các nguồn lực, dịch vụ và chuyên môn về cấu trúc mạng cho cộng đồng nghiên cứu quốc gia, học viện và ngành công nghiệp. Nằm trong khuôn viên UC San Diego, SDSC hỗ trợ hàng trăm chương trình đa ngành trải dài trên nhiều lĩnh vực, từ vật lý thiên văn và khoa học trái đất đến nghiên cứu bệnh tật và khám phá thuốc.

Quỹ Khoa học Quốc gia (NSF) đã trao cho Trung tâm Siêu máy tính San Diego (SDSC) tại UC San Diego một khoản tài trợ để phát triển nguồn lực hiệu suất cao để thực hiện nghiên cứu trí tuệ nhân tạo (AI) trên nhiều lĩnh vực khoa học và kỹ thuật. Được gọi là Voyager, hệ thống này sẽ là hệ thống đầu tiên có sẵn trong danh mục tài nguyên của NSF. Là một phần trong sứ mệnh phát triển các thuật toán cho các miền này, SDSC yêu cầu một hệ thống hiệu quả về chi phí nhưng mạnh mẽ để tăng tốc các thuật toán Đào tạo AI. SDSC đã chọn sự kết hợp của các máy chủ CPU dựa trên Supermicro Intel Xeon và hệ thống đào tạo AI của Habana Gaudi. Khi hoàn thành, hệ thống Voyager sẽ chứa hơn 42 Hệ thống đào tạo AI Supermicro X12 Gaudi, 336 bộ xử lý Habana Gaudi và 16 bộ xử lý Habana Goya để suy luận.
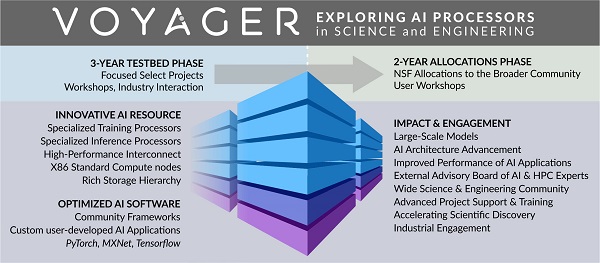
Supermicro đã hợp tác chặt chẽ với Habana và SDSC để tạo ra một hệ thống đào tạo AI quy mô lớn. Một hệ thống hiệu quả và theo định hướng hiệu suất có thể được thực hiện dựa trên nhu cầu của người dùng bằng cách chọn các thành phần phù hợp, như minh họa bên dưới. Chuyên môn trong nhiều lĩnh vực, kết hợp với nhiều loại máy chủ và phần cứng lưu trữ, cho phép Supermicro cung cấp các giải pháp tùy chỉnh dựa trên các tiêu chuẩn của ngành. Supermicro xây dựng các hệ thống từ đầu với một cơ sở sản xuất hoàn chỉnh, từ thử nghiệm bo mạch cho đến cấu hình và thử nghiệm nhiều giá đỡ. Điều này dẫn đến sự tự tin hơn và ít vấn đề hơn khi bàn giao cho khách hàng sáng tạo, tùy chỉnh và tối ưu hệ thống hơn nữa.
Việc cài đặt Voyager lớn và hiệu quả để đào tạo và suy luận AI bao gồm nhiều giá đỡ của hệ thống đào tạo AI của Habana Gaudi, giá đỡ Goya Inference, các nút lưu trữ và giá đỡ thiết bị mạng thích hợp để hỗ trợ tốc độ cao cần thiết cho quy mô đào tạo rất nhanh chóng và hiệu quả.

Ví dụ về Hệ thống đào tạo Gaudi quy mô lớn Supermicro
Tóm lược
Deep Learning cách mạng hóa máy tính, tác động đến các doanh nghiệp trên nhiều lĩnh vực công nghiệp và nghiên cứu. Độ phức tạp tính toán của mạng nơ-ron sâu đang trở nên lớn hơn theo cấp số nhân, thúc đẩy nhu cầu lớn về sức mạnh tính toán. Thách thức của đào tạo mạng nơ-ron sâu là cải thiện nhiều tiêu chí cùng một lúc: thứ nhất, hoàn thành công việc nhanh hơn với thời gian đào tạo giảm; thứ hai, để đạt được giá cả / hiệu suất được cải thiện, do đó giảm tổng chi phí sở hữu để cho phép tiếp cận với nhiều khóa đào tạo AI hơn cho nhiều người dùng cuối hơn; thứ ba, để giảm tiêu thụ năng lượng toàn hệ thống; thứ tư, cung cấp khả năng mở rộng linh hoạt với các giao diện tiêu chuẩn loại bỏ khóa nhà cung cấp; và cuối cùng, cho phép khách hàng cuối tùy chỉnh khối lượng công việc để giải quyết nhu cầu riêng của họ.

Supermicro đã hợp tác với Habana Labs và Intel để cung cấp hệ thống hiệu suất cao và tiết kiệm chi phí cho đào tạo AI, cùng với Bộ xử lý có thể mở rộng Intel Xeon thế hệ thứ 3. Sự kết hợp giữa chuyên môn của Supermicro trong thiết kế hệ thống và Habana Labs với thiết kế bộ xử lý AI sẽ cho phép đào tạo hiệu suất cao với giá cả hợp lý và giúp đào tạo AI dễ tiếp cận hơn với nhiều ngành công nghiệp. Hệ thống đào tạo AI Supermicro X12 Gaudi cung cấp khả năng mở rộng vượt trội và đã được chứng minh bởi những khách hàng yêu cầu AI. Bằng cách thiết kế, cấu hình và thử nghiệm, khách hàng có thể tin tưởng rằng các cụm đang hoạt động và được tối ưu hóa cho mục đích sử dụng của họ.
Supermicro 420GH-TNGR mang đến nhiều tính năng nổi bật, lợi thế so với các giải pháp đào tạo AI truyền thống:
• Dẫn đầu về hiệu suất dẫn đến thời gian đào tạo thấp hơn đáng kể, cải thiện hiệu quả về giá / hiệu suất và quy mô hệ thống thấp hơn
• Thông lượng cao ở quy mô nhỏ
• Tích hợp công nghệ mới của Ethernet để mở rộng quy mô
• Chi phí hệ thống thấp hơn nhờ tính khả dụng cao của các bộ chuyển mạch Ethernet ở bất kỳ kích thước nào và từ nhiều nhà cung cấp khác nhau
• Đào tạo phân tán quy mô lớn với quy mô gần tuyến tính
• Hỗ trợ các khuôn khổ và mô hình phổ biến, với Nền tảng phần mềm Habana Synapse AI
• Tuân thủ Mô-đun Tăng tốc Dự án Máy tính Mở (OCP) (OAM)
Hệ thống đào tạo AI Supermicro X12 Gaudi 420GH-TNGR mang đến cho các tổ chức cơ hội để giảm tổng chi phí sở hữu (TCO), một lộ trình linh hoạt và dễ dàng để mở rộng hệ thống AI của họ khi chúng phát triển và phát triển mạnh mẽ hơn nữa.

