











NVIDIA DGX SuperPOD: Hạ tầng mở rộng dẫn đầu cho AI
Bài giới thiệu chi tiết kiến trúc hạ tầng của cụm siêu máy tính AI NVIDIA DGX SuperPOD.
Tổng quan
Hệ thống NVIDIA DGX SuperPOD với máy chủ NVIDIA DGX A100 là hạ tầng siêu máy tính Trí tuệ Nhân tạo (AI) thế hệ tiếp theo, cung cấp sức mạnh tính toán cần thiết để đào tạo các mô hình học sâu (DL) tiên tiến nhất hiện nay và thúc đẩy sự phát triển trong tương lai. DGX SuperPOD mang lại hiệu suất đột phá, triển khai trong vài tuần như một hệ thống tích hợp hoàn chỉnh và được thiết kế để giải quyết các vấn đề tính toán khó khăn nhất trên thế giới.

Kiến trúc tham chiếu DGX SuperPOD này là kết quả của việc hợp tác chuyên sâu giữa các nhà khoa học DL, kỹ sư hiệu suất ứng dụng và kiến trúc sư hệ thống để xây dựng một hệ thống có khả năng hỗ trợ phạm vi khối lượng công việc DL rộng nhất. Một siêu máy tính được chế tạo bằng cách sử dụng kiến trúc tham chiếu này đã giành được vị trí thứ năm trên Danh sách TOP500 tháng 11 năm 2020, cũng như lần đầu tiên trên Danh sách Green500 tháng 11 năm 2020. Vào tháng 7 năm 2020, siêu máy tính đã lập kỷ lục thế giới ở tất cả tám điểm benchmark ở quy mô lớn trong Đào tạo MLPerf v0.7 và GPU NVIDIA® A100 Tensor Core đã thiết lập tất cả 16 kỷ lục trong danh mục hệ thống thương mại.
Thiết kế này giới thiệu các building block về xử lý được gọi là các đơn vị có thể mở rộng (SU) cho phép triển khai module hóa cho DGX SuperPOD với đầy đủ 140 node, có thể mở rộng hơn nữa đến hàng trăm node. Thiết kế DGX SuperPOD bao gồm các thiết bị chuyển mạch mạng hiệu suất cao của NVIDIA và hệ thống phần mềm, lưu trữ được chứng nhận cho DGX POD, kềm theo đó là phần mềm tối ưu hóa NVIDIA NGC.
Kiến trúc tham chiếu DGX SuperPOD đã được ứng dụng trong hạ tầng NVIDIA DGX SATURNV, hỗ trợ nghiên cứu và phát triển cho chính NVIDIA trong các dự án phương tiện tự hành, xử lý ngôn ngữ tự nhiên (NLP), robot, đồ họa, HPC và các lĩnh vực khác. Các tổ chức muốn triển khai hạ tầng siêu máy tính của riêng họ có thể tận dụng giải pháp NVIDIA DGX SuperPOD cho doanh nghiệp, nó cung cấp kiến trúc tham chiếu DGX SuperPOD được triển khai trong giải pháp hạ tầng “chìa khóa trao tay” cùng với vòng đời đầy đủ của các dịch vụ nâng cao, từ lập kế hoạch đến thiết kế, triển khai nhằm tối ưu hóa mọi thứ.
DGX SuperPOD với Hệ thống DGX A100
Nhu cầu tính toán của các nhà nghiên cứu AI tiếp tục tăng lên khi mức độ phức tạp của mạng DL và dữ liệu đào tạo tăng theo cấp số nhân. Việc đào tạo trước đây chỉ giới hạn ở một hoặc một vài GPU, thường là trong các máy trạm. Đào tạo ngày nay thường sử dụng hàng chục, hàng trăm hoặc thậm chí hàng nghìn GPU để đánh giá và tối ưu hóa các cấu hình và thông số mô hình khác nhau. Ngoài ra, các tổ chức có nhiều nhà nghiên cứu AI cần đào tạo nhiều mô hình đồng thời. Các hệ thống ở quy mô khổng lồ này có thể là điều mới mẻ đối với các nhà nghiên cứu AI, nhưng những hệ thống lắp đặt này đã là dấu ấn của các cơ sở nghiên cứu và học viện quan trọng nhất thế giới, thúc đẩy sự đổi mới thúc đẩy các nỗ lực khoa học ở hầu hết mọi loại hình.

Thế giới siêu máy tính đang phát triển để thúc đẩy cuộc cách mạng công nghiệp tiếp theo, được thúc đẩy bởi một nhận thức mới về cách các tài nguyên máy tính khổng lồ có thể được kết hợp với nhau để giải quyết các vấn đề kinh doanh quan trọng. NVIDIA đang mở ra một kỷ nguyên mới, trong đó các doanh nghiệp có thể triển khai các siêu máy tính thiết lập kỷ lục thế giới bằng cách sử dụng các thành phần tiêu chuẩn hóa trong vài tuần.
Thiết kế và xây dựng cơ sở hạ tầng điện toán mở rộng cho AI đòi hỏi sự hiểu biết về các mục tiêu tính toán của các nhà nghiên cứu AI để xây dựng các hệ thống nhanh, có khả năng và tiết kiệm chi phí. Việc phát triển các yêu cầu về cơ sở hạ tầng thường có thể khó khăn vì nhu cầu nghiên cứu thường là một mục tiêu luôn chuyển động và các mô hình AI, do bản chất độc quyền của chúng, thường không thể được chia sẻ với các nhà cung cấp. Ngoài ra, việc tạo ra các điểm chuẩn mạnh mẽ thể hiện nhu cầu tổng thể của một tổ chức là một quá trình tốn nhiều thời gian. Đi một mình và thiết kế một siêu máy tính không phải là một
phương án khả thi.
Không chỉ cần nhiều node GPU để đạt được hiệu suất tối ưu trên nhiều loại mô hình khác nhau. Để xây dựng một hệ thống linh hoạt có khả năng chạy vô số ứng dụng DL trên quy mô lớn, các tổ chức cần có một hệ thống cân bằng tốt, tối thiểu phải kết hợp được:
• Các node mở rộng quy mô mạnh mẽ với nhiều GPU, bộ nhớ lớn và kết nối nhanh giữa các GPU để tính toán nhằm hỗ trợ nhiều loại mô hình DL đang được sử dụng.
• Kết nối mạng có độ trễ thấp, băng thông cao, được thiết kế với dung lượng và cấu trúc liên kết để giảm thiểu tắc nghẽn.
• Hệ thống phân cấp lưu trữ có thể cung cấp hiệu suất tối đa cho các nhu cầu khác nhau về cấu trúc tập dữ liệu. Những yêu cầu này, được cân nhắc về chi phí để tối đa hóa giá trị tổng thể, có thể được đáp ứng với thiết kế được trình bày trong bài này – NVIDIA DGX SuperPOD.
Hệ thống NVIDIA DGX A100
NVIDIA DGX A100 là hệ thống chung cho tất cả khối lượng công việc AI, cung cấp mật độ tính toán, hiệu suất và tính linh hoạt chưa từng có trong hệ thống AI với 5 petaFLOPS đầu tiên trên thế giới.

Đặc điểm kỹ thuật và Tính năng
Yêu cầu thiết kế
DGX SuperPOD được thiết kế để giảm thiểu tắc nghẽn hệ thống và tối đa hóa hiệu suất cho bản chất đa dạng của khối lượng công việc AI và HPC. Để làm như vậy, thiết kế này cung cấp:
• Một kiến trúc mô-đun được xây dựng từ SU. Nhiều SU được kết nối để tạo ra một hệ thống hỗ trợ nhiều người dùng chạy đồng thời các khối lượng công việc AI đa dạng.
• Cơ sở hạ tầng phần cứng và phần mềm được xây dựng xung quanh DGX SuperPOD cho phép các ứng dụng DL phân tán mở rộng quy mô trên hàng trăm node.
• Khả năng triển khai và cập nhật hệ thống nhanh chóng. Tận dụng kiến trúc tham chiếu cho phép nhân viên trung tâm dữ liệu phát triển một giải pháp đầy đủ với ít lần lặp lại thiết kế hơn.
• Các dịch vụ quản lý chính trong các cấu hình có tính khả dụng cao, cần thiết để giám sát và quản lý hệ thống. Điều này bao gồm cung cấp hệ thống, quản lý kết cấu, đăng nhập, giám sát hệ thống và báo cáo, cũng như quản lý và điều phối khối lượng công việc.
Cấu trúc xử lý
Cấu trúc tính toán phải có khả năng mở rộng từ hàng trăm đến hàng nghìn node trong khi tối đa hóa hiệu suất của các mẫu giao tiếp DL. Để làm được điều này:
• Các SU được kết nối trong một cấu trúc liên kết dạng cây đầy đủ, được tối ưu hóa trên thanh trượt, tối đa hóa khả năng mạng cho các hệ thống DGX A100.
• Nhiều cụm DGX SuperPOD có thể được kết nối để tạo ra các hệ thống lớn hơn với hàng nghìn node.
• Hỗ trợ kiến trúc Định tuyến thích hợp.
• Mạng được tối ưu hóa với NVIDIA Mellanox Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™ version 2.
Cấu trúc lưu trữ
Kết cấu lưu trữ phải cung cấp khả năng truy cập thông lượng cao vào bộ nhớ dùng chung. Kiến trúc lưu trữ được mô tả:
• Cung cấp băng thông node đơn hơn 40 GBps.
• Tối đa hóa hiệu suất truy cập bộ nhớ từ một SU duy nhất.
• Tận dụng giao tiếp truy cập bộ nhớ trực tiếp từ xa (RDMA) để di chuyển dữ liệu có tần suất thấp và nhanh nhất.
• Cung cấp kết nối bổ sung để chia sẻ bộ nhớ giữa DGX SuperPOD và các tài nguyên khác trong trung tâm dữ liệu.
• Cho phép đào tạo các mô hình DL yêu cầu hiệu suất I/O cao nhất, vượt quá 16 GBps (2 GBps /mỗi GPU) trực tiếp từ bộ lưu trữ từ xa.
Kiến trúc SuperPOD
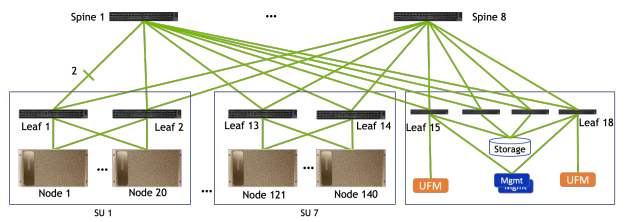
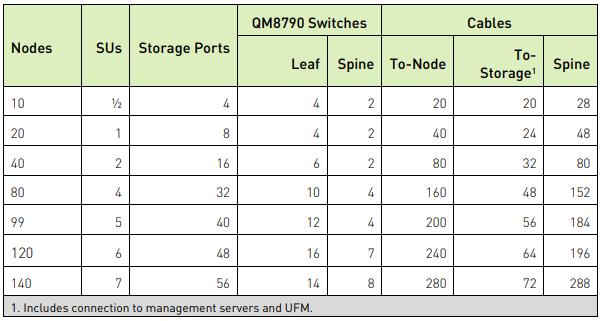
Khối xây dựng cơ bản cho DGX SuperPOD là SU, bao gồm 20 hệ thống DGX A100. Kích thước này tối ưu hóa cả hiệu suất và chi phí trong khi vẫn giảm thiểu tắc nghẽn hệ thống để khối lượng công việc phức tạp được hỗ trợ tốt. Một SU duy nhất có khả năng tạo ra 48 AI PFLOPS.

Hệ thống DGX A100 có tám bộ kênh HDR (200 Gbps) InfiniBand (IB) dùng (HCAs) để tính toán lưu lượng. Mỗi GPU có HCA liên quan riêng của nó. Để có kế nối mạng hiệu quả nhất, có tám bản mạch mạng, một bản mạch cho mỗi HCA của hệ thống DGX A100 kết nối bằng cách sử dụng tám thiết bị chuyển mạch nhánh, trên một bản mạch. Các bản mạch mạng được kết nối với nhau ở cấp độ thứ hai của mạng thông qua các thiết bị chuyển mạch trục. Mỗi SU có đầy đủ băng thông phân chia để đảm bảo tính linh hoạt của ứng dụng tối đa.
Mỗi SU có một tủ quản lý chuyên dụng. Các thiết bị chuyển mạch nhánh được đặt tập trung trong tủ quản lý. Các thiết bị khác cho DGX SuperPOD, chẳng hạn như thiết bị chuyển mạch trục cấp hai hoặc máy chủ quản lý có thể nằm trong không gian bổ sung của tủ quản lý SU hoặc tủ riêng tùy thuộc vào cách bố trí trung tâm dữ liệu.
Kiến trúc mạng
DGX SuperPOD có bốn lớp mạng:
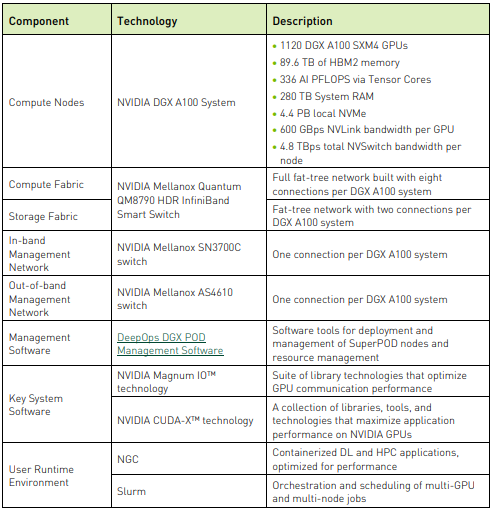
• Compute fabric: Kết nối tám NVIDIA Mellanox ConnectX®-6 HCA từ mỗi DGX A100 thông qua các bản mạch mạng riêng biệt.
• Storage fabric: Sử dụng hai cổng, mỗi cổng từ hai cổng đôi ConnectX-6 HCA được kết nối qua CPU.
• In-band management: Sử dụng cổng 100 Gbps trên hệ thống DGX A100 để kết nối với bộ chuyển mạch Ethernet chuyên dụng.
• Out-of-band management: Kết nối cổng bộ điều khiển quản lý bo mạch chủ (BMC) của mỗi hệ thống DGX A100 với bộ chuyển mạch Ethernet bổ sung.
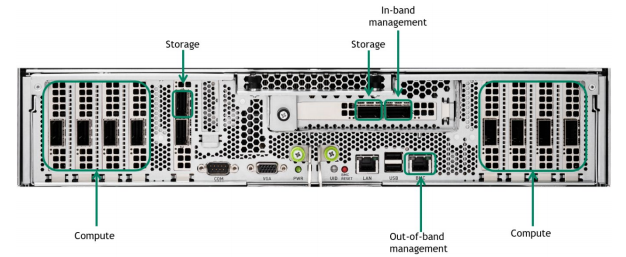
Compute Fabric
Mỗi hệ thống DGX A100 có tám kết nối với kết cấu comute fabric. Thiết kế kết nối tối đa hóa hiệu suất cho lưu lượng trao đổi của khối lượng công việc AI, cũng như cung cấp một số dự phòng trong trường hợp phần cứng bị lỗi và giảm thiểu chi phí.
Đối với mỗi SU, có tám thiết bị chuyển mạch nhánh. Thiết kế được tối ưu hóa trên cùng trục, có nghĩa là tất cả các HCA giống nhau từ mỗi hệ thống được kết nối với cùng một chuyển mạch nhánh. Tổ chức tối ưu hóa trục này rất quan trọng để tối đa hóa hiệu suất đào tạo DL và tiện ích của SharpV2 trong môi trường đa công việc.
Cấu trúc liên kết cấu trúc phần Compute cho một DGX SuperPOD 140 node
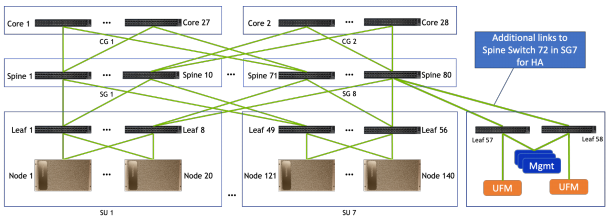
Đối với DGX SuperPOD 140 nút tiêu chuẩn, thiết kế được tối ưu hóa trục – mỗi bản mạch IB trên hệ thống DGX A100 được kết nối với cấu trúc liên kết cây của riêng nó. Để tối ưu hóa thiết kế kết nối, một nhóm Trục (SG) gồm mười thiết bị QM8790 được giới thiệu. Tám SGs là bắt buộc vì có tám mô-đun IB trên mỗi hệ thống DGX A100. Thiết bị chuyển mạch nhánh đầu tiên từ mỗi SU kết nối với mỗi thiết bị chuyển mạch trong SG1, thiết bị chuyển mạch nhánh thứ hai từ mỗi SU kết nối với mỗi thiết bị chuyển mạch trong SG2, v.v. Một lớp chuyển mạch thứ ba là cần thiết để hoàn thành cấu trúc liên kết cây. Điều này đạt được với 28 thiết bị chuyển mạch QM8790 hoạt động như lớp lõi. Hai nhóm lõi (CG) mỗi nhóm có 14 thiết bị chuyển mạch được cấu hình. Mọi thiết bị chuyển mạch đơn từ mỗi thiết bị chuyển mạch trong số tám trục SG ra từng thiết bị chuyển mạch trong CG1 (lẻ) và mọi chuyển đổi chẵn từ từng thiết bị chuyển mạch trong số tám trục SG ra từng thiết bị chuyển mạch trong CG2 (chẵn).
Như vậy, việc xây dựng các cấu hình DGX SuperPOD với 100 nút trở xuống đơn giản hơn vì không yêu cầu lớp chuyển mạch thứ ba.
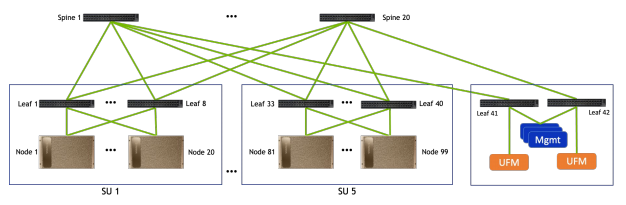
Cấu trúc kết nối Compute sử dụng thiết bị chuyển mạch NVIDIA Mellanox Quantum QM8790

Storage Fabric
Cấu trúc kế nối lưu trữ sử dụng cấu trúc mạng InfiniBand. Kết nối dựa trên InfiniBand là điều cần thiết để tối đa hóa băng thông vì các yêu cầu I/O trên mỗi node đối với DGX SuperPOD phải vượt quá 40 GBps. Yêu cầu băng thông cao với các tính năng quản lý kết nối nâng cao, chẳng hạn như kiểm soát tắc nghẽn và định tuyến thích ứng, mang lại lợi ích đáng kể cho cấu trúc kết nối lưu trữ.
Cấut trúc kết nối lưu trữ cũng sử dụng thiết bị chuyển mạch QM8790. Cấu trúc kết nối là một cây có tỷ lệ mô tả quá mức khoảng 5:4. Cấu trúc liên kết mạng này cung cấp sự cân bằng tốt giữa hiệu suất và chi phí. Thiết kế chi tiết ở phần dưới dựa trên các máy chủ lưu trữ yêu cầu tám cổng cho mỗi SU. Điều này có thể khác nhau tùy thuộc vào kiến trúc lưu trữ và các yêu cầu về hiệu suất lưu trữ của một triển khai nhất định.
In-Band Management Network
In-Band Management Network có một số chức năng quan trọng:
• Kết nối tất cả các dịch vụ cụm quản lý.
• Cho phép truy cập vào hệ thống tệp nội bộ và nhóm lưu trữ.
• Cung cấp kết nối cho các dịch vụ trong cụm như Slurm và Kubernetes và các dịch vụ khác bên ngoài cụm như NGC registry, kho lưu trữ mã nguồn và nguồn dữ liệu.
In-Band Management Network được xây dựng bằng bộ chuyển mạch NVIDIA Mellanox SN3700C 100xGbE. Có hai liên kết lên từ mỗi thiết bị chuyển mạch đến thiết bị chuyển mạch lõi trung tâm dữ liệu. Kết nối với các tài nguyên bên ngoài và với internet được định tuyến thông qua bộ chuyển mạch lỗi của trung tâm dữ liệu.

Out-of-Band Management Network
Out-of-Band Management Network được sử dụng để quản lý hệ thống qua BMC và cung cấp kết nối để quản lý tất cả các thiết bị mạng. Out-of-Band Management Network rất quan trọng đối với hoạt động của cụm bằng cách cung cấp các đường dẫn sử dụng thấp để đảm bảo lưu lượng quản lý không xung đột với các dịch vụ cụm khác.
Out-of-Band Management Network dựa trên bộ chuyển mạch NVIDIA Mellanox AS4610 1GbE, chạy hệ điều hành mạng Cumulus Linux thân thiện với DevOps. Các thiết bị chuyển mạch này được kết nối trực tiếp với thiết bị chuyển mạch lõi của trung tâm dữ liệu. Ngoài ra, tất cả các thiết bị chuyển mạch Ethernet được kết nối thông qua kết nối nối tiếp với các máy chủ bảng điều khiển Opengear hiện có trong trung tâm dữ liệu. Các kết nối này cung cấp một phương tiện kết nối cuối cùng tới các thiết bị chuyển mạch trong trường hợp mạng bị lỗi.

Kiến trúc lưu trữ
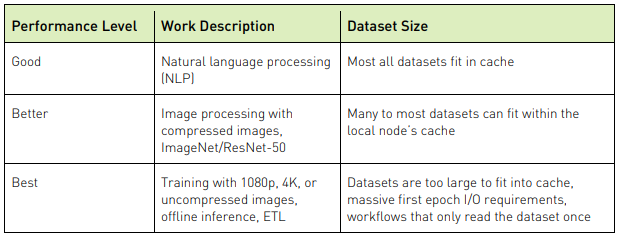
Hiệu suất đào tạo có thể bị giới hạn bởi tốc độ dữ liệu có thể được đọc và đọc lại từ bộ lưu trữ. Chìa khóa của hiệu suất là khả năng đọc dữ liệu nhiều lần. Dữ liệu được lưu vào bộ nhớ đệm càng gần GPU, thì chúng càng có thể được đọc nhanh hơn. Kiến trúc và thiết kế lưu trữ phải xem xét thứ bậc của các công nghệ lưu trữ khác nhau, bền bỉ hoặc không bền bỉ, để cân bằng các nhu cầu về hiệu suất, dung lượng và chi phí. Bảng thông tin bên dưới ghi lại cấu trúc phân cấp bộ nhớ đệm lưu trữ. Tùy thuộc vào kích thước dữ liệu và nhu cầu hiệu suất, mỗi cấp của hệ thống phân cấp có thể được tận dụng để tối đa hóa hiệu suất ứng dụng.
Phân cấp bộ nhớ đệm và lưu trữ của DGX SuperPOD

Dữ liệu lưu vào bộ nhớ đệm trong RAM cục bộ mang lại hiệu suất đọc tốt nhất. Bộ nhớ đệm này trong suốt khi dữ liệu được đọc từ hệ thống tệp. Tuy nhiên, kích thước của RAM bị hạn chế và ít tiết kiệm chi phí hơn so với các công nghệ lưu trữ và bộ nhớ khác. Lưu trữ NVMe cục bộ là một cách hiệu quả hơn về chi phí để cung cấp bộ nhớ đệm gần với GPU. Tuy nhiên, sao chép thủ công các bộ dữ liệu vào đĩa cục bộ có thể rất không linh hoạt. Mặc dù có nhiều cách để tận dụng đĩa cục bộ một cách tự động (ví dụ: cachefilesd cho hệ thống tệp NFS), nhưng không phải mọi hệ thống tệp mạng đều cung cấp phương pháp để làm như vậy. Hiệu suất của bộ lưu trữ tốc độ cao trong bảng bên dưới không được cung cấp vì câu trả lời phụ thuộc rất nhiều vào loại mô hình đang được đào tạo và kích thước của tập dữ liệu.
Yêu cầu về hiệu suất lưu trữ
Hướng dẫn về hiệu suất lưu trữ
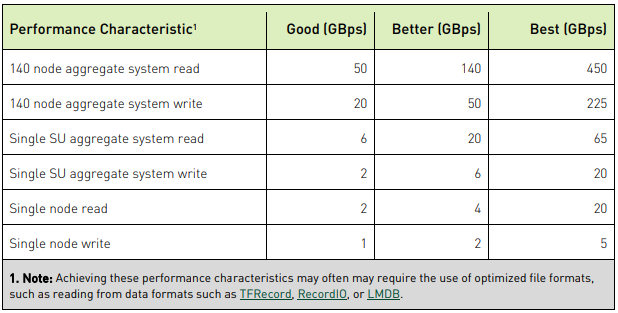
Bộ nhớ tốc độ cao cung cấp chế độ xem chia sẻ dữ liệu của tổ chức tới tất cả các node. Nó cần được tối ưu hóa cho các mẫu I/O nhỏ, ngẫu nhiên và cung cấp hiệu suất nút đỉnh cao và hiệu suất hệ thống tệp tổng hợp cao để đáp ứng nhiều khối lượng công việc mà một tổ chức có thể gặp phải. Bộ nhớ tốc độ cao sẽ hỗ trợ cả việc đọc và ghi đa luồng hiệu quả từ một hệ thống duy nhất, nhưng hầu hết các khối lượng công việc DL sẽ chiếm ưu thế đọc.
Bộ dữ liệu 30 TB vẫn được coi là lớn. Các trường hợp sử dụng trong các tác vụ liên quan đến hiển thị trên ô tô và máy tính khác, trong đó hình ảnh 1080p được sử dụng để đào tạo (và trong một số trường hợp là không nén) liên quan đến bộ dữ liệu có kích thước dễ dàng vượt quá 30 TB. Trong những trường hợp này, cần 2 GBps cho mỗi GPU để có hiệu suất đọc.
Các số liệu trên giả định nhiều khối lượng công việc, bộ dữ liệu và nhu cầu đào tạo cục bộ và trực tiếp từ hệ thống lưu trữ tốc độ cao. Tốt nhất là mô tả khối lượng công việc và nhu cầu của riêng bạn trước khi hoàn thiện các yêu cầu về hiệu suất và năng lực. NVIDIA có một số đối tác mà chúng tôi cộng tác để xác thực các giải pháp lưu trữ cho hệ thống DGX và DGX SuperPOD.
Kiến trúc quản lý
DGX SuperPOD yêu cầu một số máy chủ dựa trên CPU để quản lý hệ thống. Để cung cấp mức độ sẵn sàng cao nhất, mỗi dịch vụ này đều nằm trên các máy chủ của riêng chúng và các dịch vụ được chạy theo cặp ở cấu hình tính sẵn sàng cao. Các dịch vụ được cung cấp bởi các máy chủ được liệt kê bên dưới:
Máy chủ quản lý DGX SuperPOD
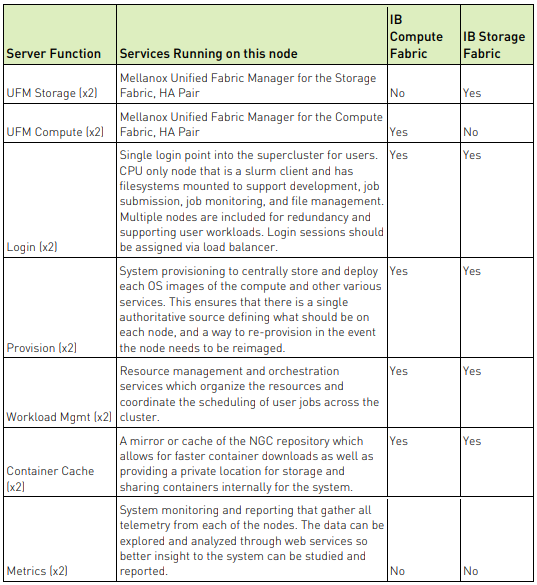
Các lớp phần mềm của DGX SuperPOD
Giá trị của kiến trúc DGX SuperPOD vượt xa phần cứng của nó. DGX SuperPOD là một hệ thống hoàn chỉnh cung cấp tất cả các thành phần chính để quản lý hệ thống, quản lý công việc và tối ưu hóa khối lượng công việc để đảm bảo triển khai nhanh chóng, dễ sử dụng và tính sẵn sàng cao. Các lớp phần mềm bắt đầu với Hệ điều hành DGX (DGX OS), được điều chỉnh và đủ điều kiện để sử dụng trên các hệ thống DGX A100. DGX SuperPOD chứa một bộ công cụ để quản lý việc triển khai, vận hành và giám sát cụm. NGC là thành phần chính của DGX SuperPOD, cung cấp các ứng dụng DL, ML và HPC mới nhất. NGC cung cấp các vùng chứa được đóng gói, thử nghiệm và tối ưu hóa để triển khai nhanh chóng, dễ sử dụng và hiệu suất tốt nhất trên GPU NVIDIA. Cuối cùng, các công cụ chính nhưCUDA-X, Magnum IO và RAPIDS cung cấp cho các nhà phát triển những công cụ họ cần để tối đa hóa hiệu suất DL, HPC và khoa học dữ liệu trong môi trường nhiều node.
Phần mềm NVIDIA chạy trên DGX SuperPOD cung cấp môi trường đào tạo DL hiệu suất cao cho các nhóm phát triển phần mềm AI đa người dùng quy mô lớn. Ngoài DGX OS, nó còn chứa quản lý cụm, công cụ điều phối và trình quản lý tài nguyên (phần mềm quản lý DGX POD), thư viện và khuôn khổ NVIDIA cũng như các vùng chứa được tối ưu hóa từ vùng chứa bản ghi NGC. Để có thêm chức năng, phần mềm quản lý DGX POD bao gồm các công cụ mã nguồn mở của bên thứ ba do NVIDIA đề xuất đã được kiểm tra để hoạt động trên các thành phần DGX POD với các phân lớp phần mềm NVIDIA AI. Hỗ trợ cho các công cụ này có sẵn trực tiếp từ các cấu trúc hỗ trợ của bên thứ ba.

Nền tảng của phân lớp phần mềm NVIDIA là DGX OS, được xây dựng trên phiên bản tối ưu hóa của hệ điều hành Ubuntu hoặc RedHat Linux và được điều chỉnh đặc biệt cho phần cứng DGX. Phần mềm DGX OS bao gồm trình điều khiển GPU được chứng nhận, phân lớp phần mềm mạng, bộ nhớ đệm NFS được định cấu hình trước, công cụ chẩn đoán quản lý GPU (DCGM) của trung tâm dữ liệu NVIDIA, thời gian chạy vùng chứa hỗ trợ GPU, công cụ dành cho nhà phát triển NVIDIA CUDA-X và Magnum IO.
Phần mềm quản lý DGX POD bao gồm các dịch vụ khác nhau chạy trên khung điều phối vùng chứa Kubernetes để có khả năng chịu lỗi và tính sẵn sàng cao. Các dịch vụ được cung cấp cho cấu hình mạng (DHCP) và cung cấp phần mềm DGX OS hoàn toàn tự động qua mạng (PXE). Phần mềm DGX OS có thể được tự động cài đặt lại theo yêu cầu bằng phần mềm quản lý DGX POD.
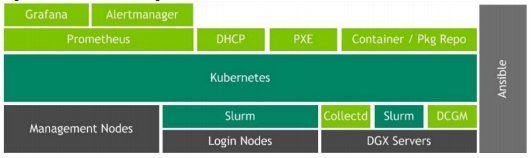
Phần mềm quản lý DGX POD DeepOps cung cấp các công cụ để cung cấp, triển khai, quản lý và giám sát DGX SuperPOD. Các dịch vụ được lưu trữ trong các vùng chứa Kubernetes để có khả năng chịu lỗi và tính sẵn sàng cao. Phần mềm quản lý DGX POD sử dụng công cụ cấu hình Ansible để cài đặt và cấu hình tất cả các công cụ và gói cần thiết để chạy hệ thống. Dữ liệu hệ thống do Prometheus thu thập được báo cáo thông qua Grafana. Công cụ quản lý cảnh báo có thể sử dụng dữ liệu đã thu thập và gửi cảnh báo tự động khi cần.
Đối với các trang web được yêu cầu hoạt động trong môi trường trong suốt hoặc cần các dịch vụ bổ sung tại chỗ, một bản ghi vùng chứa cục bộ phản chiếu các vùng chứa NGC, cũng như nhân bản gói Ubuntu và Python, có thể được chạy trên lớp quản lý Kubernetes để cung cấp dịch vụ cho cụm .
Phần mềm quản lý DGX POD có thể triển khai Slurm hoặc Kubernetes làm trình điều phối và quản lý tài nguyên. Slurm thường là lựa chọn tốt nhất để lên lịch các công việc đào tạo trong môi trường đa node, nhiều người dùng được chia sẻ, nơi yêu cầu các tính năng lập lịch nâng cao như ưu tiên công việc, chèn lấp và quản lý truy cập. Kubernetes thường là lựa chọn tốt nhất trong các môi trường mà các quy trình GPU chạy như một dịch vụ, chẳng hạn như suy luận, sử dụng nhiều khối lượng công việc tương tác thông qua máy tính xách tay Jupyter và nơi có giá trị để có cùng một môi trường thường được sử dụng ở dữ liệu biên của tổ chức trung tâm.
NVIDIA NGC
NGC cung cấp một loạt các tùy chọn đáp ứng nhu cầu của các nhà khoa học dữ liệu, nhà phát triển và nhà
nghiên cứu với nhiều cấp độ chuyên môn khác nhau về AI. Những người dùng này có thể nhanh chóng triển khai các khuôn khổ AI với các vùng chứa, bắt đầu bằng các mô hình được đào tạo trước hoặc tập lệnh đào tạo mô hình và sử dụng quy trình công việc cụ thể của miền và biểu đồ Helm để triển khai AI nhanh nhất, giúp họ có thời gian giải quyết nhanh hơn.
Các thành phần NGC
Mở rộng AI, khoa học dữ liệu và HPC, vùng chứa bản ghi trên NGC có một loạt các phần mềm tăng tốc GPU cho GPU NVIDIA. NGC lưu trữ các bộ chứa cho phần mềm khoa học dữ liệu và AI hàng đầu. Các containers được điều chỉnh, thử nghiệm và tối ưu hóa bởi NVIDIA. Các containers khác cho các ứng dụng HPC bổ sung và phân tích dữ liệu cũng được NVIDIA kiểm tra đầy đủ và cung cấp. Containers NGC cung cấp phần mềm mạnh mẽ và dễ triển khai đã được chứng minh là mang lại kết quả nhanh nhất, cho phép người dùng xây dựng các giải pháp từ một khuôn khổ đã được thử nghiệm, với sự kiểm soát hoàn toàn.
NGC cung cấp các hướng dẫn và tập lệnh từng bước để tạo mô hình học sâu, với các chỉ số hiệu suất và độ chính xác mẫu để so sánh kết quả của bạn. Các tập lệnh này cung cấp hướng dẫn của chuyên gia về việc xây dựng các mô hình DL để phân loại hình ảnh, dịch ngôn ngữ, text-tospeech và hơn thế nữa. Các nhà khoa học dữ liệu có thể nhanh chóng xây dựng các mô hình tối ưu hóa hiệu suất bằng cách dễ dàng điều chỉnh các siêu tham số. Ngoài ra, NGC cung cấp các mô hình được đào tạo trước cho nhiều tác vụ AI phổ biến được tối ưu hóa cho GPU NVIDIA Tensor Core và có thể dễ dàng đào tạo lại bằng cách cập nhật chỉ một vài lớp, tiết kiệm thời gian quý báu.
CUDA-X and Magnum IO
NVIDIA có hai bộ phần mềm chính để tối ưu hóa hiệu suất ứng dụng, CUDA-X và Magnum IO. CUDAX, được xây dựng dựa trên CUDA® công nghệ, là một tập hợp các thư viện, công cụ và công nghệ mang lại hiệu suất cao hơn đáng kể so với các lựa chọn thay thế trên nhiều lĩnh vực ứng dụng – từ trí tuệ nhân tạo đến tính toán hiệu suất cao. Magnum IO là một bộ phần mềm giúp AI, các nhà khoa học dữ liệu và các nhà nghiên cứu máy tính hiệu suất cao xử lý một lượng lớn dữ liệu trong vài phút, thay vì hàng giờ. Containers NGC được kích hoạt với cả CUDA-X và Magnum IO như bên dưới
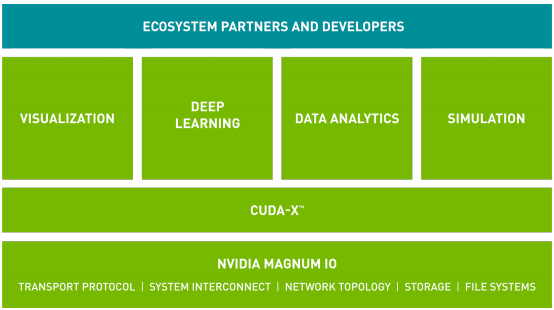
Trung tâm của Magnum IO là công nghệ GPUDirect, cung cấp đường dẫn cho dữ liệu vượt qua CPU và di chuyển trên “open highways” được cung cấp bởi GPU, thiết bị lưu trữ và mạng. Tương thích với nhiều loại kết nối giao tiếp và API – bao gồm công nghệ NVIDIA NVLink và NCCL, cũng như Open MPI và UCX. Thành phần mới nhất của nó là GPUDirect Storage, cho phép các nhà nghiên cứu bỏ qua CPU khi truy cập bộ nhớ và nhanh chóng truy cập các tệp dữ liệu để mô phỏng, phân tích hoặc trực quan hóa.
Tóm tắt
AI đang biến đổi hành tinh của chúng ta và mọi khía cạnh của cuộc sống như chúng ta đã biết, được thúc đẩy bởi thế hệ tiếp theo của các nghiên cứu tiên tiến hàng đầu. Các tổ chức muốn dẫn đầu trong một thế giới được hỗ trợ bởi AI biết rằng cuộc đua đang diễn ra để giải quyết các mô hình AI phức tạp nhất đòi hỏi năng lực giải quyết ở quy mô chưa từng có. Những thách thức lớn nhất của chúng ta chỉ có thể được giải đáp bằng các nghiên cứu đột phá mà chúng đòi hỏi sức mạnh của siêu máy tính ở quy mô chưa từng có. Các tổ chức sẵn sàng dẫn đầu ngành cần thu hút tài năng AI tốt nhất thế giới để thúc đẩy sự đổi mới và đi đầu về hạ tầng siêu máy tính có thể đưa họ đến đích ngay bây giờ, chứ không phải vài tháng nữa.
NVIDIA DGX SuperPOD, dựa trên hệ thống DGX A100, đánh dấu một cột mốc quan trọng trong sự phát triển của siêu máy tính, cung cấp một giải pháp có thể mở rộng mà bất kỳ doanh nghiệp nào cũng có thể có được và triển khai truy cập sức mạnh tính toán khổng lồ để thúc đẩy đổi mới kinh doanh. Doanh nghiệp có thể bắt đầu từ một SU duy nhất gồm 20 node và phát triển lên hàng trăm node. DGX SuperPOD đơn giản hóa việc thiết kế, triển khai và vận hành cơ sở hạ tầng AI khổng lồ với kiến trúc tham chiếu đã được xác thực, được cung cấp như một giải pháp chìa khóa trao tay thông qua các nhà phân phối giá trị gia tăng (Value-Added Distributor) cho NVIDIA như Nhất Tiến Chung. Giờ đây, mọi doanh nghiệp đều có thể mở rộng quy mô AI để giải quyết các thách thức quan trọng nhất của họ với cách tiếp cận đã được chứng minh, được hỗ trợ bởi ở cấp doanh nghiệp ở cấp độ 24×7.
Giới thiệu về NVIDIA
NVIDIA với xuất phát điểm từ hãng sản xuất card tăng tốc đồ họa từ năm 1993, đến nay, hãng đã chuyển mình thành công ty chuyên cung cấp giải pháp điện toán Data Center hiệu năng cao, siêu máy tính cho AI và phân tích dữ liệu.
Nhất Tiến Chung (NTC) là nhà cung cấp các giải pháp hạ tầng CNTT, Điện toán Hiệu năng cao (HPC) cho AI với kinh nghiệm kinh doanh phần cứng từ năm 2005. Chúng tôi là nhà phân phối chính thức của NVIDIA cho các hệ thống điện toán hiệu năng cao dựa trên GPU bao gồm DGX A100, DGX Station A100 và hệ thống cụm siêu máy tính DGX SuperPOD với sức mạnh lưu trữ song song của DDN và mạng tốc độ cao từ Mellanox.

