
“Bạn phải đập vỡ một vài quả trứng để làm món trứng ốp-la”.
Đây là một câu tục ngữ thú vị, với một vài câu chuyện lịch sử đáng nhớ mà có thể bạn đã từng trải. Cha mẹ của bạn luôn sẵn sàng nhắc đến những bài học, để áp dụng chúng vào các tình huống trong cuộc sống của bạn. Chi phí ngắn hạn tạo ra lợi nhuận lâu dài hơn!
Theo một cách nào đó, câu tục ngữ trên có thể áp dụng cho vấn đề ảo hóa hạ tầng CNTT. Chúng ta “mô phỏng” lại các hệ thống vật lý truyền thống bằng phần mềm. Điều này có thể tạo ra một cái giá phải trả cho hiệu suất, nhưng đừng quá lo lắng… những lợi ích đạt được của nó là thực tế và rất đáng qyan tâm.

Với ảo hóa máy chủ, thật dễ hiểu các lợi ích về chi phí này. Hiện nay, những môi trường này có thể thấy ở khắp mọi nơi, chúng ta thấy việc sử dụng ngày càng nhiều các kiến trúc máy chủ đa lõi, và chúng ta cũng thấy các quy trình quản lý được thực hiện hiệu quả và mạnh mẽ hơn.
Với ảo hóa lưu trữ, có thể khó thấy những lợi ích về chi phí này. Nó bắt đầu với thứ mà chúng ta đang ảo hóa. Đó là một thiết bị (có thể) kém thông minh, hoặc là một hệ thống lưu trữ tối tân, đắt tiền. Trong cả hai trường hợp, câu hỏi đặt ra là tại sao tôi lại phải ảo hóa những thứ như vậy?
Có những lợi ích đáng kể trong ảo hóa lưu trữ, bao gồm một số lợi ích không quá rõ ràng. Chúng có thể trở nên dễ dàng được chấp nhận hơn khi các lợi ích được nhìn thấy dễ dàng hơn.
Vậy thì, tại sao ảo hóa là một điều nên làm?
Trên trang giới thiệu về các hệ thống ảo hóa lưu trữ của nhà phân phối Hạ Tầng Mới, bạn sẽ tìm thấy ngôn ngữ điển hình được tìm thấy trên các trang của nhà cung cấp khác, nêu rõ các lợi ích khác nhau của ảo hóa lưu trữ:
- Giảm chi phí
- Cải thiện độ tin cậy
- Cải thiện hiệu năng hệ thống
- Tăng độ linh hoạt và khả năng mở rộng quy mô
Đây là những khẳng định và chúng có thể để lại cho người xem những câu hỏi. Tôi phải trả chi phí nào? Lợi ích thu được là gì, và bằng cách nào?
Hãy đập vỡ một số quả trứng tốt
Nhìn chung, ảo hóa là một lớp bổ sung của phần mềm. Có nhiều cách khác nhau để xây dựng lớp này. Jon Toigo đã viết về các phương pháp in-band so với phương pháp out-of-band, nhưng cuối cùng chúng đều là các lớp bổ sung phải được đi qua trong đường dẫn dữ liệu.
Bằng cách đưa vào lớp ảo hóa lưu trữ, chúng tôi đã sử dụng các thiết bị đọc và ghi và gói chúng trong phần mềm mô phỏng các thiết bị đọc và ghi. Nghe có vẻ như chẳng để làm gì! Tại sao chúng ta làm điều đó?
Món ốp-la thơm lừng nằm ở đâu?
Lợi ích ở đây là chúng ta đã tạo một vị trí trong đường dẫn dữ liệu cho các máy tính đa năng, mạnh mẽ chạy phần mềm trên đó. Điều này tạo ra các giá trị tiềm năng to lớn của nó, bao gồm những điểm có thể nhắc lại sau đây:
- Giảm chi phí
- Cải thiện độ tin cậy
- Cải thiện hiệu suất
- Tăng độ linh hoạt và khả năng mở rộng quy mô
Để xem những lợi ích này được thực hiện như thế nào, hãy đào sâu vào vấn đề ảo hóa.
Điểm sáng ở cách tương tác
Cách các ứng dụng tương tác với bộ lưu trữ đôi khi được gọi là phương thức truy cập. Phương thức truy cập có thể được mô phỏng dưới dạng giao diện lập trình ứng dụng, hay API. API xác định hành vi mong đợi và nó cung cấp cho chúng ta một framework thuận tiện để thực hiện ảo hóa.
Block Storage là một phương pháp truy cập và SCSI Architecture Model (SAM) xác định “thủ tục thực thi lệnh từ xa” này:

Giảm chi phí
Đầu tiên, chúng ta có thể biểu diễn các khối chứa đầy các số 0… mà không có gì trong đó cả! Các khối số 0 không cần phải lưu trữ — đó là một phương pháp cấp phép mỏng (thin provisioning) phổ biến. Thin provisioning giúp lập kế hoạch lưu trữ dễ dàng hơn. Nó làm tăng việc sử dụng dung lượng cơ bản, nhằm giảm chi phí. Thực hiện ý tưởng đó thêm một bước nữa và bạn sẽ đạt được chức năng Deduplication, trong đó các dãy trùng lặp của các khối dữ liệu được băm thành các phiên bản đơn lẻ trong pool lưu trữ.
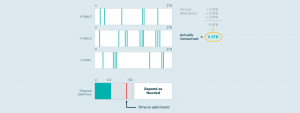
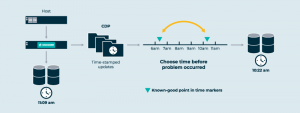
Chúng ta có thể theo dõi các mẫu truy cập vào các khối ảo, tổng hợp thành các mức “nhiệt độ” cho mỗi khối, sau đó sắp xếp chúng trong một nhóm lưu trữ để dữ liệu nóng (hot data) đi vào thiết bị nhanh, đắt tiền và dữ liệu lạnh (cold data) đi vào các thiết bị hoặc dịch vụ đám mây có tốc độ chậm, rẻ tiền. Tính năng tự động xếp hạng này sắp xếp dữ liệu trong các ổ đĩa ảo, để các ứng dụng nhìn thấy dữ liệu chúng muốn, trong khi hệ thống ảo hóa sẽ tối ưu hóa chi phí và hiệu suất một cách linh hoạt và tự động. Điều này tiếp tục làm giảm chi phí, thậm chí là trong lúc đã cải thiện về hiệu suất. Xem thêm minh họa bên dưới.
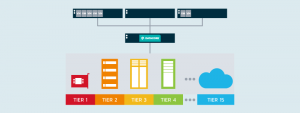
Cải thiện độ tin cậy
Các khối dữ liệu có thể được lưu trữ ở hai hoặc nhiều nơi, trên các nền tảng phần cứng, để tạo tính sẵn sàng cao và đề phòng các điểm lỗi.
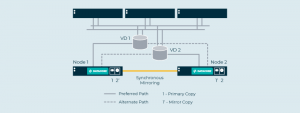
Các khối dữ liệu có thể được truyền qua Internet để chuẩn bị cho các kịch bản thảm họa có thể xảy ra.

Cải thiện sự linh hoạt và khả năng mở rộng quy mô
Các ổ đĩa ảo vẫn không thay đổi về mặt logic, trong khi các khối dữ liệu được tự động di chuyển bên dưới. Điều này giúp bạn dễ dàng thực hiện việc di trú (migration). Đưa vào một hệ thống lưu trữ mới, kết nối nó với hệ thống bên dưới của phần mềm ảo hóa lưu trữ, và dữ liệu di chuyển tự động và liền mạch sang hệ thống lưu trữ mới.
Cần mở rộng theo chiều ngang (scale-out)? Thêm nhiều node hơn để thực hiện ảo hóa lưu trữ, để tạo kiến trúc N + 1. Di chuyển các đĩa ảo giữa các node này, tương tự như khái niệm di chuyển trực tiếp của các máy ảo, để cân bằng lại toàn bộ tải của hệ thống.
Cải thiện hiệu suất
Có vẻ rằng tất cả các xử lý và các công việc phức tạp bổ sung này làm tăng độ trễ và giảm thông lượng? Không hẳn là như thế, và nó còn thú vị hơn cho tất cả các dịch vụ dữ liệu đang sử dụng.
Làm sao nó có thể đạt được điều đó? Hãy nhớ lại chúng tôi đã đề cập đến việc bạn có thể có một nền tảng máy chủ đa lõi hiện đại với đầy đủ RAM tốc độ cao và hàng chục CPU xử lý song song.
Sử dụng chúng!
Lưu cahce các dữ liệu nóng vào trong RAM. Sử dụng tính năng remote synchronous mirroring để bảo vệ bộ nhớ cache trong RAM khỏi các lỗi riêng lẻ. Xử lý các yêu cầu I/O song song trên nhiều CPU nhất có thể. Cột tất cả những con gà đó vào mốt chiếc cày! Giữ mọi “transitor” bận rộn trong quá trình triển khai ảo hóa của bạn. Độ trễ trung bình sẽ giảm xuống và thông lượng chung sẽ tăng lên đáng kể. Nó nghe có vẻ phi trực quan, nhưng ảo hóa thực sự mang lại hiệu suất cao hơn!
Tất cả những lợi ích này đến từ việc chơi trò chơi với không gian địa chỉ khối (block address space). Và chúng tôi thậm chí còn không nói về các dịch vụ dữ liệu phức tạp hơn, như việc tạo ra các “snapshot instant copies” của đĩa ảo, hoặc mã hóa dữ liệu trong lúc hệ thống đang nghỉ. Tiềm năng là gần như vô hạn.
Ảo hóa I/O
Có một cách khác để nghĩ về ảo hóa cho lưu trữ khối (block storage). Ở trên chúng ta đã thấy trò chơi ảo hóa địa chỉ của các khối. Điều gì sẽ xảy ra nếu chúng ta chơi trò chơi theo cách khác? Chúng ta cũng có thể ảo hóa các I/O request riêng lẻ.
Điều đó có nghĩa là gì? Đến đây, bạn không cần phải suy nghĩ nhiều về việc ánh xạ lại các khối và suy nghĩ nhiều hơn về “Làm cách nào để trả lời yêu cầu Read này?” và “Làm cách nào để trả lời yêu cầu Write này?” Điều này mở ra những luồng suy nghĩ khác nhau, với những khả năng khác nhau.
Thay vì ánh xạ lại các trang của địa chỉ khối như một hệ thống bộ nhớ ảo cơ bản, chúng ta có thể sắp xếp dữ liệu theo bất kỳ cách nào chúng ta muốn trong quá trình triển khai của mình .
Chúng ta có thể sắp xếp nó một cách tuần tự, giống như một khúc gỗ. Điều đó chỉ có ý nghĩa tích cực về hiệu suất đối với các workload ghi ngẫu nhiên .
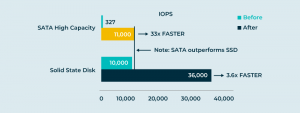
Chúng ta có thể bỏ qua trình tự và cấu trúc của các yêu cầu I/O riêng lẻ trong nhật ký đó, để tập trung vào bố cục tuần tự dẫn đến hiệu suất truyền dẫn. Nhưng nếu chúng ta duy trì trình tự và cấu trúc của các yêu cầu riêng lẻ, chúng ta sẽ xây dựng vào nhật ký một khái niệm về thời gian. Đột nhiên, chúng tôi có một hệ thống sẵn sàng hỗ trợ Bảo vệ dữ liệu liên tục (CDP), nơi tôi có thể ngay lập tức tạo hình ảnh của một đĩa ảo như nó đã tồn tại trong quá khứ. Trong tất cả những điều thú vị bạn có thể làm với phần mềm, du hành thời gian phải là một trong những điều thú vị nhất.
Ảo hóa tệp
Điều gì sẽ xảy ra nếu chúng ta sử dụng các phương thức truy cập khác để ảo hóa các miền lưu trữ khác? Các giao thức hệ thống tệp mạng là một lĩnh vực đa dạng khác để ảo hóa. Một lần nữa, phương pháp truy cập gợi ý một API và nó cung cấp cho chúng ta một framework để ảo hóa tệp.
Hệ thống lưu trữ tệp có dữ liệu tệp và siêu dữ liệu tệp: phân cấp namespace, tên thư mục, tên tệp, thời gian tạo, truy cập và sửa đổi tệp. Nhiều thứ để kết hợp cùng nhau! Hãy chơi trò chơi với dữ liệu và siêu dữ liệu.
Tách các mối quan tâm
Chúng tôi có thể tách siêu dữ liệu tệp khỏi dữ liệu tệp. Tại sao điều đó lại thú vị? Có hai lý do: vấn đề tổ chức và hiệu năng.
Một sự tương tự hữu ích ở đây là thư viện công cộng. Nếu chúng ta nghĩ cụ thể về các thư viện công cộng nhiều năm trước đây với các chỉ mục danh mục thẻ vật lý của họ, chúng ta sẽ có thể thấy rõ hơn sự phân tách và ý nghĩa của nó. Có một chỉ mục danh mục thẻ (siêu dữ liệu) và có sách trên giá (dữ liệu).
Danh mục thẻ được sắp xếp để truy cập nhanh chóng và dễ dàng. Nó ở phía trước của thư viện, dễ dàng tiếp cận. Nó được sắp xếp theo Chủ đề, Tác giả và Tiêu đề, để dễ sử dụng. So với đống sách, chỉ số này khá nhỏ. Chỉ mục được sắp xếp và tối ưu hóa theo yêu cầu của người dùng .

Các cuốn sách có thể và nên được sắp xếp riêng biệt theo các yêu cầu lưu trữ hoàn toàn khác nhau . Sách hiếm được đặt trong các khu vực lưu trữ đắt tiền, được kiểm soát khí hậu, với rất ít người qua lại. Bìa mềm ở một vị trí khác, rẻ hơn và có nhiều khả năng có lượng truy cập cao, cùng với các ấn phẩm định kỳ. Khối lượng foo và quarto lớn hơn đi trên giá đỡ đặc biệt có thể chứa kích thước bất thường của chúng. Những cuốn sách hiếm được truy cập có thể xuất hiện ngoài trang web.

Điều này quá tự nhiên và hiển nhiên, chúng ta hầu như không nghĩ đến. Nhưng hãy tưởng tượng nếu danh mục thẻ được dệt khắp các ngăn xếp, giữa các cuốn sách và giá sách, và bạn bắt đầu thấy việc trộn siêu dữ liệu và dữ liệu với nhau có thể gây ra sự cố cho các ứng dụng truy cập hệ thống lưu trữ như thế nào.
Bây giờ hãy xem xét một thư viện chi nhánh. Chúng tôi có thể sắp xếp để chi nhánh đó cung cấp toàn bộ bộ sưu tập toàn cầu, ngay cả khi rất ít sách được lưu trữ ở đó. Chúng tôi chia sẻ danh mục thẻ chính với chi nhánh để người dùng danh mục chi nhánh thấy toàn bộ tập hợp chung (‘không gian tên’). Một hệ thống giao hàng đảm nhận việc mang sách theo yêu cầu. Rõ ràng là cách tách siêu dữ liệu khỏi dữ liệu làm cho điều này có thể thực hiện được. (Rõ ràng là các nhà khoa học máy tính có thể học được nhiều điều từ các thủ thư, nhưng đó là một câu chuyện khác .)
Bằng cách xử lý siêu dữ liệu tệp một cách riêng biệt, chúng tôi có thể xây dựng một không gian tên chung giúp xóa tan ranh giới cấp thiết bị. Chúng tôi có thể thay đổi siêu dữ liệu tệp để phản ánh các yêu cầu ứng dụng hoặc quản lý, cho phép dữ liệu tệp có thể di chuyển theo một lịch trình khác, theo các yêu cầu hoàn toàn khác. Chúng tôi có thể chia sẻ siêu dữ liệu để tạo không gian tên chung cộng tác trên nhiều trang web. Chúng tôi có thể nâng cao siêu dữ liệu bằng các thẻ và giá trị tùy chỉnh, tăng khả năng sử dụng (và giá trị!) Của tất cả dữ liệu tệp đó.
Việc tách siêu dữ liệu tệp khỏi dữ liệu giúp mang lại hiệu suất cao. Các tiêu chuẩn NFS song song xác định hợp đồng giữa máy khách và máy chủ, để chúng có thể tận dụng lợi ích của hiệu suất vốn có trong việc tách biệt các mối quan tâm này.
Công nghệ ảo hóa tệp hứa hẹn sẽ có liên quan và thú vị như ảo hóa lưu trữ khối đã có trong hai mươi năm.
Chúng tôi giữ sự thật này làm bằng chứng cho mình
Vấn đề là, phương pháp truy cập cung cấp cho bạn một mô hình ảo hóa, cung cấp cho bạn một nơi để chèn phần mềm và sức mạnh tính toán, mang lại cho bạn sức mạnh và tiềm năng cho sự bùng nổ kỷ Cambri về các giải pháp giàu trí tưởng tượng cho các vấn đề về dữ liệu và lưu trữ.
Hệ thống ảo hóa đi kèm với cái giá tương ứng, nhưng chúng dường như luôn chứng minh được giá trị của nó theo những cách đáng quan tâm. Thật an toàn khi nói rằng ảo hóa được chứng minh trong nhiều trường hợp là có lợi nhiều hơn. An toàn, nhưng yếu. Làm việc cẩn thận hơn một chút, chúng ta có thể nói điều gì đó mạnh hơn – rằng ảo hóa dường như luôn tạo ra những lợi ích này, giống như một quy luật tự nhiên.
Thậm chí còn thú vị hơn khi nói rằng lợi ích của ảo hóa là tiên đề, không yêu cầu bằng chứng và bất cứ nơi nào bạn nhìn thấy phần cứng, bạn nên đập vỡ những “quả trứng” đó, bởi vì bạn sẽ luôn nhận được một món ốp-la thơm lừng.
_________
Đọc thêm:
SANsymphony là giải pháp lưu trữ do phần mềm xác định từng đoạt giải thưởng của DataCore, bao gồm một lớp ảo hóa khối nâng cao.
DataCore vFilO cung cấp công nghệ ảo hóa lưu trữ file phân tán thế hệ tiếp theo để kiểm soát cuối cùng dữ liệu dựa trên tệp.
DataCore ONE là tầm nhìn chiến lược nhằm thống nhất ngành công nghiệp lưu trữ thông qua công nghệ ảo hóa tiên tiến của DataCore, được quản lý dưới một bảng điều khiển phân tích dự đoán thống nhất.
DataCore đã có mặt trên thị trường hơn 10 năm và hiện được nhà phân phối Hạ Tầng Mới – CSC cung cấp tại thị trường Việt Nam.
![]()
![]()
Bạn muốn trở thành đối tác bán hàng Datacore của NTC?
Bài viết liên quan
- U.2 SSD: “Chiến binh” hiệu năng cao ẩn mình trong thế giới lưu trữ doanh nghiệp
- Giải pháp tích hợp AI vào hệ thống lưu trữ dữ liệu doanh nghiệp: Tương lai đã đến!
- Giải pháp lưu trữ của Infortrend: Cách mạng hóa Quản lý Dữ liệu Y tế
- Cập nhật danh mục lưu trữ của Infortrend: Từ AI đến Hạ tầng Doanh nghiệp
- Lưu trữ doanh nghiệp năm 2025: 6 xu hướng không thể bỏ qua
- Infortrend GS 5000U: Một lựa chọn lưu trữ tối ưu cho đào tạo mô hình AI