
Vào ngày 6/8/2025 vừa qua, OpenAI đã công bố phát hành hai mô hình ngôn ngữ mới là gpt-oss-120b và gpt-oss-20b – dưới dạng open-weight.
Đây là một sự kiện có thể nói là gây chấn động với cộng đồng AI, không chỉ vì năng lực của mô hình mà còn vì đây là lần đầu tiên sau 6 năm, kể từ năm 2019, OpenAI đã thay đổi chiến lược và tham gia vào “cuộc đua mô hình mở” cùng với các đối thủ như Meta, Mistral, hay DeepSeek.
Vậy GPT-OSS là gì?
GPT-OSS là tên gọi cho hai mô hình ngôn ngữ do OpenAI phát triển có kích thước lần lượt là 20 tỷ và 120 tỷ tham số. Cả hai mô hình này đều được công bố rộng rãi và miễn phí dưới dạng open-weight, nghĩa là các trọng số của mô hình sau khi đã huấn luyện được công khai, người dùng có thể tải về và sử dụng trực tiếp trên máy của mình.

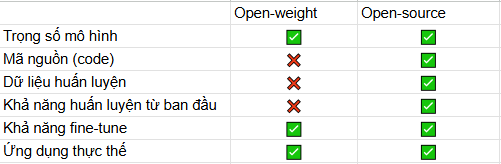
Tuy nhiên, đây không phải là open-source đầy đủ, vì OpenAI không công bố mã code huấn luyện hoặc dữ liệu gốc như trong các mô hình mã nguồn mở truyền thống. Vì thế nhiều người đang hiểu lầm việc OpenAI công bố hai mô hình ngôn ngữ mới là open-source. Nhưng trên thực tế, OpenAI chỉ công bố weights và model card dưới giấy phép Apache 2.0.
Open-weight là gì? Nó khác gì so với open-source?
Như đã nói ở trên, open-weight có thể hiểu đơn giản là các “trọng số” của các mô hình AI đã được huấn luyện sẵn và được công khai rộng rãi, người dùng có thể tải, triển khai và sử dụng trực tiếp. Tuy nhiên, quy trình huấn luyện, mã nguồn và tập dữ liệu sẽ không được công bố.
Ở khía cạnh khác, open-source là một khái niệm rộng hơn. Mô hình được xem là open-source khi toàn bộ mã nguồn, tài liệu huấn luyện, trọng số và đôi khi là cả tập dữ liệu cũng sẽ được công bố công khai. Điều nay cho phép cộng đồng và người dùng có thể:
- Xem, sửa, huấn luyện lại mô hình
- Fine-tune mô hình
Vậy GPT-OSS có khả năng fine-tune được hay không?
Câu trả lời là có. Mặc dù bị thiếu code gốc, tuy nhiên nhờ vào cộng đồng lớn và mạnh mẽ, nhất là Hugging Face, ngay sau khi GPT-OSS được ra mắt, nó đã được tích hợp vào thư viện transformer và được hỗ trợ các kỹ thuật fine-tuning tiết kiệm tài nguyên như LoRA, PEFT, QLoRA.
Tuy nhiên, vì sự thiếu sót về script huấn luyện gốc nên việc fine-tune sẽ trở nên khó khăn và phức tạp hơn so với các mô hình mở như LLaMA 3.
Dưới đây là đường link dẫn đến hai mô hình trên Hugging Face dành cho bạn nào muốn đọc thêm về mô hình:
- gpt-oss-20b: https://huggingface.co/openai/gpt-oss-120b
- gpt-oss-120b: https://huggingface.co/openai/gpt-oss-120b
Dưới đây là bảng tóm tắt cho các bạn có thể hình dung:
GPT-OSS có gì đặc biệt?
Cả hai mô hình GPT-OSS đều áp dụng kiến trúc MoE ( Mixture-of-Experts ). Đây là một trong những đột phá gần đây trong thiết kế mô hình AI hiệu suất cao, để giảm số lượng tham số hoạt động cần thiết khi xử lý dữ liệu đầu vào. Mô hình gpt-oss-120b kích hoạt 5,1 tỷ tham số trên mỗi token, trong khi gpt-oss-20b kích hoạt được 3,6 tỷ tham số. Các mô hình này lần lượt có tổng tham số là 117 tỷ và 21 tỷ.
Ngoài ra, mô hình gpt-oss-120b đạt hiệu năng gần tương đương với OpenAI o4-mini, đồng thời vận hành hiệu quả trên một GPU 80 GB duy nhất. Mô hình gpt-oss-20b cho kết quả tương đương với OpenAI o3‑mini và có thể chạy trên các thiết bị biên chỉ cần 16 GB VRAM, từ đó trở thành mô hình lý tưởng cho các trường hợp sử dụng trên thiết bị, suy luận cục bộ, hoặc lặp lại nhanh mà không cần cơ sở hạ tầng tốn kém. Các nhận định trên đã được OpenAI tiến hành đánh giá và ghi nhân thông qua các bài kiểm tra về tư duy cốt lõi và đánh giá đối chuẩn thông thường.
GPT-OSS còn được thiết kế để hiển thị toàn bộ chuỗi suy luận nội bộ (full chain-of-thought), giúp người dùng và nhà phát triển dễ dàng theo dõi và gỡ lỗi logic mà mô hình đã đi qua trước khi đưa ra kết luận cuối cùng. Ngoài ra, mô hình cũng tập trung vào khả năng suy luận, có thể điều chỉnh mức suy luận cho các tác vụ không cần suy luận phức tạp. Đồng thời, nó sử dụng các công cụ như tìm kiếm trên web hoặc thực thi lệnh Python nhằm đưa ra kết quả cuối cùng với độ trễ thấp.
OpenAI còn đặt sự an toàn là nền móng để phát hành các mô hình, đặc biệt là với các mô hình mở. Vậy nên, khi phát hành mô hình GPT-OSS theo giấy phép Apache 2.0 – một trong những giấy phép thân thiện nhất với cả thương mại và phi thương mại, OpenAI đã cho phép cộng động và người dùng của mình tự do tải về, chỉnh sửa và phát triển mà vẫn đảm bảo về các tiêu chuẩn an toàn tương tự với các mô hình độc quyền khác.
Vì sao OpenAI lại công bố miễn phí?
Lí do được cho là lớn nhất để OpenAI công bố miễn phí mô hình GPT-OSS là vì để cạnh tranh và dành lại vị thế trước các đối thủ như Meta với mô hình Llama3, Llama4 có khả năng mạnh về ngôn ngữ châu Âu hoặc DeepSeek đến từ Trung Quốc, khi liên tục tung ra các mô hình open-weight hiệu suất cao.
Việc tung ra các mô hình open-weight còn thể hiện cam kết của OpenAI là đảm bảo rằng [trí tuệ nhân tạo tổng quát] mang lại lợi ích cho toàn nhân loại – “OpenAI’s mission is to ensure [artificial general intelligence] that benefits all of humanity“, trích lời của Sam Atlman, CEO của OpenAI.
Với hai mô hình trên, OpenAI còn thúc đẩy sự sáng tạo và phát triển khi trao toàn quyền tối đa cho người dùng. Từ việc fine-tune cho các bài toán đặc thù, cho đến triển khai trên môi trường riêng tư mà không phụ thuộc vào API thương mại.
Kết luận
GPT‑OSS không chỉ là một bộ mô hình ngôn ngữ mạnh mẽ, mà còn là lời khẳng định của OpenAI rằng: “mở” không có nghĩa là “yếu”, và trách nhiệm không nhất thiết phải loại trừ quyền tự do. Trong một thế giới AI đang chia hai cực – mã nguồn mở và nền tảng đóng – GPT‑OSS đóng vai trò như chiếc cầu nối, mở ra cơ hội sáng tạo mới đồng thời thúc đẩy cạnh tranh lành mạnh.
Trong thời gian tới, mình sẽ có bài hướng dẫn chi tiết cách tải, chạy thử và fine-tune GPT-OSS cho các bài toán thực tế. Các bạn nhớ theo dõi nhé!
Mọi thắc mắc có thể liên hệ mình qua email: anldb@nhattienchung.vn
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- Hướng dẫn chi tiết sử dụng mô hình GPT-OSS-20B trên máy tính của bạn
- Tăng tốc các mô hình mở mới của OpenAI ngay trên GPU NVIDIA GeForce RTX và RTX PRO
- Nhận diện khuôn mặt với NVIDIA FaceDetect: Cài đặt và huấn luyện mô hình bằng TAO Toolkit