
Sự ra đời của LLM – NLP và Neural Networks
Việc tạo ra các Mô hình ngôn ngữ lớn không diễn ra trong một sớm một chiều. Đáng chú ý là khái niệm đầu tiên về các mô hình ngôn ngữ bắt đầu với các hệ thống dựa trên quy tắc được gọi là Xử lý ngôn ngữ tự nhiên. Các hệ thống này tuân theo các quy tắc được xác định trước để đưa ra quyết định và suy ra kết luận dựa trên đầu vào văn bản. Các hệ thống này dựa vào các câu lệnh if-else xử lý thông tin từ khóa và tạo ra các đầu ra được xác định trước. Hãy nghĩ đến một cây quyết định trong đó đầu ra là một phản hồi được xác định trước nếu đầu vào chứa X, Y, Z hoặc không có. Ví dụ: Nếu đầu vào bao gồm các từ khóa “mẹ”, đầu ra là “Mẹ bạn thế nào?”. Nếu không, đầu ra là “Bạn có thể giải thích thêm về điều đó không?”
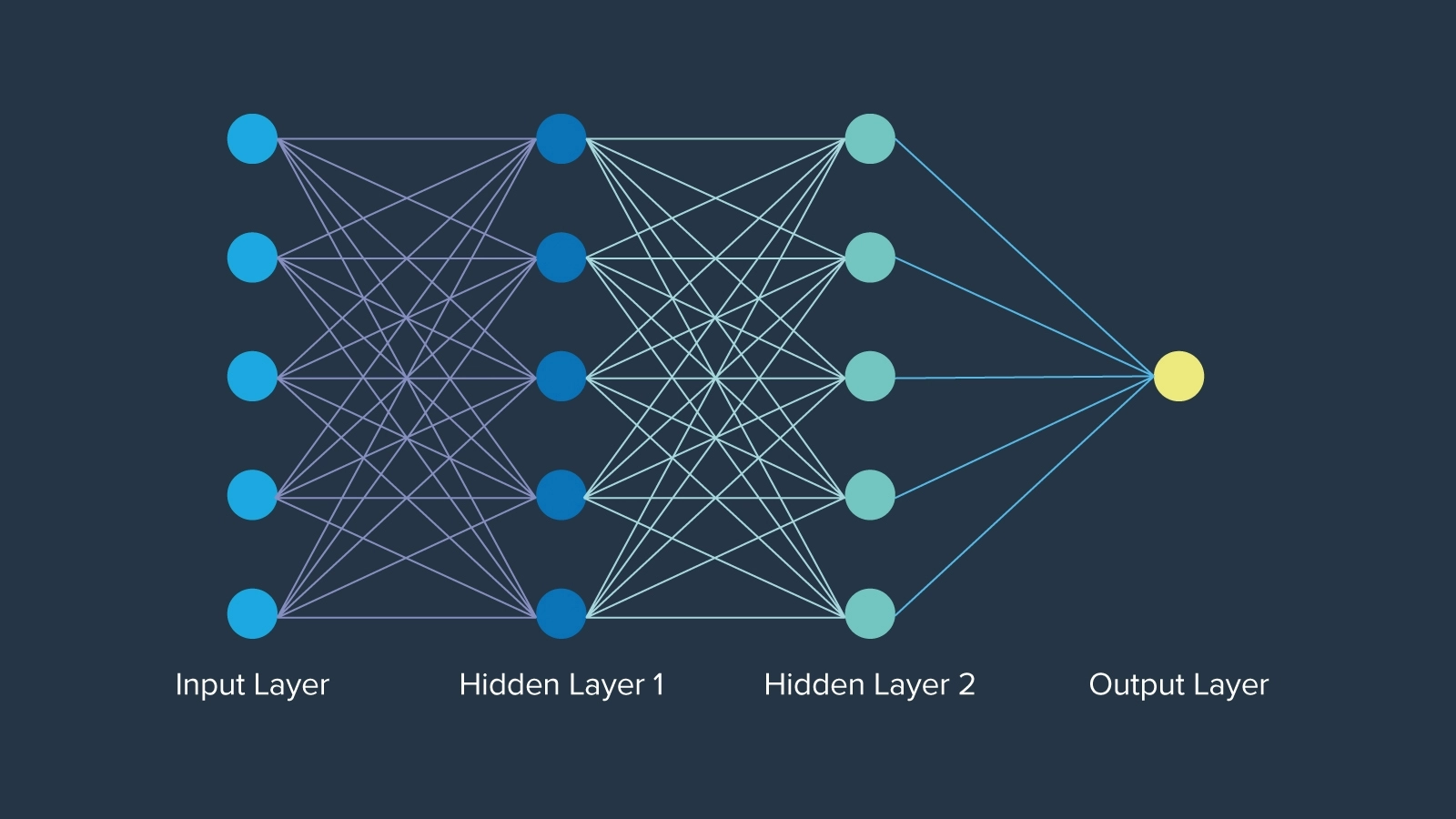
Tiến bộ ban đầu lớn nhất là mạng nơ-ron (Neural Networks), được biết đến khi lần đầu tiên được giới thiệu vào năm 1943 lấy cảm hứng từ các nơ-ron trong chức năng não người, bởi nhà toán học Warren McCulloch. Mạng nơ-ron thậm chí còn có trước thuật ngữ “trí tuệ nhân tạo” khoảng 12 năm. Mạng nơ-ron trong mỗi lớp được tổ chức theo một cách cụ thể, trong đó mỗi nút giữ một trọng số xác định tầm quan trọng của nó trong mạng. Cuối cùng, mạng nơ-ron đã mở ra những cánh cửa bị đóng kín, tạo nên nền tảng mà AI từ đó được xây dựng lên cho đến ngày nay.

Sự phát triển của LLM – Embeddings, LSTM, Attention & Transformers
Máy tính không thể hiểu được ý nghĩa của các từ kết hợp với nhau trong một câu theo cùng cách mà con người có thể hiểu. Để cải thiện khả năng hiểu của máy tính cho các phân tích ngữ nghĩa, trước tiên phải áp dụng kỹ thuật nhúng từ cho phép các mô hình nắm bắt mối quan hệ giữa các từ lân cận dẫn đến hiệu suất được cải thiện trong nhiều tác vụ NLP khác nhau. Tuy nhiên, cần phải có phương pháp lưu trữ “nhúng” từ ngữ trong bộ nhớ.
Long Short-Term Memory (LSTM) và Gated Recurrent Units (GRU) là những bước tiến lớn trong mạng nơ-ron, với khả năng xử lý dữ liệu tuần tự hiệu quả hơn so với mạng nơ-ron truyền thống. Mặc dù LSTM không còn được sử dụng nữa, nhưng các mô hình này đã mở đường cho các tác vụ hiểu và tạo ngôn ngữ phức tạp hơn mà cuối cùng là dẫn đến mô hình chuyển hóa (transformer model).
LLM hiện đại – Attention, Transformers và các biến thể LLM
Việc đưa ra “cơ chế chú ý” (attention mechanism) là một bước ngoặt, cho phép các mô hình tập trung vào các phần khác nhau của chuỗi đầu vào khi đưa ra dự đoán. Các mô hình transformer, được giới thiệu cùng với bài báo quan trọng “Attention is All You Need” vào năm 2017, đã tận dụng cơ chế chú ý để xử lý toàn bộ chuỗi tuần tự một cách đồng thời, cải thiện đáng kể cả hiệu quả và hiệu suất. Tám nhà khoa học của Google đã không nhận ra những cơn sóng mà bài báo của họ sẽ tạo nên trong việc tạo ra AI ngày nay.
Tiếp theo bài báo, BERT (2018) của Google đã được phát triển và được công bố là cơ sở cho tất cả các tác vụ NLP, đóng vai trò là mô hình nguồn mở được sử dụng trong nhiều dự án cho phép cộng đồng AI xây dựng các dự án và phát triển. Khả năng hiểu ngữ cảnh, bản chất được đào tạo trước và tùy chọn tinh chỉnh, cùng với việc trình diễn các mô hình chuyển hóa đã tạo tiền đề cho các mô hình lớn hơn.
Cùng với BERT, OpenAI đã phát hành GPT-1, phiên bản đầu tiên của mô hình transformer của họ. GPT-1 (2018), bắt đầu với 117 triệu tham số, tiếp theo là GPT-2 (2019) với bước nhảy vọt lên 1,5 tỷ tham số, với sự tiến triển tiếp tục với GPT-3 (2020), tự hào có 175 tỷ tham số. ChatGPT, chatbot đột phá của OpenAI, dựa trên GPT-3, đã được phát hành hai năm sau đó vào ngày 30 tháng 11 năm 2022, đánh dấu một cơn sốt đáng kể và thực sự dân chủ hóa quyền truy cập vào các mô hình AI mạnh mẽ. Tìm hiểu về sự khác biệt giữa BERT và GPT-3.
Những tiến bộ công nghệ nào đang thúc đẩy tương lai của LLM?
Tiến bộ về phần cứng, cải tiến về thuật toán và phương pháp thực thi, và tích hợp đa phương thức đều góp phần vào sự tiến bộ của các mô hình ngôn ngữ lớn. Khi ngành điện toán tìm ra những cách mới để sử dụng LLM hiệu quả, sự tiến bộ liên tục sẽ tự điều chỉnh theo từng ứng dụng và cuối cùng sẽ thay đổi hoàn toàn bối cảnh của ngành.
Tiến bộ trong phần cứng
Phương pháp đơn giản và trực tiếp nhất để cải thiện LLM là cải thiện phần cứng thực tế mà mô hình chạy trên đó. Sự phát triển của phần cứng chuyên dụng như các Bộ xử lý đồ họa (GPU) đã đẩy nhanh đáng kể quá trình đào tạo và suy luận của các mô hình ngôn ngữ lớn. GPU, với khả năng xử lý song song, đã trở nên thiết yếu để xử lý lượng dữ liệu khổng lồ và các phép tính phức tạp mà LLM yêu cầu.
OpenAI sử dụng GPU NVIDIA để cung cấp sức mạnh cho các mô hình GPT của mình, và họ cũng chính là một trong những khách hàng đầu tiên của NVIDIA DGX. Mối quan hệ của họ kéo dài từ khi AI xuất hiện cho đến khi AI tiếp tục phát triển, khi vị CEO của NVIDIA đã tự tay trao tặng NVIDIA DGX-1 đầu tiên, cũng như hệ thống NVIDIA DGX H200 mới nhất. Các GPU này kết hợp một lượng lớn bộ nhớ lớn và khả năng điện toán song song để đẩy mạnh hiệu suất đào tạo, triển khai và suy luận.

Tăng tốc đào tạo AI với NVIDIA DGX H200
Đào tạo các mô hình AI trên các tập dữ liệu lớn có thể được tăng tốc theo cấp số nhân với hệ thống phù hợp. Nó không chỉ là một máy tính hiệu suất cao mà còn là một công cụ thúc đẩy và tăng tốc nghiên cứu của bạn. Triển khai nhiều node NVIDIA DGX để tăng khả năng mở rộng. Hệ thống này có thể được giảm giá với khách hàng khối giáo dục!
Cải tiến về thuật toán và kiến trúc
Kiến trúc transformer được biết đến nhiều vì nó hỗ trợ cho LLM. Việc đưa ra kiến trúc này đóng vai trò then chốt trong sự tiến bộ của LLM như chúng ta thấy hiện nay. Khả năng xử lý toàn bộ chuỗi một cách đồng thời thay vì tuần tự đã cải thiện đáng kể hiệu quả và hiệu suất của mô hình.
Tuy nhiên, chúng ta vẫn có thể kỳ vọng nhiều hơn vào kiến trúc transformer và cách nó có thể tiếp tục phát triển các Mô hình ngôn ngữ lớn.
- Việc cải tiến liên tục mô hình transformer engine, bao gồm các cơ chế Attention tốt hơn và các kỹ thuật tối ưu hóa, sẽ tạo ra các mô hình chính xác hơn và nhanh hơn.
- Nghiên cứu về các kiến trúc mới, chẳng hạn như ‘sparse transformer’ và ‘efficient attention mechanisms’, nhằm mục đích giảm yêu cầu tính toán trong khi vẫn duy trì hoặc nâng cao hiệu suất.
Tích hợp các đầu vào đa phương thức
Tương lai của LLM nằm ở khả năng xử lý các đầu vào đa phương thức, tích hợp văn bản, hình ảnh, âm thanh và các dạng dữ liệu khác để tạo ra các mô hình phong phú hơn và có nhận thức về ngữ cảnh hơn. Các mô hình đa phương thức như CLIP và DALL-E của OpenAI đã chứng minh được tiềm năng kết hợp thông tin trực quan và văn bản, cho phép ứng dụng trong việc tạo hình ảnh, chú thích và nhiều hơn nữa.
Những tích hợp này cho phép LLM thực hiện các nhiệm vụ phức tạp hơn, chẳng hạn như hiểu ngữ cảnh từ cả văn bản và tín hiệu trực quan, giúp chúng trở nên linh hoạt và mạnh mẽ hơn.
Tương lai của LLM
Những tiến bộ không dừng lại và sẽ còn nhiều hơn nữa khi những người sáng tạo LLM có kế hoạch kết hợp nhiều kỹ thuật và hệ thống sáng tạo hơn vào công việc của họ. Không phải mọi cải tiến trong LLM đều đòi hỏi tính toán khắt khe hơn hoặc hiểu biết khái niệm sâu sắc hơn. Một cải tiến quan trọng là phát triển các mô hình nhỏ hơn, thân thiện với người dùng hơn.
Mặc dù các mô hình này có thể không đạt được hiệu quả như “Mammoth LLM” như GPT-4 và LLaMA 3, nhưng điều quan trọng cần nhớ là không phải tất cả các tác vụ đều yêu cầu tính toán lớn và phức tạp. Mặc dù có kích thước lớn, các mô hình nhỏ hơn tiên tiến như Mixtral 8x7B và Mistal 7B vẫn có thể mang lại hiệu suất ấn tượng. Sau đây là một số lĩnh vực và công nghệ chính dự kiến sẽ thúc đẩy sự phát triển và cải tiến của LLM:
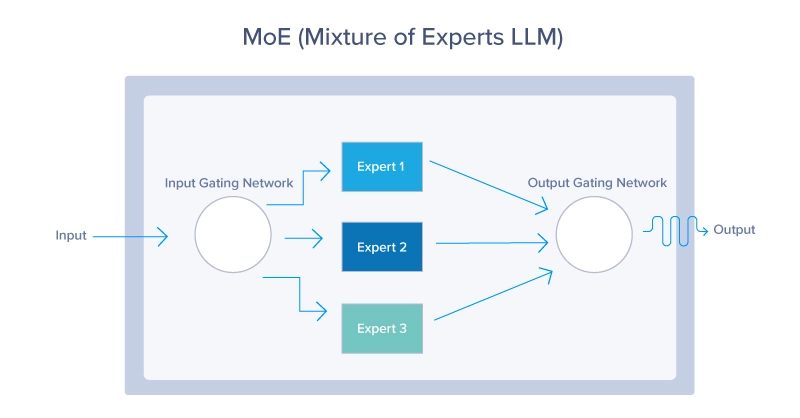
1. Mixture of Experts (MoE)
Các mô hình MoE sử dụng cơ chế định tuyến động để chỉ kích hoạt một tập hợp con các tham số của mô hình cho mỗi đầu vào. Cách tiếp cận này cho phép mô hình mở rộng hiệu quả, kích hoạt các “chuyên gia” có liên quan nhất dựa trên ngữ cảnh đầu vào, như được thấy bên dưới. Các mô hình MoE cung cấp một cách để mở rộng LLM mà không làm tăng chi phí tính toán theo tỷ lệ. Bằng cách chỉ tận dụng một phần nhỏ của toàn bộ mô hình tại bất kỳ thời điểm nào, các mô hình này có thể sử dụng ít tài nguyên hơn trong khi vẫn cung cấp hiệu suất tuyệt vời.
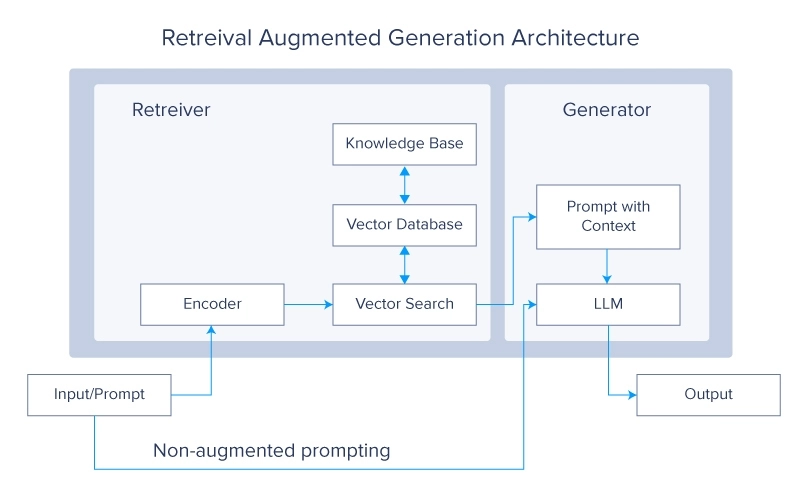
2. Retrieval-Augmented Generation (RAG)
Hệ thống Retrieval Augmented Generation hiện đang là chủ đề rất nóng trong cộng đồng LLM. Khái niệm này đặt ra câu hỏi tại sao bạn phải đào tạo LLM trên nhiều dữ liệu hơn khi bạn có thể chỉ cần khiến nó truy xuất dữ liệu mong muốn từ một nguồn bên ngoài. Sau đó, dữ liệu đó được sử dụng để tạo ra câu trả lời cuối cùng.
Hệ thống RAG tăng cường LLM bằng cách truy xuất thông tin có liên quan từ các cơ sở dữ liệu bên ngoài lớn trong quá trình tạo. Sự tích hợp này cho phép mô hình truy cập và kết hợp kiến thức mới nhất và cụ thể theo miền, cải thiện độ chính xác và tính liên quan của nó. Kết hợp khả năng tạo của LLM với độ chính xác của hệ thống truy xuất tạo ra một mô hình lai mạnh mẽ có thể tạo ra các phản hồi chất lượng cao trong khi vẫn được thông báo từ các nguồn dữ liệu bên ngoài.
3. Meta-learning
Các phương pháp tiếp cận theo kiểu “meta-learning” cho phép LLM học cách học, giúp chúng thích nghi nhanh chóng với các nhiệm vụ và lĩnh vực mới với mức đào tạo tối thiểu.
Khái niệm về meta-learning phụ thuộc vào một số khái niệm chính như sau:
- Few-Shot Learning: theo đó LLM được đào tạo để hiểu và thực hiện các nhiệm vụ mới chỉ với một vài ví dụ, giúp giảm đáng kể lượng dữ liệu cần thiết để học hiệu quả. Điều này khiến họ có tính linh hoạt cao và hiệu quả trong việc xử lý các tình huống đa dạng.
- Self-Supervised Learning: LLM sử dụng lượng lớn dữ liệu không có nhãn để tạo nhãn và học các biểu diễn. Hình thức học này cho phép các mô hình tạo ra sự hiểu biết phong phú về cấu trúc ngôn ngữ và ngữ nghĩa, sau đó được tinh chỉnh cho các ứng dụng cụ thể.
- Reinforcement Learning: Trong phương pháp này, LLM học bằng cách tương tác với môi trường của họ và nhận phản hồi dưới dạng phần thưởng hoặc hình phạt. Điều này giúp các mô hình tối ưu hóa hành động của họ và cải thiện quy trình ra quyết định theo thời gian.
Kết luận
LLM là kỳ quan của công nghệ hiện đại. Chúng phức tạp về chức năng, quy mô lớn và mang tính đột phá về những tiến bộ. Trong bài viết này, chúng tôi đã khám phá tiềm năng tương lai của những tiến bộ phi thường này. Bắt đầu từ những ngày đầu trong thế giới trí tuệ nhân tạo, chúng tôi cũng đi sâu vào những đổi mới quan trọng như Neural Networks và Attention Mechanism.
Sau đó, chúng tôi đã xem xét nhiều chiến lược để nâng cao các mô hình này, bao gồm những tiến bộ về phần cứng, cải tiến các cơ chế bên trong và phát triển các kiến trúc mới. Đến giờ, chúng tôi hy vọng bạn đã hiểu rõ hơn và toàn diện hơn về LLM và quỹ đạo đầy hứa hẹn của chúng trong tương lai gần.
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- Từ “Sáng tạo” Đến “Hành động”: Khám phá sự khác biệt giữa Generative AI và Agentic AI
- 5 điều bạn cần biết về NVIDIA DGX Spark – Chiếc máy tính mơ ước của các nhà phát triển AI
- SLM và AI tại biên: Bình minh của một kỷ nguyên mới hay chỉ là cơn sốt nhất thời?