
Học máy được giám sát (supervised machine learning) là gì và nó liên quan như thế nào đến học không giám sát (unsupervised)?
Trong bài đăng này, bạn sẽ tìm hiểu các khái niệm “học có giám sát”, “học không giám sát” và “học máy có giám sát một phần”. Sau khi đọc bài này, bạn sẽ biết:
- Các vấn đề về phân loại và hồi quy trong học máy có giám sát.
- Các vấn đề phân nhóm và liên kết trong kiểu học không giám sát.
- Các ví dụ được sử dụng trong các học máy giám sát và không giám sát.
- Các vấn đề nằm giữa việc học có giám sát và không giám sát, được gọi là học giám sát một phần.
Học máy được giám sát (supervised machine learning)
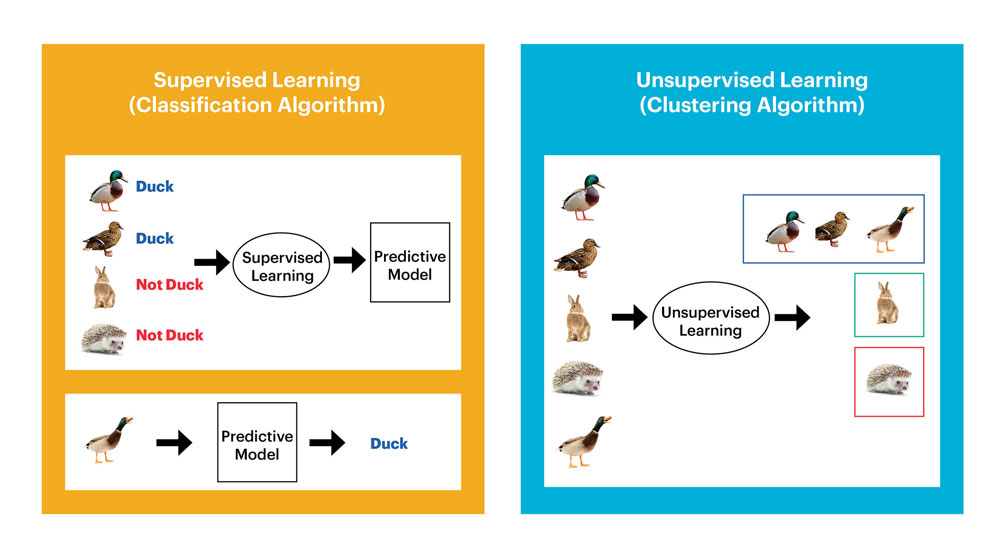
Phần lớn các ứng dụng học máy thực tế đều sử dụng học tập có giám sát – supervised learning.

Học tập có giám sát là nơi bạn có các biến đầu vào (X) và biến đầu ra (Y) và bạn sử dụng thuật toán để tìm hiểu hàm ánh xạ từ đầu vào đến đầu ra.
Y = f (X)
Mục đích là để xây dựng hàm ánh xạ một cách tốt nhất có thể để khi bạn có dữ liệu đầu vào mới (X) và bạn có thể dự đoán các biến đầu ra (Y) cho dữ liệu đó.
Nó được gọi là việc học có giám sát bởi vì quá trình của thuật toán học từ tập dữ liệu đầu vào có thể được coi là một “giáo viên” giám sát quá trình học tập. Chúng ta biết câu trả lời đúng, thuật toán sẽ lặp đi lặp lại làm cho việc dự đoán về dữ liệu đầu vào liên tục được “giáo viên” hoàn thiện. Việc học dừng lại khi thuật toán đạt được mức hiệu suất ở mức chấp nhận được.
Việc học tập có giám sát có thể được nhóm lại thành các vấn đề về phân loại và hồi quy.
Phân loại (Classification): Việc phân loại diễn ra khi biến đầu ra là một thể loại nào đó, chẳng hạn như “đỏ” hoặc “xanh” hoặc “bệnh” và “không có bệnh”.
Hồi quy (Regression): Việc hồi quy xảy ra là khi biến đầu ra là một giá trị thực, chẳng hạn như “đô la” hay “trọng lượng”.
Một số loại vấn đề phổ biến được xây dựng trên việc phân loại và hồi quy tương ứng với cơ chế gợi ý và dự đoán dãy thời gian.
Một số ví dụ phổ biến của thuật toán học máy được giám sát là:
Hồi quy tuyến tính cho các vấn đề hồi quy.
Nguyên lý “Khu rừng ngẫu nhiên” cho việc phân loại và hồi quy.
Hỗ trợ các hệ máy vector cho các vấn đề về phân loại.
Học máy không giám sát (unsupervised machine learning)
Học máy không giám sát là nơi bạn chỉ có dữ liệu đầu vào (X) và không có biến đầu ra tương ứng.
Mục tiêu của việc học không giám sát là để mô hình hóa cấu trúc nền tảng hoặc sự phân bố trong dữ liệu để hiểu rõ hơn về nó.
Đây được gọi là học tập không giám sát vì không giống như việc học có giám sát ở trên, không có câu trả lời đúng và không có vị “giáo viên” nào cả. Các thuật toán được tạo ra chỉ để khám phá và thể hiện các cấu trúc hữu ích bên trong dữ liệu.
Các vấn đề học tập không giám sát có thể được phân ra thành hai việc chia nhóm và kết hợp.
Chia nhóm: Vấn đề về chia nhóm là nơi bạn muốn khám phá các nhóm vốn có bên trong dữ liệu, chẳng hạn như phân nhóm khách hàng theo hành vi mua hàng.
Kết hợp: Vấn đề về học tập quy tắc kết hợp là nơi bạn muốn khám phá các quy tắc mô tả dữ liệu của bạn, chẳng hạn như những người mua X cũng có khuynh hướng mua Y.
Một số ví dụ phổ biến của thuật toán học không giám sát là:
- Xây dựng tham số “k-mean” cho vấn đề chia nhóm.
- Thuật toán Apriori cho các vấn đề liên quan đến việc học tập quy tắc.
Học máy giám sát một phần (Semi-supervised machine learning)
Khi bạn xây dựng mô hình trên một lượng lớn dữ liệu đầu vào (X) mà chỉ có một số dữ liệu được dán nhãn (Y) được gọi là việc học tập có giám sát một phần.
Nó nằm giữa việc học tập được giám sát và không giám sát.
Ví dụ điển hình là một kho lưu trữ hình ảnh, nơi chỉ một số ảnh được gắn nhãn, (ví dụ: chó, mèo, người) và phần lớn còn lại thì không được gắn nhãn.
Nhiều giải pháp học máy trong thực tế rơi vào trường hợp này. Điều này là do việc gắn nhãn dữ liệu có thể gây tốn kém hoặc tốn thời gian và có thể đòi hỏi phải tiếp cận được các chuyên gia trong lĩnh vực. Trong khi đó, dữ liệu không có nhãn rẻ hơn nhiều và dễ thu thập, lưu trữ.
Bạn có thể sử dụng các kỹ thuật học tập không giám sát để khám phá và tìm hiểu cấu trúc trong các dữ liệu đầu vào.
Bạn cũng có thể sử dụng kỹ thuật học có giám sát để đưa ra các phỏng đoán tốt nhất cho dữ liệu không được gắn nhãn, cung cấp ngược dữ liệu đó vào thuật toán học có giám sát dưới dạng dữ liệu đào tạo và sử dụng mô hình để đưa ra dự đoán về các dữ liệu đầu vào mới hoàn toàn khác.
Tóm tắt
Trong bài đăng này, bạn đã tìm hiểu sự khác biệt giữa việc học có giám sát, không giám sát và được giám sát một phần. Bây giờ bạn đã hiểu:
- Có giám sát: Tất cả dữ liệu được dán nhãn và các thuật toán tìm hiểu để dự đoán đầu ra từ dữ liệu đầu vào.
- Không được giám sát: Tất cả dữ liệu không được gắn nhãn và các thuật toán tìm hiểu cấu trúc vốn có từ dữ liệu đầu vào.
- Giám sát một phần: Một số dữ liệu được dán nhãn nhưng phần lớn dữ liệu còn lại không có nhãn và một hỗn hợp các kỹ thuật có giám sát và không giám sát có thể được sử dụng.
NTC Team lược dịch.
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- 5 điều bạn cần biết về NVIDIA DGX Spark – Chiếc máy tính mơ ước của các nhà phát triển AI
- SLM và AI tại biên: Bình minh của một kỷ nguyên mới hay chỉ là cơn sốt nhất thời?
- NVIDIA tại Computex 2025: “Gã khổng lồ xanh” đặt cược tất cả vào AI, GeForce liệu có bị ra rìa?