
Sẽ không hay sao nếu một chiếc máy tính có thể hiểu được tình cảm thực sự của con người đằng sau những văn bản châm biếm đôi khi thậm chí có thể thổi phồng con người thực tế?

Hoặc điều gì sẽ xảy ra nếu máy tính có thể hiểu ngôn ngữ của con người tốt đến mức nó có thể ước tính xác suất cho bạn biết khả năng gặp phải bất kỳ câu ngẫu nhiên nào mà bạn đưa ra?

Hoặc có lẽ nó có thể tạo ra các đoạn mã giả hoàn toàn của nhân Linux trông rất chân thực đến nỗi chúng cũng đáng sợ như mã nguồn thực tế (trừ khi bạn là một lập trình viên kernel)?
Điều gì sẽ xảy ra nếu máy tính có thể dịch tiếng Anh sang tiếng Pháp hoặc hơn 100 ngôn ngữ từ khắp nơi trên thế giới?
Hoặc xem một hình ảnh và mô tả các mục được tìm thấy trong ảnh?
Chà, nếu bạn đang tìm kiếm một chương trình máy tính tuyệt vời có thể làm những việc này trong thập kỷ trước, bạn sẽ không gặp may. Trong thực tế, đi đến năm 2012 hoặc trước đó, và bạn sẽ thấy rằng tất cả những điều này chỉ hiện diện trong khoa học viễn tưởng.
Nhưng nhanh chóng tiến đến ngày hôm nay, những điều này không chỉ có thể mà còn có trong cuộc sống hàng ngày của chúng ta. Các công ty truyền thông xã hội đang tích cực sử dụng phân tích tình cảm để xác định và hạn chế hành vi xấu / lời nói xấu trên nền tảng của họ, Google Translate có thể dịch giữa 100 ngôn ngữ và chatbot trong phần mềm trò chuyện dịch vụ khách hàng trực tiếp đang gia tăng.
Xử lý ngôn ngữ tự nhiên (NLP)
Tất cả các gạch đầu dòng trên đều thuộc lĩnh vực Xử lý ngôn ngữ tự nhiên (Natural Language Processing – NLP). Động lực chính đằng sau quá trình hiện thực hóa “lĩnh vực khoa học viễn tưởng” này là sự tiến bộ của các kỹ thuật Deep Learning, cụ thể là các kiến trúc Mạng thần kinh tái phát (Recurrent Neural Network – RNN) và Mạng thần kinh tích chập (Convolutional Neural Network – CNN).
Hãy xem xét một vài nhiệm vụ Xử lý Ngôn ngữ Tự nhiên và hiểu cách Deep Learning có thể giúp con người thực hiện chúng:
Mô hình hóa ngôn ngữ
Các mô hình ngôn ngữ nhằm đại diện cho lịch sử của văn bản được quan sát ngắn gọn để dự đoán từ tiếp theo. Nói một cách đơn giản, đó là nhiệm vụ dự đoán từ nào tiếp theo trong chuỗi.
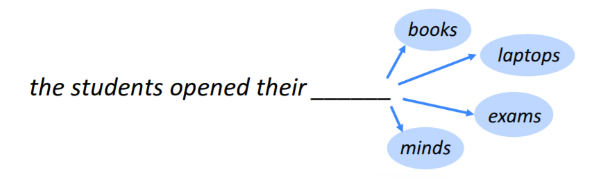
Nguồn: http://web.stanford.edu/group/cs224n/lectures/lecture8.pdf
Lưu ý rằng một mô hình ngôn ngữ cần sử dụng các từ mà nó đã gặp cho đến nay trong chuỗi, để đưa ra dự đoán. Các chuỗi từ mà mô hình có thể sử dụng trong thời gian dự đoán càng dài thì nó sẽ càng tốt hơn trong nhiệm vụ này.
Lấy ví dụ:
Nếu mô hình chỉ sử dụng 2 từ cuối cùng – thì họ đã mở ra – để đưa ra dự đoán, khả năng cho từ tiếp theo sẽ lớn hơn nhiều so với việc sử dụng 3 từ cuối cùng – học sinh đã mở ra họ. Do đó, dự đoán sẽ không chính xác trong trường hợp trước.
Vì vậy, một mô hình tốt sẽ ‘nhớ‘ những gì nó đã đọc cho đến hiện tại.
Và đây là điều mà RNN có ưu thế. Đặc biệt, các phiên bản nâng cao hơn được gọi là GRU (Đơn vị lặp lại có kiểm soát) và LSTM (Bộ nhớ ngắn hạn dài) cho kết quả khá đáng chú ý bằng cách tích hợp các đơn vị ‘bộ nhớ’.
Một tác dụng phụ thú vị của mô hình hóa ngôn ngữ là lấy một mô hình tổng quát mà chúng ta có thể sử dụng để tạo ra tất cả các loại trình tự.
Tạo ra các bài văn Shakespearean / mã nguồn Linux (!) / Nhạc Jazz (!!) / Các cấp độ của Super Mario (!!!)
Tất cả những bài đăng trên Twitter có nội dung như sau:
“Tôi đã tạo ra một AI đọc tất cả và sau đó làm cho nó viết giống như câu chuyện của chính nó. Đây là trang đầu tiên ..”
Tất cả đều có thể sử dụng RNNs!
Giả sử bạn muốn tạo ra một câu chuyện giống như Shakespeare. Những gì bạn sẽ làm là đào tạo một RNN trên bộ dữ liệu các câu chuyện Shakespeare hiện có và để nó học cách mô hình hóa nó. Bằng cách này, nó sẽ học cách dự đoán từ tiếp theo trong một câu chuyện của Shakespeare (chỉ cần rõ ràng, nó sẽ không chính xác 100% nhưng nó sẽ khá thỏa mãn). Những gì chúng ta có thể làm bây giờ là làm cho nó dự đoán từ có khả năng nhất trên và trên
Các từ tiếp tục được thêm vào cho đến khi chúng ta có được một kiệt tác mới của Shakespearean!
Còn gì nữa không
Bạn có thể mô hình hóa không chỉ văn bản, mà bất kỳ loại trình tự nào sử dụng các RNN tương tự. Ví dụ:
- Sử dụng mã nguồn được tìm thấy trong repo Linux trên Github để huấn luyện RNN và tạo nguồn Linux giả như các hàm!
- Huấn luyện một RNN về trình tự nhạc jazz và tạo nhạc jazz của riêng bạn mà không cần biết bất kỳ bản nhạc nào!
- Tiền xử lý các cấp độ Super Mario thành các file văn bản, huấn luyện mô hình trên chúng và tạo các cấp độ của riêng bạn, chưa từng thấy trước các cấp độ Super Mario!
Lưu ý rằng các ví dụ trên sử dụng RNN cấp độ ký tự. Ở đây, thay vì dự đoán từ tiếp theo trong chuỗi, mô hình dự đoán ký tự tiếp theo. Điều này cho phép RNN học các loại trình tự tùy ý như cấp độ Super Mario!
Phân tích tình cảm
Giao tiếp của con người không chỉ là lời nói và ý nghĩa. Nó phức tạp hơn nhiều vì nó liên quan đến cảm xúc. Lựa chọn từ ngữ, phong cách viết và cấu trúc câu đóng một phần rất lớn trong việc xác định tình cảm đằng sau một thông điệp bằng văn bản.

Nguồn: https://xkcd.com/1036/
Các cách tiếp cận trước đây để phân tích tình cảm được dựa trên việc token hóa các câu viết và cố gắng tìm ra tình cảm dựa trên các quy tắc ngữ pháp. Không cần phải nói, chúng không quá hiệu quả.
Nhưng ngày nay, các hệ thống phân tích dựa trên RNN đang được các công ty truyền thông xã hội khổng lồ triển khai để đánh dấu / gắn flag và xác định nội dung không phù hợp trên nền tảng của họ. Họ làm việc cùng với người điều hành con người và giúp họ loại bỏ nội dung độc hại.
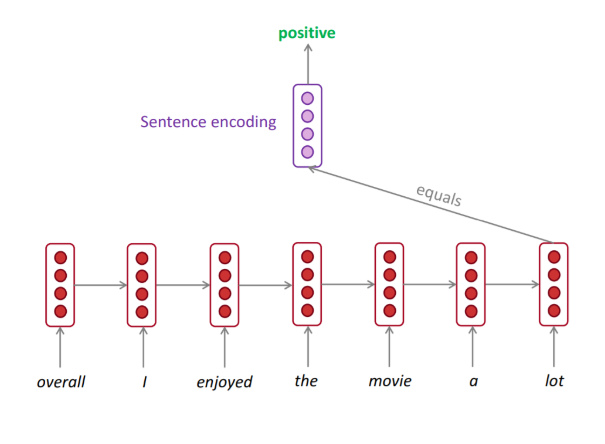
Nguồn: http://web.stanford.edu/group/cs224n/lectures/lecture8.pdf
Dịch ngôn ngữ
Trong 3 năm qua, công nghệ đằng sau dịch máy đã được viết lại hoàn toàn. Sử dụng một công nghệ được gọi là học theo trình tự, các lập trình viên giờ đây có thể xây dựng một số hệ thống dịch thuật tốt nhất trên thế giới.
Các kiến trúc theo trình tự này được dựa trên Mạng thần kinh tái phát – RNN.
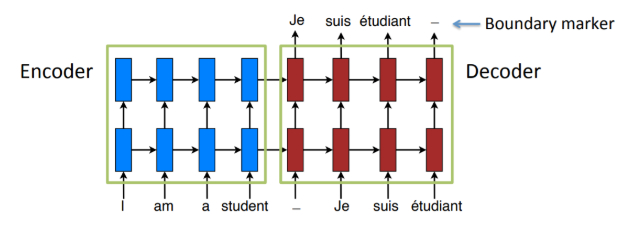
Nguồn: http://cs224d.stanford.edu/lectures/CS224d-Lecture15.pdf
Giả sử chúng ta muốn dịch giữa tiếng Anh và tiếng Pháp. Ở đây, một RNN (được gọi là bộ mã hóa) chịu trách nhiệm lấy câu tiếng Anh và chuyển đổi nó thành một vectơ đặc trưng mà RNN thứ hai (được gọi là bộ giải mã) lấy làm đầu vào và xuất bản dịch tiếng Pháp tương ứng.
Những kiến trúc theo trình tự này rất hữu ích không chỉ trong dịch thuật ngôn ngữ. Chúng cũng được sử dụng để xây dựng các chatbot AI! Ý tưởng ở đây khá đơn giản:
Thay vì đào tạo bộ mã hóa và giải mã trên 2 ngôn ngữ, chúng tôi đào tạo chúng ở 2 mặt của cuộc trò chuyện. Vì vậy, có thể bộ mã hóa sẽ đại diện cho các tin nhắn yêu cầu của người dùng trong khi bộ giải mã sẽ đại diện cho các tin nhắn tương ứng của Nhóm hỗ trợ. Vì vậy, hệ thống tìm hiểu cách dịch ra dịch giữa các yêu cầu của người dùng và câu trả lời của Nhóm hỗ trợ.
Sử dụng CNN cho các nhiệm vụ NLP
Theo truyền thống, chúng tôi nghĩ rằng một mạng tích chập (CNN) là một mạng thần kinh chuyên dùng để xử lý một lưới các giá trị như hình ảnh. Và mạng thần kinh tái phát (RNN) là mạng thần kinh chuyên dùng để xử lý một chuỗi các giá trị.
Nhưng gần đây, chúng tôi cũng đã bắt đầu áp dụng CNN cho các vấn đề trong Xử lý ngôn ngữ tự nhiên và nhận được một số kết quả thú vị.
Nhiệm vụ phân loại
Do CNN, không giống như RNN, chỉ có thể xuất ra các vectơ có kích thước cố định, sự phù hợp tự nhiên đối với chúng dường như nằm trong các nhiệm vụ phân loại như Phân tích tình cảm, Phát hiện thư rác hoặc Phân loại chủ đề.
Trong các tác vụ thị giác máy tính, các bộ lọc được sử dụng trong CNN trượt trên các bản vá của hình ảnh trong khi trong các tác vụ NLP, các bộ lọc trượt trên ma trận câu, một vài từ tại một thời điểm.
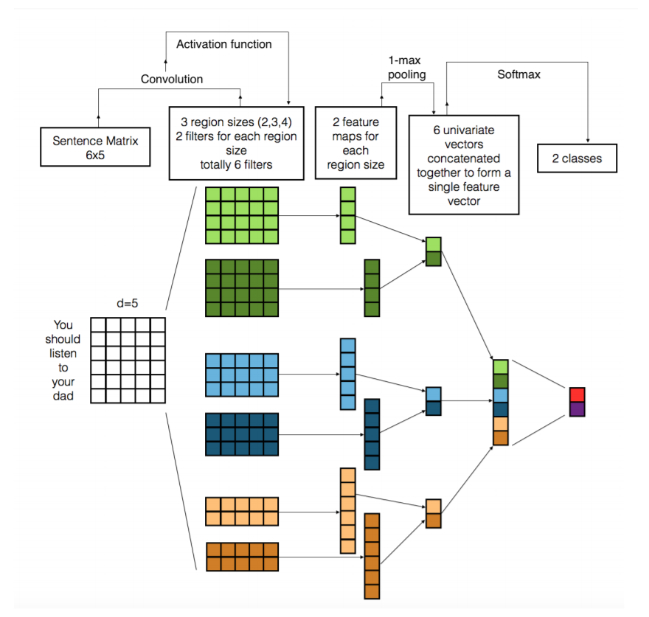
Lớp thứ nhất hiển thị 6 bộ lọc: 2 bộ lọc vượt qua 2 từ cùng một lúc, 2 bộ lọc khác vượt qua 3 từ cùng một lúc và 2 bộ lọc cuối cùng vượt qua 4 từ cùng một lúc.
Nguồn: https://arxiv.org/pdf/1703.03091.pdf
Các bộ lọc đã học của lớp đầu tiên, các tính năng chụp khá giống với n-gram nhưng được thể hiện theo cách nhỏ gọn hơn.
Một lập luận lớn cho CNN là chúng rất nhanh. Convolutions là một phần trung tâm của đồ họa máy tính và được triển khai ở cấp độ phần cứng trên GPU.
Tạo mô tả hình ảnh
Hãy nhớ làm thế nào trong các mô hình tuần tự, trình mã hóa tạo ra một biểu diễn vectơ của dữ liệu đầu vào và bộ giải mã lấy vectơ đó để tạo ra một chuỗi mới?
Bây giờ, nếu chúng ta thay thế RNN trong bộ mã hóa đó bằng CNN thì sao?
Điều này sẽ cho chúng ta một mô hình có thể lấy một hình ảnh và tạo ra một chuỗi dựa trên hình ảnh đó!
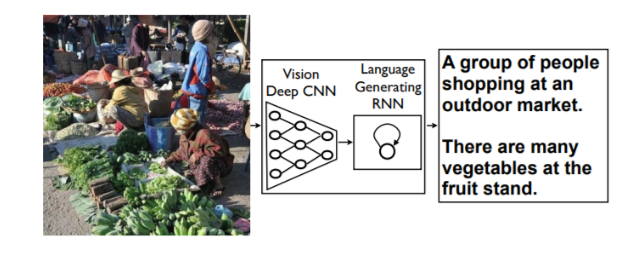
Sau đó chúng ta có thể truyền một hình ảnh cho mô hình của mình và để nó xuất ra một câu mô tả hình ảnh đó.
Tự động mô tả nội dung của hình ảnh là một vấn đề cơ bản trong trí tuệ nhân tạo kết nối thị giác máy tính và xử lý ngôn ngữ tự nhiên. Có thể tự động mô tả nội dung của một hình ảnh bằng cách sử dụng các câu tiếng Anh được tạo đúng là một nhiệm vụ rất khó khăn, nhưng nó có thể có tác động lớn. Chẳng hạn, nó có thể giúp những người khiếm thị hiểu rõ hơn nội dung của hình ảnh trên web.

Đây là hai giấy tờ quan trọng giải quyết vấn đề này:
- Hiển thị và cho biết: Trình tạo chú thích ảnh thần kinh của một nhóm Google
- Sự sắp xếp ngữ nghĩa trực quan sâu sắc để tạo mô tả hình ảnh của Andrej Karpathy và Li Fei-Fei
Tất cả những tiến bộ mà chúng ta đã nói trong bài viết này là chỉ mới xuất hiện gần đây. Không có cái nào trong số này là hiện hữu trong khoảng 6 năm trước. Điều này cho thấy lĩnh vực Deep Learning đang tăng tốc nhanh như thế nào.
Đây chắc chắn là một thời điểm thú vị để tham gia vào lĩnh vực này. Vì vậy, hãy bắt tay vào hành động ngay bây giờ và hãy đào tạo một số mạng lưới thần kinh của riêng bạn!
Nguồn Tổng hợp
Bài viết liên quan
- Huấn luyện mô hình hàng trăm tỷ tham số ngay tại bàn với MSI EdgeXpert
- NVIDIA Merlin: Tổng quan về toolkit cho hệ thống gợi ý quy mô lớn
- OpenAI lần đầu phát hành miễn phí mô hình ngôn ngữ mới với tên gọi là GPT-OSS
- Hướng dẫn lựa chọn GPU phù hợp cho AI, Machine Learning
- 5 điều bạn cần biết về NVIDIA DGX Spark – Chiếc máy tính mơ ước của các nhà phát triển AI
- SLM và AI tại biên: Bình minh của một kỷ nguyên mới hay chỉ là cơn sốt nhất thời?