Biến khối lượng dữ liệu ngày càng gia tăng thành thông tin nắm bắt về doanh nghiệp với nền tảng phù hợp cho học máy (Machine Learning). Tìm hiểu thêm về các nhà cung cấp và các sản phẩm trong thị trường tiên tiến này.
Các công ty muốn có lợi thế cạnh tranh và tìm kiếm các nền tảng cho Machine Learning cung cấp phương tiện để dự đoán kết quả từ khối lượng dữ liệu ngày càng tăng. Bảng tổng hợp các nền tảng Machine Learning này chưa phải là đầy đủ nhất nhưng sẽ làm nổi bật các nhà cung cấp và sản phẩm hiện đang dẫn đầu thị trường.
1. Alteryx Promote
API Alteryx Promote cho phép các nhà khoa học dữ liệu triển khai các mô hình dự đoán vào các hệ thống kinh doanh và sau đó quản lý hiệu suất mô hình.
Alteryx tuyên bố nền tảng máy học của họ giúp các chuyên gia dữ liệu giải quyết các vấn đề kinh doanh phức tạp nhanh hơn bằng cách dễ dàng triển khai các mô hình phân tích nâng cao vào môi trường sản phẩm.
Alteryx Promotion mở rộng khả năng phân tích của Alteryx Analytics Platform như một hệ thống end-to-end cho các nhóm khoa học dữ liệu để triển khai và cập nhật các mô hình dự đoán miễn phí từ CNTT. Khi xử lý các ứng dụng chạy thực tế có khả năng sử dụng các yêu cầu API REST, nền tảng sẽ nhúng các mô hình dự đoán và học máy mà không cần mã hóa. Nó cũng quản lý các mô hình cả tại chỗ và trên đám mây, với các tùy chọn có thể mở rộng.
Bằng cách phát triển các mô hình trong “môi trường thân thiện với mã Alteryx” và triển khai lên một đám mây an toàn, các công ty có thể giảm thời gian triển khai mô hình xuống còn vài phút, công ty nói. Quá trình tạo ra API kết quả dưới dạng một dòng mã duy nhất mà các nhóm có thể dễ dàng kết hợp vào các trang web HTML.
 Nhiều Quy trình của nền tảng học máy Alteryx, bao gồm quảng cáo, tổ chức và bảng tính dữ liệu
Nhiều Quy trình của nền tảng học máy Alteryx, bao gồm quảng cáo, tổ chức và bảng tính dữ liệu
2. Amazon SageMaker
SageMaker là một thành phần chính trong việc cung cấp máy học của Amazon , thông qua đám mây công cộng AWS của nó.
Đó là một dịch vụ được quản lý hoàn toàn, được xây dựng cho các nhà phát triển phần mềm và nhà khoa học dữ liệu để tạo, đào tạo và triển khai các mô hình học máy. Dịch vụ dựa trên đám mây bao gồm các mô-đun mà các tổ chức có thể sử dụng cùng nhau hoặc riêng biệt.
Sổ ghi chép Jupyter được lưu trữ là một thành phần và những sổ ghi chép này cho phép người dùng khám phá và trực quan hóa dữ liệu đào tạo được lưu trữ trong Amazon Simple Storage Service (S3), một dịch vụ AWS cung cấp lưu trữ đối tượng thông qua giao diện dịch vụ web. Máy tính xách tay có thể kết nối trực tiếp với dữ liệu trong Amazon S3 hoặc sử dụng AWS Glue để di chuyển dữ liệu từ Amazon Relational Database Service, Amazon DynamoDB và Amazon Redshift vào S3 để phân tích.
Amazon chào mời SageMaker như một phương tiện để tạo, triển khai và đào tạo các mô hình một cách dễ dàng và nhanh chóng, và cuối cùng, SageMaker bao gồm 12 thuật toán học máy phổ biến được cài đặt sẵn. Dịch vụ này cũng được cấu hình sẵn để chạy TensorFlow và Apache MXNet. Khách hàng cũng có thể sử dụng các khuôn khổ của riêng họ.
3. Domino
Nền tảng Domino dành cho học máy là mở và thống nhất, được thiết kế để đẩy nhanh quá trình nghiên cứu và cộng tác, tăng tốc độ lặp lại và loại bỏ khó khăn khi triển khai. Domino tuyên bố nó cung cấp một nền tảng đầy đủ chức năng bằng cách cho phép người dùng xây dựng, xác nhận và cung cấp các mô hình trên quy mô lớn.
Doanh nghiệp có thể sử dụng nền tảng này để khám phá, chia sẻ và tái sử dụng các nguồn dữ liệu, bao gồm cơ sở dữ liệu đám mây và hệ thống phân tán, chẳng hạn như Hadoop và Spark. Họ cũng có thể chạy khối lượng công việc phát triển và sản xuất trong các vùng chứa Docker có thể định cấu hình để tạo môi trường chia sẻ và có thể tái sử dụng cũng như sử dụng máy tính có thể mở rộng được Kubernetes hỗ trợ trong cả tài nguyên quy mô dọc và ngang. Sau đó có sẵn trên đám mây hoặc tại chỗ. Nền tảng này cũng có thể sử dụng các kỹ thuật học sâu với quyền truy cập vào phần cứng GPU.
Nền tảng Domino cho phép người dùng tạo không gian làm việc tương tác bằng bất kỳ công cụ dựa trên web nào, chẳng hạn như Jupyter, RStudio, SAS, H2O và Zeppelin. Nó chạy nhiều công việc đào tạo và điều chỉnh đồng thời, đồng thời theo dõi các chỉ số mô hình chính và so sánh kết quả song song với nhau.
Nó cũng có thể tự động lưu giữ ngữ cảnh của thử nghiệm. Mỗi khi người dùng chạy thử nghiệm, nền tảng máy học này sẽ nắm bắt toàn bộ tập hợp phụ thuộc của mô hình – dữ liệu, mã, gói / công cụ, tham số và kết quả – và thảo luận về kết quả của thử nghiệm, Domino nói. Hệ thống cung cấp các mô hình dưới dạng lô cấp doanh nghiệp hoặc API thời gian thực để tích hợp vào các hệ thống hạ nguồn.
Vào đầu năm 2020, Domino đã phát hành Domino Model Monitor của họ, theo dõi độ lệch và độ không chính xác của mô hình trong thời gian thực để ngăn chặn sự xuống cấp của mô hình.
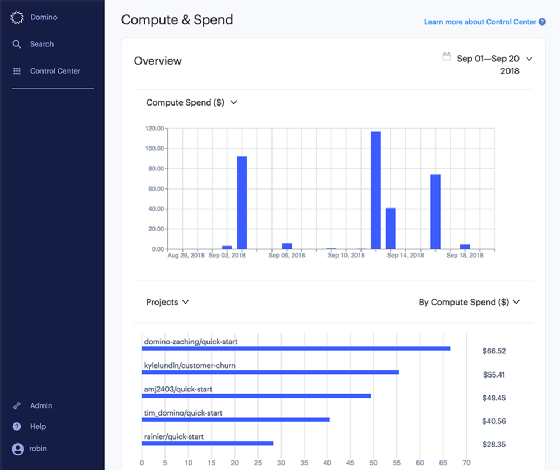
Biểu đồ thanh Domino ghi lại các giới hạn chi tiêu khác nhau, tùy thuộc vào năm và tháng
4. Google Cloud Machine Learning Engine
Google cung cấp Công cụ học máy trên đám mây (ML Engine) dưới dạng dịch vụ được quản lý cho phép các nhà khoa học dữ liệu phát triển và kích hoạt thời gian thực. Nó cung cấp các dịch vụ đào tạo và dự đoán mà các nhà khoa học dữ liệu có thể sử dụng cùng nhau hoặc riêng lẻ.
Cloud Machine Learning Engine kết hợp cơ sở hạ tầng được quản lý của Google Cloud Platform (GCP) với TensorFlow, một thư viện phần mềm mã nguồn mở để lập trình luồng dữ liệu trong nhiều nhiệm vụ khác nhau. Doanh nghiệp có thể sử dụng dịch vụ để đào tạo mô hình máy học trên quy mô lớn bằng cách chạy các ứng dụng đào tạo TensorFlow trên đám mây. Họ cũng có thể lưu trữ các mô hình được đào tạo trên đám mây và sau đó sử dụng chúng để đưa ra dự đoán về dữ liệu mới.
Dịch vụ của Google quản lý các tài nguyên máy tính mà một công ty cần để thực hiện công việc đào tạo, do đó, công ty có thể tập trung nhiều hơn vào mô hình của mình hơn là vào cấu hình phần cứng hoặc quản lý tài nguyên.
Cloud ML Engine có một số thành phần chính – một trong số đó là API REST, lõi Engine là một tập hợp các dịch vụ RESTful để quản lý công việc, mô hình và phiên bản, cũng như đưa ra dự đoán về các mô hình được lưu trữ trên GCP. Một thành phần khác là công cụ dòng lệnh gcloud, quản lý các mô hình, cũng như các dự đoán về phiên bản và yêu cầu. Một yếu tố khác, Google Cloud Console, cung cấp tính năng quản lý mô hình và phiên bản cũng như giao diện đồ họa để làm việc với các tài nguyên máy học .
5. H2O.ai
H2O là một nền tảng phân tán, trong bộ nhớ, mã nguồn mở cho máy học cho phép các tổ chức xây dựng mô hình máy học trên dữ liệu lớn.
H2O Flow sử dụng sổ ghi chép tương tác, có khả năng mở rộng tuyến tính và hỗ trợ các thuật toán thống kê và học máy phổ biến, bao gồm máy tăng độ dốc (GBM), mô hình tuyến tính tổng quát (GLM) và học sâu, bao gồm cả mạng thần kinh sâu.
H2O có chức năng AutoML tự động chạy qua các thuật toán và siêu tham số của chúng để tạo ra một bảng xếp hạng các mô hình tốt nhất.
Các tính năng chính khác bao gồm các thủ tục được phát triển cho tính toán phân tán. Các thuật toán dành cho cả phương pháp tiếp cận có giám sát và không được giám sát, bao gồm rừng ngẫu nhiên, GLM, GBM, XGBoost, mô hình xếp hạng thấp tổng quát, Word2vec và hơn thế nữa.
H2O hoạt động trên cơ sở hạ tầng dữ liệu lớn hiện có, trên kim loại trần hoặc trên các cụm Hadoop hoặc Spark hiện có. Phần mềm có thể nhập dữ liệu trực tiếp từ Hệ thống tệp phân tán Hadoop, Spark, S3, Azure Data Lake hoặc nguồn thông tin khác. Các trường hợp sử dụng bao gồm phân tích nâng cao, phát hiện gian lận, quản lý xác nhận quyền sở hữu và quảng cáo kỹ thuật số.

Bảng điều khiển nền tảng máy học H20.ai, liên tục theo dõi dữ liệu và các thay đổi của công ty để giúp CNTT hợp lý hóa việc quản lý dự án
6. IBM Watson Studio và IBM Watson Machine Learning
IBM Watson Studio và IBM Watson Machine Learning tạo ra một nền tảng khoa học dữ liệu doanh nghiệp cho máy học, cung cấp cho các nhóm các công cụ khoa học dữ liệu và mã nguồn mở. IBM chào mời họ là cung cấp sự linh hoạt để xây dựng và triển khai ở bất kỳ đâu trong môi trường đa đám mây và khả năng vận hành các kết quả kỹ thuật dữ liệu nhanh hơn.
Watson Studio cho phép các nhà khoa học dữ liệu và kỹ sư khám phá dữ liệu và phát triển các mô hình. Nền tảng này cho phép người dùng truy cập các công cụ khoa học dữ liệu để chuẩn bị dữ liệu và phát triển mô hình, đồng thời có sẵn cho cả người viết mã và người không mã hóa. Bằng cách sử dụng môi trường đa đám mây, IBM Watson Studio cung cấp phân tích dữ liệu tại chỗ, trong IBM Cloud Private hoặc trong đám mây công cộng.
Với IBM Watson Machine Learning, các mô hình được xây dựng trong IBM Watson Studio sẵn sàng sản xuất, được xây dựng để triển khai, đánh giá và quản lý trong một môi trường an toàn. Điều này cho phép người dùng đưa khoa học dữ liệu vào sản xuất nhanh hơn, IBM tuyên bố.
7. IBM Machine Learning cho z / OS
IBM Machine Learning cho z / OS là một hệ thống học máy được thiết kế để trích xuất giá trị ẩn từ dữ liệu doanh nghiệp. Nó có thể giúp các tổ chức nhanh chóng nhập và chuyển đổi dữ liệu để tạo, tổ chức và quản lý các mô hình hành vi tự học bằng cách sử dụng dữ liệu hệ thống Z của IBM. IBM tuyên bố rằng điều này sẽ cho phép các công ty dự đoán chính xác hơn nhu cầu của khách hàng và doanh nghiệp.
Các nhà phát triển dữ liệu và nhà khoa học có thể xây dựng và đào tạo các mô hình với IBM Watson Studio hoặc các môi trường phát triển mô hình khác và có khả năng triển khai các mô hình đó gần với các giao dịch cốt lõi bắt nguồn từ IBM Z.
Người dùng có thể triển khai các mô hình ngay lập tức trong khuôn khổ của IBM và các API RESTful cho phép các nhà phát triển ứng dụng kết hợp các mô hình hành vi vào mã của họ. Trang tổng quan cung cấp kiểm tra tình trạng trên tất cả các mô hình trong doanh nghiệp, cung cấp thông tin chi tiết về hiệu suất mô hình tổng thể và xem nhanh những mô hình cần được đào tạo lại.
Độ chính xác của mô hình cho phép các nhà khoa học dữ liệu và kỹ sư lên lịch đánh giá lại liên tục trên dữ liệu mới.
8. Trình mô hình SPSS của IBM
IBM SPSS Modeler cung cấp tính năng khai thác dữ liệu và phân tích văn bản cho người dùng có ít hoặc không có kỹ năng lập trình. SPSS Modeler có thể đọc dữ liệu từ các tệp phẳng, bảng tính, cơ sở dữ liệu quan hệ chính, IBM Planning Analytics và Hadoop.
Theo IBM, người dùng có thể mở rộng khả năng của SPSS Modeler để đẩy lùi quá trình xử lý dữ liệu với tiện ích bổ sung Tối ưu hóa SQL (đăng ký) hoặc Máy chủ phân tích (giấy phép vĩnh viễn). Sản phẩm cung cấp giao diện đồ họa để giúp trực quan hóa từng bước trong quy trình khai thác dữ liệu như một phần của luồng và tự động chuyển đổi dữ liệu sang định dạng tốt nhất để tạo mô hình dự đoán chính xác.
Ngoài ra, SPSS Modeler có thể kiểm tra nhiều phương pháp mô hình hóa, so sánh kết quả và chọn mô hình nào để triển khai trong một lần chạy. Quá trình này thông báo cho người dùng về thuật toán hoạt động tốt nhất dựa trên hiệu suất của mô hình. Ngoài ra, SPSS Modeler cung cấp nhiều kỹ thuật học máy và hỗ trợ cây quyết định, mạng nơ-ron và mô hình hồi quy.
9. IBM Watson Explorer
IBM Watson Explorer là một nền tảng phân tích nội dung và khám phá nhận thức cho phép người dùng khám phá và phân tích nội dung có cấu trúc, phi cấu trúc, nội bộ, bên ngoài và công khai để phát hiện ra các xu hướng và mẫu. Ví dụ, các tổ chức đã sử dụng Watson Explorer để hiểu các cuộc gọi đến và email thông qua khả năng nhận thức được tích hợp sẵn của Watson, mô hình học máy, xử lý ngôn ngữ tự nhiên (NLP) và API. Cuối cùng, Watson cho phép các tổ chức có được cái nhìn tốt hơn về khách hàng.
IBM Watson Explorer sử dụng máy học, khai thác dữ liệu nhận thức và phân tích văn bản phong phú. Công nghệ này cũng sử dụng lập chỉ mục và tìm kiếm; điều này cho phép người dùng khám phá, tổng hợp, phân tích và trực quan hóa khối lượng lớn dữ liệu có cấu trúc và phi cấu trúc.
10. Nền tảng phân tích KNIME
KNIME Analytics Platform là phần mềm mã nguồn mở để tạo các ứng dụng và dịch vụ khoa học dữ liệu, nhằm mục đích trở nên trực quan và cởi mở, đồng thời liên tục tích hợp các phát triển mới. Theo các nhà phát triển của nó, mục tiêu cuối cùng của KNIME là làm cho việc hiểu dữ liệu và thiết kế quy trình làm việc khoa học dữ liệu và các thành phần có thể sử dụng lại được cho tất cả mọi người.
Các chuyên gia dữ liệu có thể sử dụng nền tảng này để tạo quy trình làm việc trực quan với giao diện đồ họa kéo và thả mà không cần mã hóa.
Người dùng có thể chọn từ hơn 2.000 mô-đun hoặc nút để xây dựng quy trình công việc, lập mô hình từng bước của phân tích, kiểm soát luồng dữ liệu và đảm bảo rằng công việc luôn cập nhật. Họ có thể chọn một trong hàng trăm quy trình công việc mẫu có sẵn công khai hoặc sử dụng một huấn luyện viên quy trình làm việc tích hợp để hướng dẫn họ.
Sử dụng nền tảng KNIME cho học máy, các nhà phân tích dữ liệu có thể lấy thống kê – bao gồm giá trị trung bình, lượng tử và độ lệch chuẩn – hoặc áp dụng các thử nghiệm thống kê để xác thực giả thuyết. Họ có thể xây dựng các mô hình học máy để phân loại, hồi quy, giảm thứ nguyên hoặc phân cụm bằng các thuật toán nâng cao. Điều này cũng bao gồm học sâu, phương pháp dựa trên cây và hồi quy logistic .
11. Microsoft Azure Machine Learning Studio
Microsoft Azure Machine Learning Studio là một công cụ cộng tác, kéo và thả mà các nhóm dữ liệu có thể sử dụng để xây dựng, kiểm tra và triển khai các phân tích dự đoán trên dữ liệu. Machine Learning Studio xuất bản các mô hình dưới dạng ứng dụng dịch vụ web hoặc công cụ thông minh dành cho doanh nghiệp, chẳng hạn như Excel, Microsoft chào hàng.
Sản phẩm cung cấp một không gian làm việc trực quan, tương tác, nơi người dùng có thể kéo và thả các tập dữ liệu và mô-đun phân tích vào một canvas tương tác, kết nối chúng với nhau để tạo thành một thử nghiệm. Sau đó, điều này sẽ chạy trong Machine Learning Studio.
Khi người dùng xây dựng thử nghiệm, họ có thể chọn từ danh sách các mô-đun có các tham số tiềm năng để định cấu hình các thuật toán bên trong của mô-đun. Khi người dùng chọn một mô-đun trên canvas, công cụ sẽ hiển thị các thông số của mô-đun trong ngăn thuộc tính và người dùng có thể sửa đổi các giới hạn trong ngăn đó để điều chỉnh mô hình.
Để lặp lại thiết kế mô hình, người dùng có thể chỉnh sửa thử nghiệm, lưu bản sao nếu cần và chạy lại thử nghiệm. Sau đó, họ có thể xuất bản thử nghiệm đào tạo dưới dạng dịch vụ web để những người khác có thể truy cập mô hình và sau đó chuyển đổi nó thành một thử nghiệm dự đoán. Microsoft tuyên bố không cần lập trình, chỉ cần kết nối trực quan các tập dữ liệu và mô-đun để xây dựng mô hình phân tích dự đoán.
Phần thưởng: Microsoft Azure Computer Vision cung cấp cho các nhà khoa học dữ liệu khả năng chạy các thuật toán phân loại và xử lý hình ảnh để phát hiện, phân loại hình ảnh, v.v.
12. Dịch vụ Máy chủ Microsoft SQL Server
Theo Microsoft, SQL Server Machine Learning Services là một công cụ phân tích dự đoán và khoa học dữ liệu được nhúng. Nó có thể thực thi mã R và Python trong cơ sở dữ liệu SQL Server dưới dạng các thủ tục được lưu trữ, tập lệnh Transact-SQL chứa câu lệnh R hoặc Python hoặc mã R hoặc Python chứa T-SQL.
Một trong những đề xuất giá trị quan trọng của Dịch vụ Học máy là khả năng của các gói độc quyền của nó để cung cấp các phân tích nâng cao trên quy mô lớn và khả năng đưa các phép tính và xử lý đến nơi chứa dữ liệu. Công ty cho biết làm như vậy loại bỏ nhu cầu kéo dữ liệu trên toàn mạng.
Có hai tùy chọn để sử dụng khả năng học máy trong SQL Server . Một là SQL Server Machine Learning Services (In-Database), hoạt động trong phiên bản máy cơ sở dữ liệu và tích hợp đầy đủ công cụ tính toán với công cụ cơ sở dữ liệu.
Loại còn lại là Máy chủ Học máy SQL Server (Độc lập), một Máy chủ Học máy dành cho Windows chạy độc lập với công cụ cơ sở dữ liệu. Mặc dù nó sử dụng thiết lập SQL Server để cài đặt máy chủ, tính năng này không nhận biết được phiên bản. Về mặt chức năng, nó tương đương với Máy chủ Microsoft Machine Learning không phải SQL Server dành cho Windows.
Hỗ trợ cho R và Python thông qua các gói Microsoft độc quyền được sử dụng để tạo và đào tạo các mô hình, cho điểm dữ liệu và xử lý song song bằng cách sử dụng các tài nguyên hệ thống cơ bản.
13. RapidMiner
RapidMiner là một nền tảng phần mềm dành cho học máy, được xây dựng cho các nhóm phân tích và nó hợp nhất việc chuẩn bị dữ liệu, học máy và triển khai mô hình dự đoán. Các tổ chức có thể xây dựng các mô hình học máy và đưa chúng vào sản xuất bằng cách sử dụng trình thiết kế quy trình làm việc trực quan và khả năng lập mô hình tự động của RapidMiner.
RapidMiner hỗ trợ nhiều trường hợp sử dụng khác nhau , bao gồm thông minh khách hàng, tối ưu hóa chuỗi cung ứng, cải thiện kết quả chăm sóc sức khỏe, bảo trì dự đoán, an ninh mạng và phát hiện gian lận.
RapidMiner Auto Model tăng tốc độ chuẩn bị dữ liệu bằng cách phân tích dữ liệu để xác định các vấn đề chất lượng dữ liệu phổ biến . Nó tự động hóa mô hình dự đoán bằng cách đề xuất các kỹ thuật học máy tốt nhất và sau đó tạo ra các mô hình dự đoán được xác nhận chéo, được tối ưu hóa. Sau đó, RapidMiner nêu bật những tính năng nào có tác động lớn nhất đến mục tiêu kinh doanh mong muốn.
Hình ảnh trực quan tích hợp và trình mô phỏng mô hình tương tác cho phép các nhà khoa học dữ liệu nhanh chóng khám phá một nguyên mẫu để đánh giá hiệu suất trong nhiều điều kiện khác nhau.
RapidMiner đã chuyển đổi máy chủ trước đó thành trung tâm RapidMiner AI, một máy chủ cộng tác mã nguồn mở để tăng cường tính toán, kết nối các nhóm khoa học dữ liệu và giúp tự động hóa các quy trình quyết định.
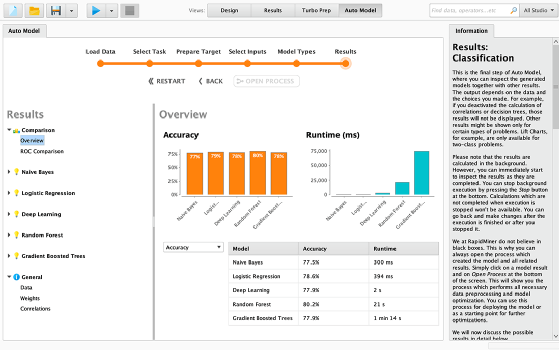 Đồ thị RapidMiner tính toán độ chính xác và thời gian chạy ứng dụng, cũng như hướng dẫn sử dụng phần mềm
Đồ thị RapidMiner tính toán độ chính xác và thời gian chạy ứng dụng, cũng như hướng dẫn sử dụng phần mềm
14. Khai thác dữ liệu trực quan và học máy của SAS
Khai thác dữ liệu trực quan và Học máy từ SAS hỗ trợ các quy trình khai thác dữ liệu đầu cuối và học máy. Với giao diện trực quan và lập trình xử lý tất cả các tác vụ chính của vòng đời phân tích, nền tảng dành cho học máy này cho phép nhiều người dùng đồng thời phân tích bất kỳ lượng dữ liệu có cấu trúc và phi cấu trúc nào bằng giao diện trực quan.
Sản phẩm cung cấp khả năng mở rộng, xử lý phân tích trong bộ nhớ, cho phép truy cập đồng thời vào dữ liệu trong một môi trường an toàn, đa người dùng, theo SAS. Dữ liệu và các hoạt động phân tích khối lượng công việc được phân phối song song trên các nút và được đa luồng trên mỗi nút để có tốc độ nhanh.
Giao diện kéo và thả cho phép các kỹ sư dữ liệu nhanh chóng bổ sung và tích hợp dữ liệu trong một “đường dẫn hoạt động trực quan”. Tất cả các hành động được thực hiện trong bộ nhớ để duy trì tính nhất quán của cấu trúc dữ liệu. Hệ thống cho phép người dùng khám phá tất cả dữ liệu văn bản để có được những hiểu biết mới về các chủ đề và kết nối không xác định, đồng thời cung cấp quyền truy cập vào một loạt các thuật toán thống kê, học máy, học sâu và phân tích văn bản trong một môi trường duy nhất.
Khả năng phân tích bao gồm phân cụm, các hương vị khác nhau của hồi quy, rừng ngẫu nhiên, GBM, máy vectơ hỗ trợ, NLP và phát hiện chủ đề. Các nhà phân tích có thể kiểm tra các phương pháp đào tạo mô hình khác nhau trong một lần chạy và so sánh kết quả của nhiều thuật toán học có giám sát với các bài kiểm tra tiêu chuẩn hóa để xác định các mô hình hàng đầu.
Khai thác dữ liệu trực quan và Máy học cũng cho phép người dùng nhúng mã nguồn mở vào phân tích và gọi các thuật toán nguồn mở một cách liền mạch trong luồng Model Studio. Công ty cho biết điều này tạo điều kiện cho sự cộng tác trong một tổ chức vì người dùng có thể lập trình bằng ngôn ngữ lập trình mà họ lựa chọn.