
Trên toàn cầu, các doanh nghiệp đang dần nhận ra những lợi ích của các mô hình Generative AI (GenAI). Họ đang chạy đua để áp dụng những mô hình này vào nhiều ứng dụng khác nhau, chẳng hạn như chatbot, trợ lý ảo hay các coding copilot,…
Mặc dù các mô hình có mục đích chung (general-purpose) hoạt động tốt cho các nhiệm vụ đơn giản nhưng chúng kém hơn khi đáp ứng nhu cầu riêng biệt của các ngành khác nhau. Các mô hình GenAI tùy chỉnh hoạt động tốt hơn các mô hình chung và đáp ứng yêu cầu của doanh nghiệp bằng cách kết hợp kiến thức chuyên ngành, hiểu các sắc thái văn hóa địa phương và phù hợp với tiếng nói và giá trị thương hiệu.
Nhóm NVIDIA NeMo đang công bố chương trình truy cập sớm dành cho các microservice NVIDIA NeMo Curator, NVIDIA NeMo Customizer và NVIDIA NeMo Evaluator. Bao gồm tất cả các giai đoạn phát triển từ quản lý và tùy chỉnh dữ liệu cho đến đánh giá, những microservice này đơn giản hóa quy trình để người dùng xây dựng các mô hình GenAI tùy chỉnh.
NVIDIA NeMo là một nền tảng toàn diện dành cho phát triển GenAI tùy chỉnh ở mọi nơi. Nó bao gồm các công cụ để đào tạo, tinh chỉnh, quản lý dữ liệu, RAG, guardrail và các mô hình được đào tạo trước (pretrained models). Ngoài ra còn có các dịch vụ trên nhiều nền tảng công nghệ, từ framework đến các endpoint API cấp độ cao (Hình 1).
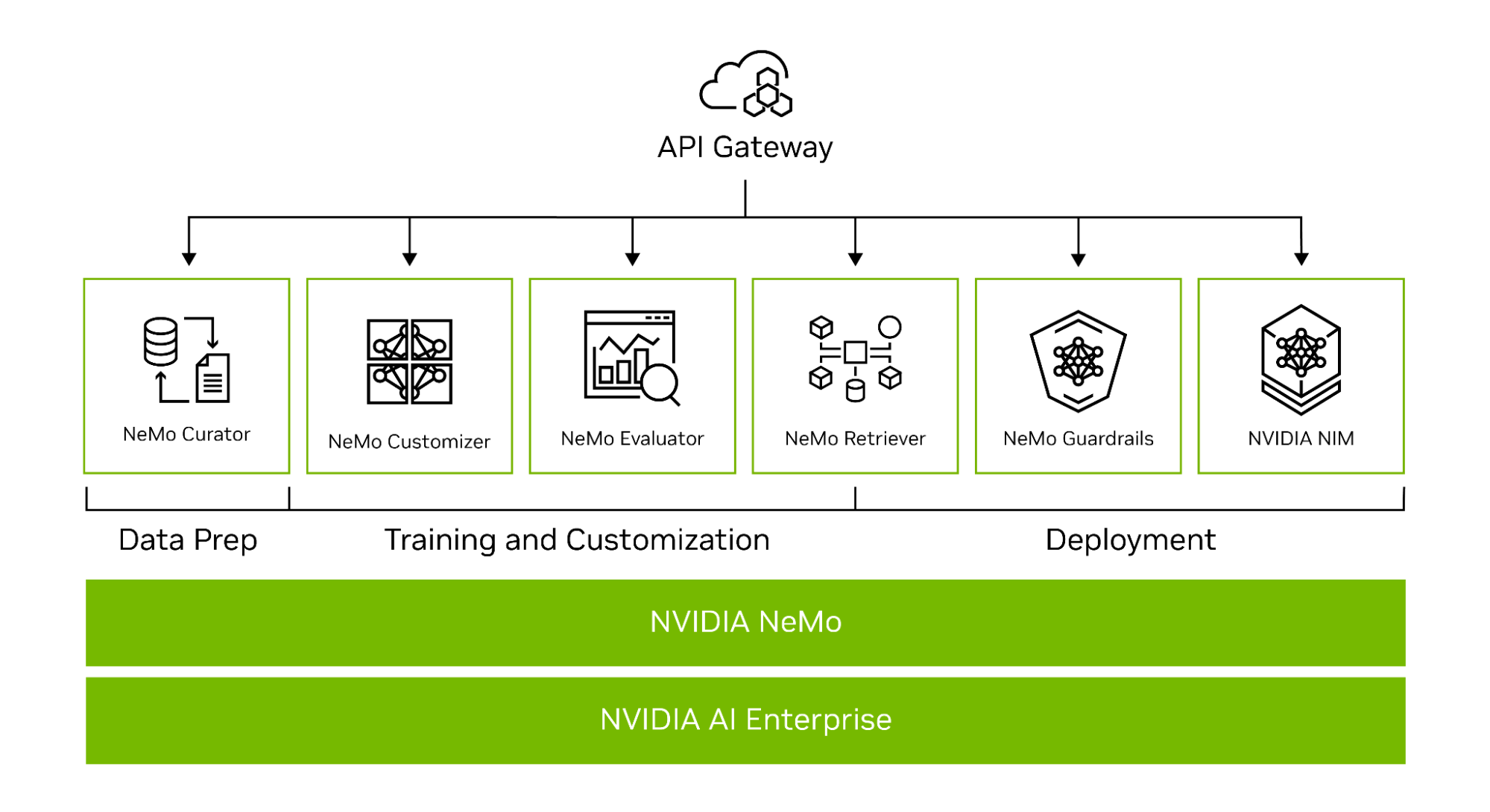 Hình 1. Các dịch vụ nền tảng đầu cuối NVIDIA NeMo dành cho phát triển GenAI tùy chỉnh
Hình 1. Các dịch vụ nền tảng đầu cuối NVIDIA NeMo dành cho phát triển GenAI tùy chỉnh
Là một phần của microservice NVIDIA CUDA-X, những endpoint API NeMo được xây dựng dựa trên các thư viện của NVIDIA, cung cấp một lộ trình dễ dàng cho các doanh nghiệp bắt đầu xây dựng GenAI tùy chỉnh.
Phát triển microservice cho GenAI tùy chỉnh
Trong chương trình truy cập sớm, các nhà phát triển có thể yêu cầu quyền truy cập vào các microservice NeMo Curator, NeMo Customizer và NeMo Evaluator. Cùng với nhau, những microservice này cho phép các tổ chức xây dựng GenAI tùy chỉnh cấp doanh nghiệp và đưa các giải pháp ra thị trường nhanh hơn.
Microservice NeMo Curator hỗ trợ các nhà phát triển trong quản lý dữ liệu để đào tạo trước và tinh chỉnh LLM (Mô hình ngôn ngữ lớn), trong khi NeMo Customizer cho phép tinh chỉnh và căn chỉnh. Cuối cùng, với NeMo Evaluator, các nhà phát triển có thể đánh giá các mô hình này dựa trên các điểm chuẩn học thuật hoặc tuỳ chỉnh và xác định các lĩnh vực cần cải thiện.
Hãy cùng khám phá chi tiết các microservice này.
NeMo Curator
NeMo Curator là một microservice quản lý dữ liệu được tăng tốc bởi GPU và có khả năng mở rộng, giúp chuẩn bị các bộ dữ liệu chất lượng cao cho việc đào tạo trước và tùy chỉnh các mô hình GenAI. Curator chuẩn hoá các tác vụ quản lý dữ liệu như tải xuống dữ liệu, trích xuất văn bản, dọn dẹp, lọc chất lượng, chống trùng lặp exact/fuzzy và khử nhiễm tác vụ downstream đa ngôn ngữ.
Curator hỗ trợ như sau:
- Các kỹ thuật tinh chỉnh, chẳng hạn như supervised fine-tuning (SFT), P-tuning và low-rank adaptation (LoRA).
- Quy trình chú thích dữ liệu nhanh hơn hỗ trợ các loại trình phân loại metadata khác nhau, bao gồm:
- Trình phân loại lĩnh vực khác nhau như chăm sóc sức khỏe, luật, v.v. Nhà phát triển có thể sử dụng dữ liệu phù hợp nhất để tùy chỉnh theo từng lĩnh vực cụ thể nhằm phát triển mô hình, kết hợp dữ liệu và làm phong phú dữ liệu thô.
- Phát hiện thông tin nhận dạng cá nhân (PII) để biên tập hoặc loại bỏ thông tin PII trên quy mô lớn khỏi dữ liệu đào tạo và tuân thủ quyền riêng tư dữ liệu.
- Các bộ lọc để nhận dạng và xóa dữ liệu độc hại hoặc không liên quan bằng các bộ lọc và danh mục tùy chỉnh được xác định.
NeMo Customizer
NeMo Customizer là một microservice có khả năng mở rộng, hiệu suất cao, giúp đơn giản hóa việc tinh chỉnh và căn chỉnh LLM cho các trường hợp sử dụng theo lĩnh vực cụ thể. Ban đầu, microservice hỗ trợ 2 kỹ thuật tinh chỉnh hiệu quả tham số (PEFT) phổ biến: LoRA và P-tuning.
Ngoài ra, microservice NeMo Customizer sẽ bổ sung hỗ trợ cho các kỹ thuật căn chỉnh đầy đủ trong tương lai:
- SFT
- Reinforcement learning from human feedback (RLHF)
- Direct preference optimization (DPO)
- NVIDIA NeMo SteerLM
Microservice NeMo Customizer hỗ trợ Kubernetes với quyền truy cập vào hệ thống tệp giống như NFS và bộ lập lịch volcano để triển khai. Điều này mang đến khả năng lập lịch hàng loạt, thường được yêu cầu để tinh chỉnh các LLM đa node hiệu suất cao.
NeMo Evaluator
Việc tùy chỉnh LLM cho các nhiệm vụ cụ thể có thể gây ra tình trạng catastrophic forgetting, một vấn đề khiến mô hình quên các nhiệm vụ đã học trước đó. Các doanh nghiệp sử dụng LLM phải đánh giá hiệu suất trên cả nhiệm vụ ban đầu và nhiệm vụ mới, liên tục tối ưu hóa mô hình để cải thiện trải nghiệm. NeMo Evaluator cung cấp đánh giá tự động về các mô hình GenAI tùy chỉnh trên các điểm benchmark học thuật và tùy chỉnh đa dạng trên bất kỳ trung tâm dữ liệu hoặc đám mây nào.
Nó hỗ trợ đánh giá tự động thông qua một tập hợp các điểm chuẩn học thuật được chọn lọc. Hỗ trợ đánh giá trên các bộ dữ liệu tùy chỉnh, NeMo Evaluator cung cấp các số liệu như độ chính xác, nghiên cứu cơ bản theo định hướng hồi tưởng để đánh giá ý chính (ROUGE), F1 và đối sánh chính xác.
Nó cũng cho phép sử dụng LLM như là một thẩm phán để đánh giá toàn diện các phản hồi của mô hình. Nó có thể tận dụng mọi LLM hỗ trợ NVIDIA NIM có sẵn trong danh mục NVIDIA API để đánh giá phản hồi của mô hình trên bộ dữ liệu MT-Bench.
Dễ dàng xây dựng GenAI tùy chỉnh
Các microservice NeMo cung cấp đầy đủ lợi ích của nền tảng NeMo, chẳng hạn như hiệu suất tăng tốc và khả năng mở rộng. Các nhà phát triển có thể đạt được hiệu suất đào tạo nhanh hơn bằng cách tận dụng các kỹ thuật song song và mở rộng quy mô sang nhiều GPU và nhiều node khi cần.
Microservice cũng mang lại cho doanh nghiệp những lợi ích như khả năng chạy trên hạ tầng ưa thích của họ, từ tại chỗ đến đám mây, cho phép họ kiểm soát bảo mật dữ liệu, tránh sự ràng buộc của nhà cung cấp và giảm chi phí.
Bất kể những lựa chọn cụ thể nào trong ngăn xếp phát triển, microservice đều mang lại khả năng thích ứng và tương thích. Chúng có thể được tích hợp vào quy trình công việc hiện tại dưới dạng API một cách dễ dàng mà không cần quan tâm đến các công nghệ cụ thể đang được sử dụng.
Đăng ký để truy cập sớm
Đăng ký quyền truy cập sớm vào NeMo microservices. Các đơn đăng ký được xem xét theo từng trường hợp và liên kết để truy cập vào microservice container sẽ được gửi cho những người tham gia đã được phê duyệt.
NVIDIA Developer
Bài viết liên quan
- Từ “Sáng tạo” Đến “Hành động”: Khám phá sự khác biệt giữa Generative AI và Agentic AI
- Mở rộng quy mô cho hạ tầng GenAI on-premise
- Sovereign AI là gì?
- LLM: Lịch sử và tương lai của các mô hình ngôn ngữ lớn
- LM Studio – Chạy Generative AI trên máy tính của riêng bạn
- Hướng đến tương lai: Generative AI dành cho các giám đốc điều hành