
Siêu chip NVIDIA GH200, GPU H100, L4 và các module Jetson Orin cho thấy hiệu suất vượt trội khi chạy AI ở môi trường sản xuất, từ đám mây đến rìa mạng.
Trong lần kiểm tra đầu tiên trên điểm benchmark chuyên ngành MLPerf, NVIDIA GH200 Grace Hopper Superchip đã chạy tất cả các bài test suy luận dành cho trung tâm dữ liệu, nới rộng hiệu suất dẫn đầu của các GPU NVIDIA H100 Tensor Core.
Kết quả tổng thể cho thấy hiệu suất vượt trội và tính linh hoạt của nền tảng NVIDIA AI từ đám mây đến rìa mạng.
Cùng lúc đó, NVIDIA công bố bộ phần mềm suy luận sẽ mang lại cho người dùng những bước nhảy vọt về hiệu suất, hiệu quả sử dụng năng lượng và tổng chi phí sở hữu.
GH200 Superchip tỏa sáng trong các bài kiểm tra MLPerf
GH200 liên kết 1 GPU Hopper với 1 CPU Grace trong một con “siêu chip”. Sự kết hợp này mang lại nhiều bộ nhớ, băng thông hơn và khả năng tự động chuyển đổi sức mạnh giữa CPU và GPU nhằm tối ưu hóa hiệu suất.
Các hệ thống NVIDIA HGX H100 đóng gói 8 GPU H100 đã mang lại thông lượng cao nhất trong mọi bài test suy luận MLPerf (MLPerf Inference) ở round này.
Các siêu chip Grace Hopper và GPU H100 đã dẫn đầu trong tất cả các bài test data center của MLPerf, bao gồm suy luận về thị giác máy tính (computer vision), nhận dạng giọng nói (speech recognition) và hình ảnh y khoa (medical imaging), bên cạnh các ứng dụng đòi hỏi khắt khe hơn về các hệ thống gợi ý (recommendation systems) và các mô hình ngôn ngữ lớn (LLMs) được sử dụng trong Generative AI.
Nhìn chung, những kết quả này tiếp nối các kỷ lục của NVIDIA, thể hiện sự dẫn đầu về hiệu suất trong đào tạo và suy luận AI trong mọi round kể từ khi ra mắt các điểm benchmark MLPerf vào năm 2018.
Round MLPerf mới nhất bao gồm một bài test đã được cập nhật về hệ thống gợi ý, cũng như điểm benchmark suy luận đầu tiên trên GPT-J, một LLM với 6 tỷ tham số, thước đo sơ bộ về kích thước của mô hình AI.
TensorRT-LLM tăng tốc suy luận
Để cắt giảm các workload phức tạp ở mọi quy mô, NVIDIA đã phát triển TensorRT-LLM, phần mềm Generative AI giúp tối ưu hóa khả năng suy luận. Thư viện nguồn mở – chưa sẵn sàng để kịp gửi tới MLPerf vào tháng 8 – cho phép khách hàng tăng hơn gấp đôi hiệu suất suy luận của các GPU H100 đã mua của họ mà không phải trả thêm phí.
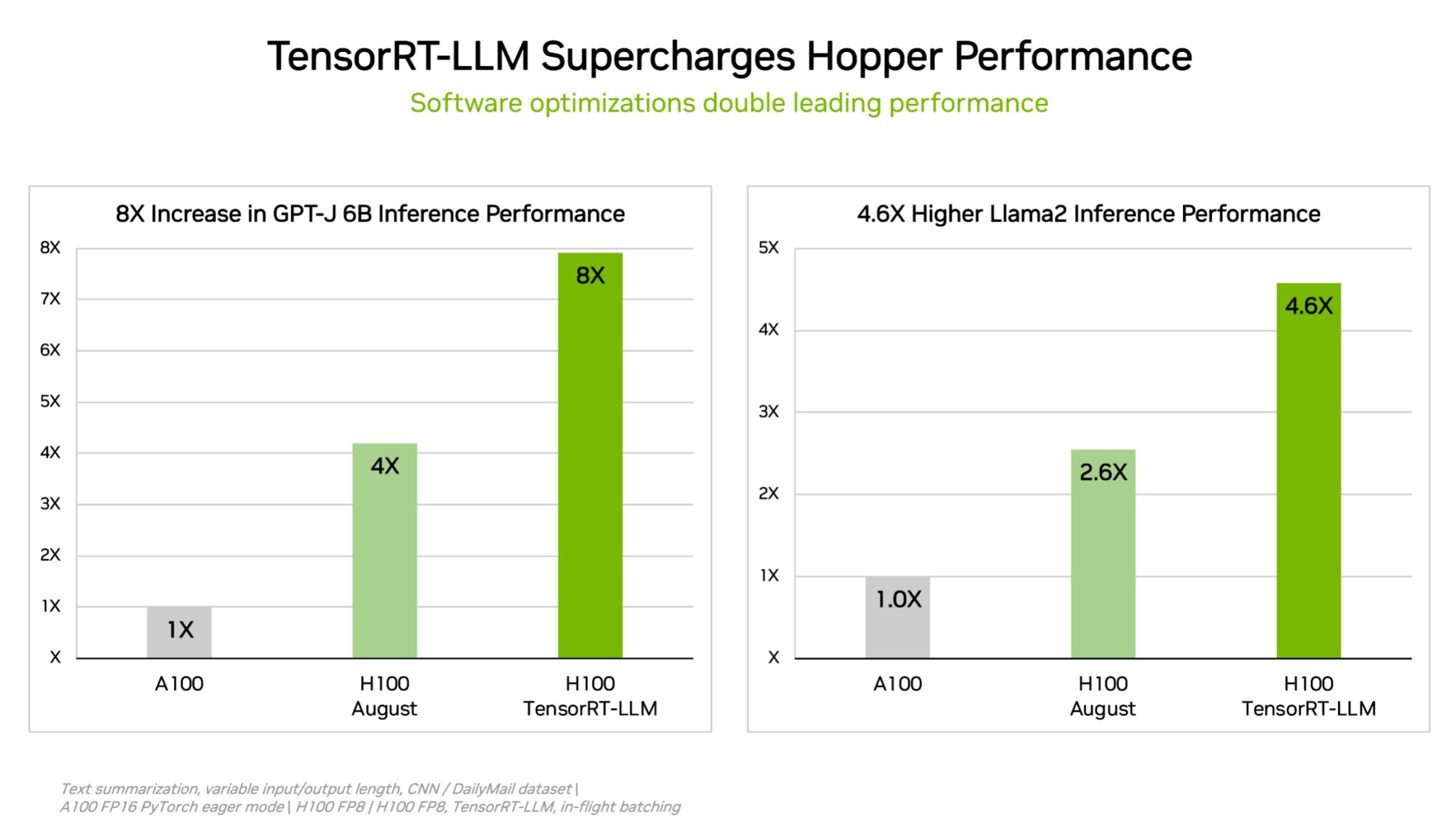
Các bài test nội bộ của NVIDIA cho thấy rằng việc sử dụng TensorRT-LLM trên các GPU H100 mang lại hiệu suất tăng tốc gấp 8 lần so với các GPU thế hệ trước chạy GPT-J 6B mà không cần phần mềm.
Phần mềm này bắt đầu trong việc tăng tốc công việc và tối ưu hóa suy luận LLM của NVIDIA với các công ty hàng đầu bao gồm Meta, AnyScale, Cohere, Deci, Grammarly, Mistral AI, MosaicML (hiện là một phần của Databricks), OctoML, Tabnine và Together AI.
MosaicML đã thêm các tính năng cần thiết lên trên TensorRT-LLM và tích hợp chúng vào stack phục vụ (serving) hiện có.
Naveen Rao, Phó chủ tịch kỹ thuật tại Databricks cho biết: “TensorRT-LLM dễ sử dụng, có nhiều tính năng và hiệu quả. Nó mang lại hiệu suất tiên tiến cho việc phục vụ LLM bằng cách sử dụng các NVIDIA GPU và cho phép chúng tôi mang lại chi phí tiết kiệm cho khách hàng của mình.”
TensorRT-LLM là ví dụ mới nhất về sự đổi mới liên tục trên nền tảng AI toàn diện của NVIDIA. Những tiến bộ phần mềm liên tục này mang lại cho người dùng hiệu suất tăng dần theo thời gian mà không mất thêm chi phí và linh hoạt trên các workload AI đa dạng.
GPU L4 tăng cường suy luận trên các máy chủ phổ thông
Trong các điểm benchmark MLPerf mới nhất, GPU NVIDIA L4 đã chạy được đầy đủ các workload và mang lại hiệu năng tuyệt vời trên mọi phương diện.
Ví dụ: GPU L4 chạy ở dạng bộ tăng tốc PCIe 72W nhỏ gọn mang lại hiệu suất cao hơn tới 6 lần so với CPU được đánh giá là có mức tiêu thụ điện năng cao hơn gần 5 lần.
Ngoài ra, GPU L4 còn có các media engine chuyên dụng, kết hợp với phần mềm CUDA, mang lại tốc độ tăng tốc lên tới 120 lần cho thị giác máy tính trong các thử nghiệm của NVIDIA.
GPU L4 có sẵn từ Google Cloud và nhiều nhà xây dựng hệ thống, phục vụ khách hàng trong các ngành từ dịch vụ Internet tiêu dùng cho đến nghiên cứu và phát triển thuốc.
Tăng cường hiệu suất tại biên
NVIDIA đã áp dụng một công nghệ nén mô hình mới để chứng minh hiệu suất tăng lên tới 4.7 lần khi chạy BERT LLM trên GPU L4. Kết quả là cái gọi là “open division” của MLPerf, một danh mục thể hiện các khả năng mới.
Kỹ thuật này dự kiến sẽ được sử dụng trên tất cả các workload AI. Nó có thể đặc biệt có giá trị khi chạy các mô hình trên các thiết bị biên (edge) bị hạn chế bởi kích thước và mức tiêu thụ điện năng.
Trong một ví dụ khác về sự dẫn đầu trong lĩnh vực điện toán biên, system-on-module NVIDIA Jetson Orin cho thấy hiệu suất tăng tới 84% so với round trước trong phát hiện đối tượng (object detection), một ứng dụng thị giác máy tính phổ biến trong các kịch bản robot và edge AI.
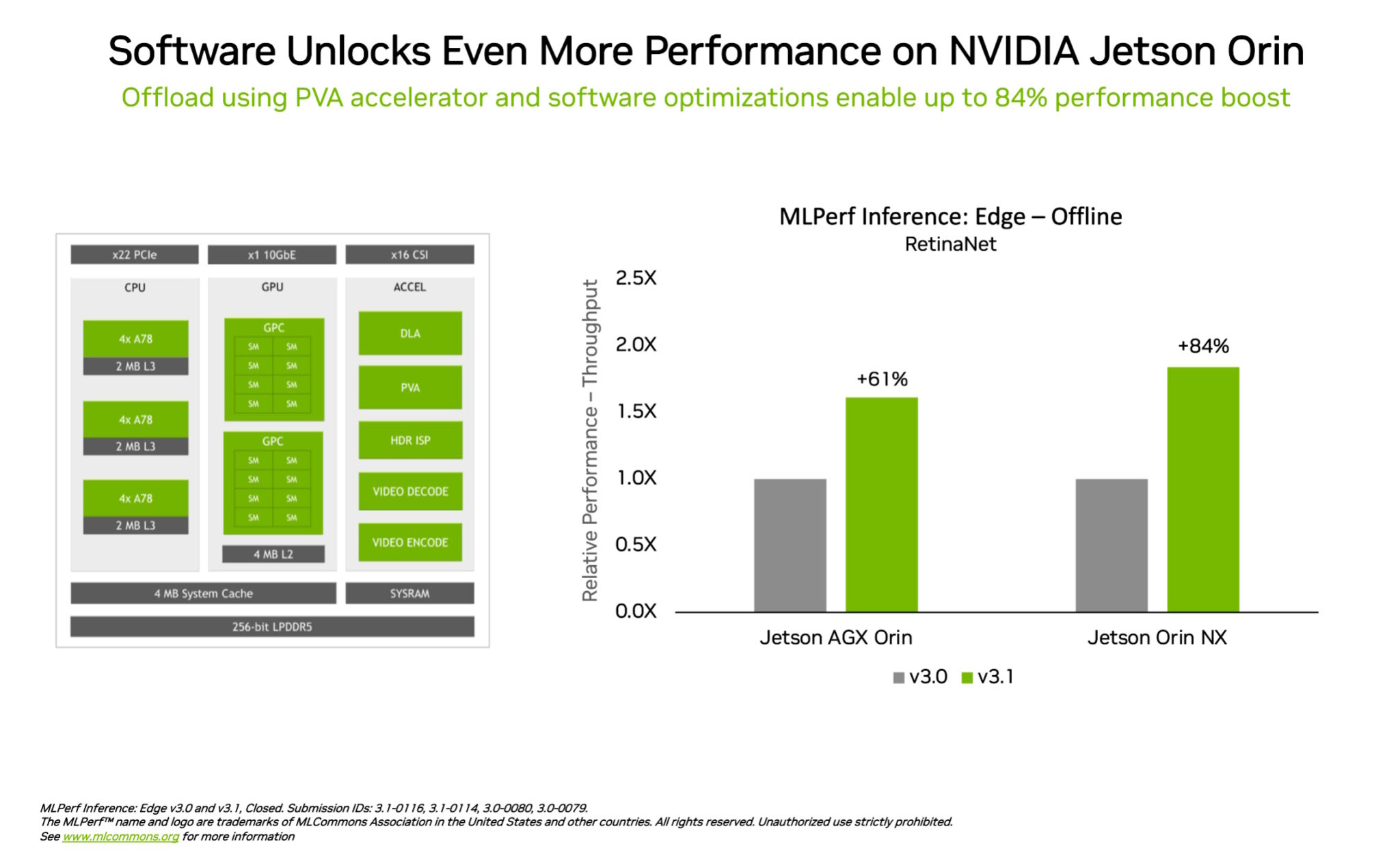
Sự tiến bộ của Jetson Orin đến từ phần mềm tận dụng phiên bản mới nhất của lõi chip, chẳng hạn như một bộ tăng tốc thị giác có thể lập trình, một GPU kiến trúc NVIDIA Ampere và một bộ tăng tốc học sâu chuyên dụng.
Hiệu suất linh hoạt, hệ sinh thái rộng lớn
Điểm benchmark MLPerf rất minh bạch và khách quan, vì vậy người dùng có thể dựa vào kết quả của họ để đưa ra quyết định mua hàng sáng suốt. Chúng cũng bao gồm nhiều trường hợp và tình huống sử dụng khác nhau, vì vậy người dùng biết rằng họ có thể có được hiệu suất vừa đáng tin cậy, vừa linh hoạt để triển khai.
Các đối tác tham gia round này bao gồm các nhà cung cấp dịch vụ đám mây Microsoft Azure và Oracle Cloud Infrastructure và các nhà sản xuất hệ thống ASUS, Connect Tech, Dell Technologies, Fujitsu, GIGABYTE, Hewlett Packard Enterprise, Lenovo, QCT và Supermicro.
Nhìn chung, MLPerf được hỗ trợ bởi hơn 70 tổ chức, bao gồm Alibaba, Arm, Cisco, Google, Đại học Harvard, Intel, Meta, Microsoft và Đại học Toronto.
Đọc blog kỹ thuật để biết thêm chi tiết về cách NVIDIA đạt được những kết quả mới nhất.
Tất cả phần mềm được sử dụng trong các điểm benchmark của NVIDIA đều có sẵn từ kho lưu trữ MLPerf, vì vậy mọi người đều có thể nhận được kết quả đẳng cấp thế giới như nhau. Sự tối ưu hóa liên tục được đưa vào các container có sẵn trên hub phần mềm NVIDIA NGC dành cho các ứng dụng GPU.
Theo NVIDIA Blog
Bài viết liên quan
- Từ “Sáng tạo” Đến “Hành động”: Khám phá sự khác biệt giữa Generative AI và Agentic AI
- Mở rộng quy mô cho hạ tầng GenAI on-premise
- NVIDIA Dynamo – Thư viện nguồn mở tăng tốc và mở rộng các mô hình lý luận AI
- Sovereign AI là gì?
- Những lợi ích của việc chạy suy luận AI ngay tại biên, thay vì trong trung tâm dữ liệu
- LLM: Lịch sử và tương lai của các mô hình ngôn ngữ lớn