
Tìm hiểu cách di chuyển dữ liệu giữa các phương tiện lưu trữ trực tuyến đa dạng và khám phá hai kỹ thuật phổ biến: Automated Data Tiering và Automated Data Placement (phân tầng dữ liệu và sắp đặt dữ liệu tự động).
Việc xác định dữ liệu nào được đặt trên bộ lưu trữ nào là một thách thức lớn mà các quản trị viên lưu trữ phải đối mặt hàng ngày. Không phải tất cả các phương tiện lưu trữ đều giống nhau. Chúng có thể thay đổi theo hiệu suất, chi phí, mức độ tuân thủ, triển khai, vị trí, v.v. và chắc chắn không phải tất cả dữ liệu đều quan trọng như nhau. Một số là dữ liệu nóng được truy cập rất thường xuyên, một số là dữ liệu được truy cập không thường xuyên và một số chỉ là bản sao dữ liệu dự phòng để khôi phục sau thảm họa và chỉ được truy cập trong trường hợp bị gián đoạn và mất dữ liệu. Cần phải nhấn mạnh rằng tầm quan trọng của dữ liệu cũng như nhiệt độ dữ liệu thay đổi theo thời gian. Ví dụ: dữ liệu nóng được lưu trữ trên ổ cứng HDD nhanh có thể được truy cập thường xuyên bởi một ứng dụng nhất định và có thể muốn được coi là nóng và chuyển sang ổ SSD nhanh hơn.

Người quản lý bộ nhớ có trách nhiệm tìm ra dữ liệu nào sẽ đi đến đâu. Với tốc độ và khối lượng dữ liệu được xử lý, việc thực hiện điều này theo cách thủ công và trong thời gian thực là không thể. Đây là nơi hỗ trợ tự động hóa chuyển động dữ liệu.
Phần mềm quản lý lưu trữ dữ liệu – những phần mềm được tích hợp sẵn trong phần cứng lưu trữ và những phần mềm có sẵn từ các nhà cung cấp giải pháp bên thứ ba – cung cấp phương tiện để tự động di chuyển dữ liệu sang cấp lưu trữ thích hợp. Và điều này diễn ra hoàn toàn minh bạch đối với ứng dụng và người dùng truy cập dữ liệu, không có bất kỳ ảnh hưởng nào đến tính liên tục của hoạt động.

Trong blog này, chúng ta sẽ so sánh và đối chiếu hai kỹ thuật – phân tầng dữ liệu và sắp xếp dữ liệu – giống nhau về nguyên tắc, nhưng khác nhau về cách chúng hoạt động. Hãy đi sâu vào ngay.
Phân tầng dữ liệu tự động
Phân tầng dữ liệu tự động (automated storage tiering, auto tiering) là một kỹ thuật được sử dụng rộng rãi trong thế giới lưu trữ khối, nơi phần mềm điều khiển chuyển động dữ liệu sử dụng học máy để theo dõi các mẫu truy cập và hiểu nhiệt độ dữ liệu. Khoa học về phân tầng dữ liệu tập trung vào việc giám sát hành vi I / O, xác định tần suất sử dụng, sau đó di chuyển động các khối thông tin đến lớp hoặc cấp phương tiện lưu trữ phù hợp nhất. Dựa trên tần suất nóng, ấm hoặc lạnh, dữ liệu sẽ được đặt trên các tầng lưu trữ tương ứng. Thông thường, quản trị viên lưu trữ xác định các cấp lưu trữ – cấp 1, 2, 3, v.v. Sau đó, phần mềm thực hiện phần còn lại.
Phân cấp dữ liệu có thể hoạt động trong một thiết bị lưu trữ duy nhất với các cấp khác nhau được phân biệt trong chính nó hoặc trên các thiết bị của cùng một nhà sản xuất hoặc từ các nhà sản xuất khác nhau. Toàn bộ tiềm năng của nó có thể được thực hiện khi không có nhà cung cấp hoặc thiết bị ràng buộc và việc phân cấp được thực hiện trên bất kỳ hệ thống lưu trữ nào.
Hãy xem xét một môi trường có sự kết hợp của các mảng flash SSD cao cấp, hệ thống lưu trữ HDD và JBOD. Bạn sẽ không muốn lãng phí không gian trên mảng flash cao cấp với dữ liệu lạnh hiếm khi được truy cập và để thiết bị liên tục đói với dung lượng nhiều hơn, điều này vừa không thông minh vừa không tiết kiệm chi phí. Phân cấp dữ liệu cho phép di chuyển dữ liệu tự động để bộ lưu trữ hiệu suất cao và đắt tiền (cấp 1) lưu trữ dữ liệu nóng nhất và các cấp khác (ít hơn trong các số cấp được chỉ định) nhận được dữ liệu ấm và lạnh.
Sự di chuyển này không chỉ xảy ra khi dữ liệu mới được ghi vào đĩa. Ngay cả khi dữ liệu hiện có đang được truy cập và tần số thay đổi, phần mềm quản lý lưu trữ dữ liệu sẽ nhận dạng một cách thông minh mẫu và chuyển nó đến tầng lưu trữ tương ứng. Việc di chuyển dữ liệu diễn ra liên tục, tự động và hoàn toàn minh bạch đối với ứng dụng ở giao diện người dùng.
Tại DataCore, chúng tôi đã kết hợp phân cấp dữ liệu tự động vào giải pháp lưu trữ dựa trên phần mềm được xác định dựa trên khối của chúng tôi, SANsymphony , sử dụng ảo hóa lưu trữcông nghệ để trừu tượng hóa dung lượng lưu trữ từ phần cứng lưu trữ và tạo các hồ bơi ảo. Trong một nhóm lưu trữ, các cấp lưu trữ có thể được đặc trưng và SANsymphony thực hiện phân cấp dữ liệu trong thời gian thực cho phép bạn tận dụng tối đa dung lượng trên phần cứng hiệu quả của mình để lưu trữ dữ liệu quan trọng / nóng. SANsymphony thúc đẩy các khối được sử dụng thường xuyên nhất lên cấp nhanh nhất, trong khi các khối lưu trữ ít được sử dụng nhất sẽ bị hạ cấp xuống cấp chậm nhất. Điều này cũng mang lại cho bạn lợi ích để tích hợp các công nghệ mới vào cơ sở hạ tầng lưu trữ của bạn một cách liền mạch. Ví dụ: nếu bạn đang thêm một số đĩa lưu trữ dựa trên 3D XPoint, SANsymphony có thể thêm bộ nhớ đó vào nhóm lưu trữ ảo của mình mà không bị gián đoạn và biến nó thành bộ nhớ cấp 1 của bạn, nơi tất cả dữ liệu nóng của bạn sẽ tự động được nâng cấp lên.siêu tập trung ).

Cách DataCore SANsymphony thực hiện phân cấp dữ liệu tự động
Vị trí Dữ liệu Tự động
Trong thế giới dữ liệu phi cấu trúc , nơi tốc độ tăng trưởng dữ liệu lớn hơn nhiều so với dữ liệu có cấu trúc, lưu trữ tệp thường được sử dụng như một phương tiện lưu trữ ưa thích. Các tổ chức CNTT yêu cầu sự linh hoạt để di chuyển dữ liệu qua lại giữa các hệ thống lưu trữ tệp như NAS, máy chủ tệp, v.v. – và cả với bộ lưu trữ đối tượng khi cần – dựa trên yêu cầu của họ.
Điều này có thể thực hiện được với vị trí dữ liệu tự động, một biến thể của phân cấp dữ liệu tự động, nhưng vượt xa điều này trong việc đáp ứng các tiêu chí khác nhau về di chuyển dữ liệu. Ở đây, phần mềm quản lý lưu trữ dữ liệu thường là một hệ thống tệp toàn cầu nằm phía trên lớp lưu trữ. Tận dụng công nghệ ảo hóa tệp, hệ thống tệp toàn cầu trước tiên tập hợp siêu dữ liệu từ trọng tải dữ liệu được lưu trữ trên các hệ thống lưu trữ khác nhau (máy chủ tệp, NAS, đám mây, v.v.). Sau đó, nó đồng hóa các tệp, bao gồm cả thông tin siêu dữ liệu của chúng, vào không gian tên chung của nó .
Giờ đây, hệ thống tệp toàn cầu biết thông tin chi tiết về tệp nào được lưu trữ ở đâu, loại tệp nào, thời điểm chúng được tạo và truy cập lần cuối, kích thước của chúng là bao nhiêu, người dùng nào đã tạo tệp, v.v. và việc sử dụng dung lượng của bộ nhớ các hệ thống. Thông tin thu thập về dữ liệu lớn hơn nhiều so với trường hợp lưu trữ khối. Vì vậy, hiện có nhiều tùy chọn hơn để tùy chỉnh các tiêu chí dựa trên dữ liệu nào có thể được di chuyển giữa các phương tiện lưu trữ. Tần suất truy cập dữ liệu (hoặc nhiệt độ dữ liệu) thực sự là một trong số đó. Nhưng có thể có nhiều chính sách riêng khác mà người quản trị có thể tạo ra để điều chỉnh sự di chuyển của dữ liệu. Do đó, vị trí dữ liệu có khả năng ứng dụng cao hơn so với phân cấp dữ liệu.
Dưới đây là một số ví dụ để hiểu rõ hơn:
- Độ bền và bảo vệ dữ liệu: Tạo bản sao dữ liệu được lưu trữ trên một phần chia sẻ nhất định và di chuyển nó đến nhiều vị trí để sao lưu.
- Hiệu suất: Giảm tải dữ liệu được lưu trữ trên các thiết bị NAS cao cấp xuống đĩa chậm hơn và bộ nhớ rẻ hơn. Điều này giúp giải phóng dung lượng trên bộ nhớ chính của bạn và giảm thiểu tắc nghẽn I / O.
- Tuân thủ: Các chính sách tuân thủ quy định có thể yêu cầu các tổ chức lưu giữ dữ liệu ở một vị trí cụ thể trong một khoảng thời gian nhất định trước khi di chuyển hoặc xóa dữ liệu. Ví dụ: lưu trữ dữ liệu khách hàng trong một quốc gia hoặc trong một trang web cụ thể để đáp ứng các yêu cầu về tuân thủ và bảo mật.
- Giảm tải cho lưu trữ đối tượng: Đối với các tổ chức tập trung vào việc tận dụng lưu trữ đối tượng như một giải pháp thay thế chi phí thấp cho lưu trữ tệp, họ có thể sử dụng vị trí dữ liệu tự động và di chuyển dữ liệu không hoạt động / lạnh sang lưu trữ đối tượng tại chỗ hoặc trong đám mây.
- Mục tiêu kinh doanh tùy chỉnh: Di chuyển tất cả các tệp ảnh chụp nhanh lên đám mây; di chuyển tất cả dữ liệu từ bộ phận nhân sự nhận phần cứng lưu trữ cụ thể được lưu trữ sang bộ nhớ thứ cấp ; khi đạt đến giới hạn dung lượng trên một dung lượng lưu trữ cụ thể, hãy di chuyển tất cả dữ liệu mới sang một dung lượng lưu trữ khác (điều này giúp cân bằng tải trên các hệ thống lưu trữ); và hơn thế nữa.
Để thực hiện việc sắp xếp dữ liệu tự động trên bộ lưu trữ đối tượng và tệp phân tán, DataCore cung cấp vFilO , một giải pháp lưu trữ do phần mềm xác định, hoạt động như một hệ thống tệp toàn cầu và quản lý việc di chuyển dữ liệu dựa trên các chính sách tùy chỉnh do quản trị viên lưu trữ thiết lập. vFilO sử dụng máy học để phát hiện các mẫu khi dữ liệu được ghi vào bộ nhớ và sau đó thực hiện việc sắp xếp dữ liệu dựa trên các chính sách này. Sử dụng vFilO cho phép bạn tổng hợp các không gian tên trên các thiết bị NAS và trình tập tin khác nhau thành một không gian tên toàn cầu duy nhất và hợp lý hóa tính di động của dữ liệu như bạn mong muốn.

Vị trí dữ liệu tự động giữa lưu trữ tệp tại chỗ và lưu trữ đối tượng đám mây
Cũng giống như trong phân cấp dữ liệu, ở đây quá trình di chuyển dữ liệu cũng diễn ra linh hoạt và hoàn toàn minh bạch đối với ứng dụng và người dùng trong giao diện người dùng. Với tùy chọn di chuyển dữ liệu lên đám mây và giữa các nền tảng đám mây công cộng khác nhau, vFilO cũng có thể hỗ trợ bạn trên hành trình đám mây và tận dụng các tùy chọn tiết kiệm để lưu trữ dữ liệu.
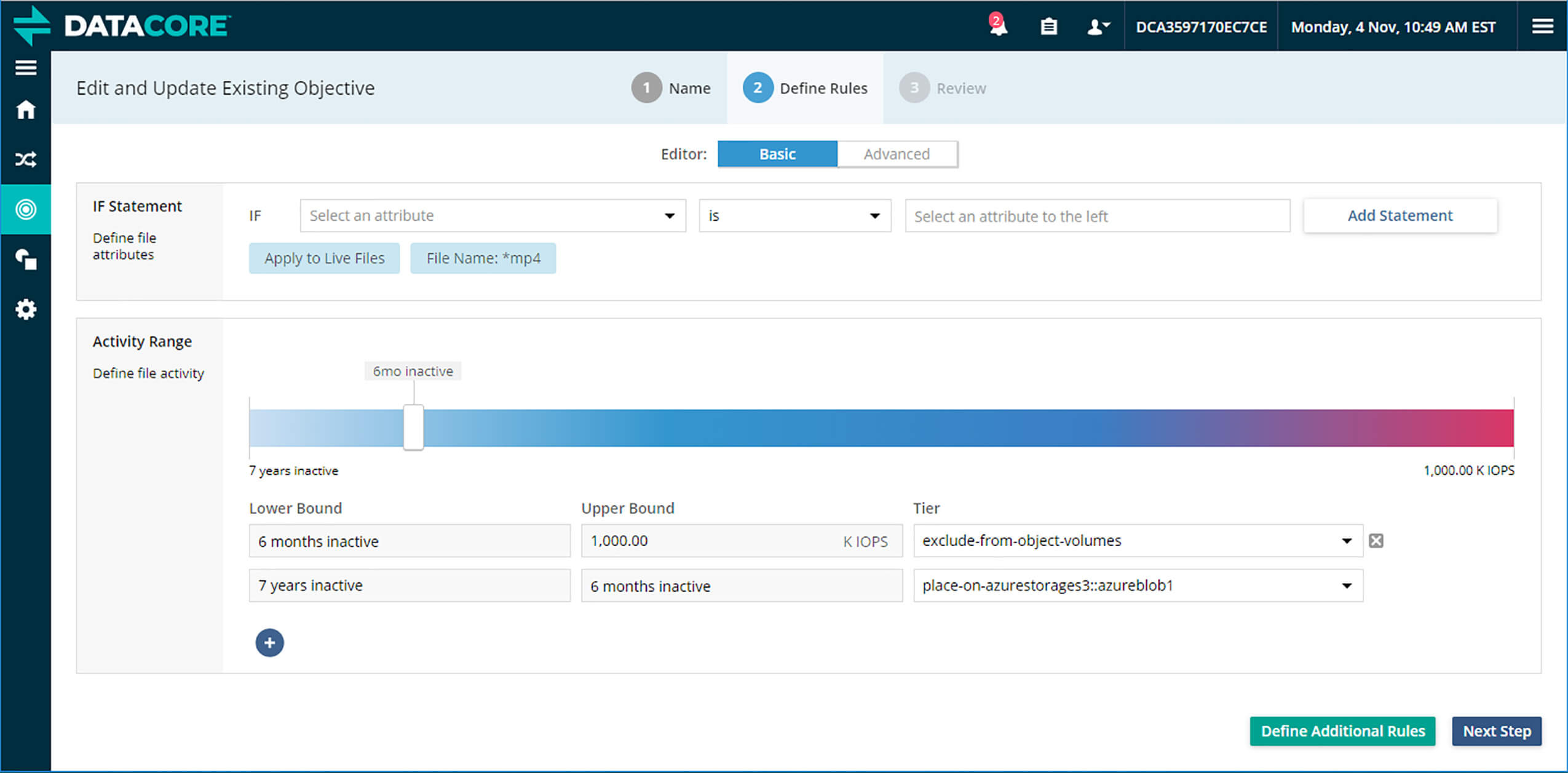
Tùy chỉnh các chính sách và mục tiêu trong DataCore vFilO để điều chỉnh chuyển động của dữ liệu
Phần kết luận
Mặc dù các chuyên gia CNTT thường sử dụng các thuật ngữ phân cấp dữ liệu và vị trí dữ liệu thay thế cho nhau, nhưng theo quan điểm của DataCore, chúng tôi coi chúng như hai kỹ thuật riêng biệt trong đó phân cấp dữ liệu tập trung vào chuyển động của dữ liệu dựa trên nhiệt độ dữ liệu và vị trí dữ liệu sử dụng các chính sách tùy chỉnh để kiểm soát di chuyển dữ liệu dựa trên các yêu cầu kinh doanh (cũng bao gồm nhiệt độ dữ liệu là một trong các tùy chọn). Bạn có thể kiểm tra SANsymphony và / hoặc vFilO dựa trên môi trường lưu trữ của bạn được tạo thành từ gì (khối, tệp hoặc đối tượng) và loại dữ liệu bạn đang xử lý (có cấu trúc hoặc không có cấu trúc).
DataCore đã có mặt trên thị trường hơn 10 năm và hiện được nhà phân phối Hạ Tầng Mới – CSC cung cấp tại thị trường Việt Nam.
![]()
![]()
Bạn muốn trở thành đối tác bán hàng Datacore của NTC?
Bài viết liên quan
- Làm cách nào để cải thiện hiệu năng và dung lượng các tủ SAN, tối ưu và quản lý chúng chặt chẽ?
- HCI và những ưu điểm của hệ thống Siêu hội tụ
- Những sự thật trong lĩnh vực lưu trữ dữ liệu
- Tầm quan trọng của Analytics trong quản lý hệ thống lưu trữ dữ liệu
- Các xu hướng hàng đầu liên quan đến Software-defined Storage